|
UP:
4.4.3 Протокол TCP |
|
UP:
4.4.3 Протокол TCP |
4.4.3.1 Модели реализации протокола TCP и его перспективы
Семенов Ю.А. (ГНЦ ИТЭФ)
(обзор)
Как известно протокол TCP (описание протокола смотри, например, в [38]) ориентирован на соединение, он использует для транспортировки IP-дейтограммы (L3), которые пересылаются посредством протокольных кадров уровня L2. Между двумя партнерами может быть прямое соединение, а может располагаться большое число сетевых приборов уровней L2 и L3 (см. рис. 1). Если потоки входящих и выходящих сегментов для заданного сетевого устройства равны, режим стационарен и состояние его буферов не меняется. Но маршрутизаторы и переключатели обычно являются многоканальными устройствами. По этой причине, если даже партнеры ТСР-соединения рассчитаны на идентичную скорость обмена, возможна ситуация, когда некоторое сетевое устройство, вовлеченное в обмен, окажется перегруженным. Ведь всегда могут возникать и исчезать новые сессии информационного или мультимедийного обмена, использующие частично те же сетевые устройства. Протокол ТСР функционирует нормально при выполнении ряда условий.
Конечно, данные условия выполняются отнюдь не всегда, и система не рухнет, если эти условия нарушаются часто. Но эффективность работы соединения окажется не оптимальной. Примером ситуации, когда перечисленные условия нарушаются сразу по нескольким позициям, может служить мобильная IP-связь и работа через спутниковые каналы коммуникаций.
В тех случаях, когда поток данных расщепляется, должны предприниматься специальные меры по балансировке загрузки каналов.
Для прояснения модели работа протокола ТСР рассмотрим простой фрагмент сети, отображенный на рис. 1.
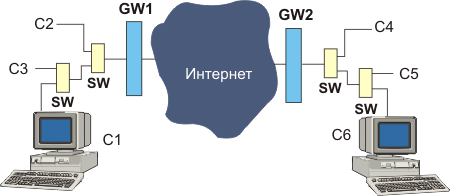
Рис. 1.
На данном рисунке ЭВМ С1-С3 могут осуществлять обмен друг с другом и с ЭВМ С4-С6. Переключатели SW работают на уровне L2 имеют буферы и могут быть причиной потерь также как сами ЭВМ и маршрутизаторы GW1-GW2. Понятно, что объектом перегрузки помимо названных устройств может стать любой сетевой объект сети Интернет. Если устройства L3 при переполнении своего буфера могут послать отправителю пакета уведомление ICMP(4), то SW в общем случае могут этого и не делать (например, потому что не умеют). Причиной потери может быть и повреждение пакета на безбрежных просторах Интернет. Особые проблемы могут порождать каналы с большим произведением полосы на RTT [3]. В основных версиях протокола ТСР для подавления перегрузки используется механизм окон, который управляется потерей пакетов. В современных сетях передача данных, которая создает стационарный трафик, сосуществует с мультимедиа трафиком, который по своей природе нестабилен, что создает дополнительные проблемы для управления с применением оконных алгоритмов. Кроме того, мультимедийный трафик транспортируется обычно протоколом UDP, не предполагающим подтверждений доставки. Именно дейтограммы UDP могут вызвать переполнение буфера и об этом станет известно отправителю ТСР позднее после регистрации потери сегмента.
| Пусть полоса равна 10 Гбит/c, RTT=120мсек, а пакеты имеют длину 1500 байт. Тогда время передачи пакета составит 1,2 мксек, и за время RTT будет передаваться 100000 пакетов. Этого достаточно, чтобы переполнить практически любой буфер. Время же реакции системы определяется RTT. Даже если в отклике передавать полные данные о состоянии всех буферов по пути, времени для своевременной реакции недостаточно. В этом заключается основная проблема реактивности, сопряженной с медленным стартом ТСР. |
Анализируя различные модели работы протокола ТСР, следует учитывать, что в сети Интернет могут встречаться участки с разными протоколами L2 (Ethernet, ATM, SDH, Frame Relay, PPP и т.д.). Эти технологии имеют разные алгоритмы обработки ситуаций перегрузки (или не иметь их вовсе), а отправитель и получатель, как правило, не имеют данных о том, какие протоколы уровня L2 реализуют виртуальное соединение (L4).
В настоящее время предложено и опробовано несколько разновидностей протокола TCP. Все они используют различные прогнозы поведения канала в будущем на основе данных, которыми располагает на данный момент отправитель.
TCP-reno
В TCP-reno [17, 1990г] при нормальной ситуации размер окна меняется циклически. Размер окна увеличивается до тех пор, пока не произойдет потеря сегмента. TCP-reno имеет две фазы изменения размера окна: фаза медленного старта и фаза избежания перегрузки. При получении отправителем подтверждения доставки в момент времени t + tA [сек], текущее значение размера окна перегрузки cwnd(t) преобразуется в cwnd(t + tA) согласно (1):
 (1)
(1)
где ssth(t) [пакетов] - значение порога, при котором TCP переходит из фазы медленного старта в фазу исключения перегрузки. Когда в результате таймаута детектируется потеря пакета значения cwnd(t) и ssth(t) обновляются следующим образом:
cwnd(t)=1; ssth(t)=(cwnd(t))/2;
С другой стороны, когда TCP детектирует потерю пакета согласно алгоритму быстрой повторной передачи, cwnd(t) и ssth(t) обновляются иначе:
ssth(t) = (cwnd(t))/2; cwnd(t)= ssth(t);
TCP-reno после этого переходит в фазу быстрого восстановления. В этой фазе размер окна увеличивается на один пакет, когда получается дублированное подтверждение. С другой стороны, cwnd(t) делается равным ssth(t), когда приходит не дублированный отклик для пакета, посланного повторно. В случае таймаута ssth(t)= (cwnd(t))/2; cwnd=1 (смотри описание алгоритма TCP-Tahoe).
Результаты моделирования показывают, что каждое соединение обычно теряет около двух пакетов в каждом эпизоде перегрузки. Потери случаются, когда буфер полон и одно соединение увеличивает размер окна на единицу. Когда ячейки из этого нового пакета приходит в буфер, они обычно вызывают потерю ячеек, принадлежащих двум пакетам (конец пакета, пришедшего из другого соединения, и начала следующего). Итак, в среднем следует ожидать потерю трех пакетов на одно столкновение. В нашем примере двух соединений с RTT 40 мсек и 80 мсек, раз буфер полон и произошло столкновение, эпизод перегрузки длится 40 мсек. За время этого периода 80 мсек соединение увеличивает свое окно грубо 50% времени. То есть среднее число потерянных пакетов из-за этого увеличивается в 1.5 раза. Следовательно, всего 4.5 пакетов, или 2.25 пакетов на соединение теряется в среднем на один эпизод перегрузки.
В настоящее время наиболее популярной является модель NewReno, изложенная в документе RFC-3782 (апрель 2004 года), и использующая алгоритм Fast Retransmit & Fast Recovery (быстрая повторная пересылка и быстрое восстановление). В случае, когда доступна опция выборочного подтверждения (SACK), отправитель знает, какие пакеты следует переслать повторно на фазе быстрого восстановления (Fast Recovery). В отсутствии опции SACK нет достаточной информации относительно пакетов, которые нужно послать повторно. При получении трех дублированных подтверждений (DUPACK) отправитель считает пакет потерянным и посылает его повторно. После этого отправитель может получить дополнительные дублированные подтверждения, так как получатель осуществляет подтверждение пакетов, которые находятся в пути, когда отправитель перешел в режим Fast Retransmit. В случае потери нескольких пакетов из одного окна отправитель получает новые данные, когда приходит подтверждение для повторно посланных пакетов. Если потерян один пакет и не было смены порядка пакетов, тогда подтверждение этого пакета будет означать успешную доставку всех предыдущих пакетов до перехода в режим Fast Retransmit. Однако, если потеряно несколько пакетов, тогда потверждение повторно посланного пакета подверждает доставку некоторых но не всех пакетов, посланных до перехода в режим быстрой повторной пересылки (Fast Retransmit). Такие подтверждения называются частичными (смотри также http://www.acm.org/sigcomm/sigcomm96/program.html).
Разработчики назвали алгоритм быстрого восстановления NewReno, так как он значительно отличается от базового алгоритма Reno, описанного в RFC-2581. Предложенный алгоритм дает определенные преимущества по ставнению с каноническим Reno при самых разных сценариях. Однако, при одном сценарии канонический Reno превосходит NewReno - это происходит при изменении порядка следования пакетов.
Алгоритм NewReno использует переменную recover (восстановление), исходное значение которой равно исходному порядковому номеру пакета. Рассмотрим узловые этапы реализации алгоритма.
1) Три задублированных ACK:
Когда отправителю приходят три задублированных ACK, а он не находится в состоянии Fast Recovery, проверяется, перекрывает ли поле Cumulative Acknowledgement больший диапазон, чем задано переменной recover. Если это так, то исполняется операция 1A. В противном случае 1B.
1A) Запуск Fast Retransmit:
Если система находится в этом режиме, ssthresh делается равным значению не более, чем задано уравнением 1. (Это уравнение 3 из [RFC2581]).
ssthresh = max (FlightSize / 2, 2×SMSS) (1)
Кроме того, переменная recover делается равной наибольшему порядковому номеру переданного пакета, и осуществляется переход к пункту 2.
1B) Без быстрой повторной передачи:
Не производится вход в режим быстрой повторной передачи и быстрого восстановления. В частности не изменяется ssthresh, не выполняется переход к пункту 2, чтобы передать потерянный сегмент, и не делается перехода к пункту 3 при последующих задублированных ACK.
2) Вход в режим быстрой повторной передачи:
Передается потерянный сегмент и устанавливается cwnd равным ssthresh плюс 3*SMSS (Sender Maximum Segment Size).
Это искусственно увеличивает окно перегрузки на несколько сегментов (три), которые покинули сеть и буферизованы получателем.
3) Быстрое восстановление:
Для каждого нового дублированного ACK, полученного в режиме быстрого восстановления, cwnd увеличивается на SMSS. Это искуственно увеличивает окно перегрузки, для того чтобы учесть сегмент, который покинул сеть.
4) Быстрое восстановление, продолжение:
Сегмент передается, если это разрешено новым значением cwnd и значением window, объявленным получателем.
5) Когда приходит ACK, подтверждающее получение новых данных, это ACK может быть подтверждением, связанным с повторной передачей во время этапа 2 или с более поздней повторной передачей.
Полное подтверждение:
Если ACK подтверждает все данные вплоть до позиции, указанной переменной recover, тогда ACK подтверждает получение промежуточных сегментов, начиная с передачи потерянного сегмента и получения тройного диблированного ACK. cwnd устанавливается либо (1) min (ssthresh, FlightSize + SMSS) либо (2) ssthresh, где ssthresh равно значению, установленному на этапе 1; это называется снижением ("сдутием") значения окна. Заметим, что FlightSize (FlightSize - объем посланных, но еще неподтвержденных данных) на этапе 1 относится к объему данных не доставленных на этапе 1, когда произошел переход в режим быстрого восстановления, в то время как FlightSize на этапе 5 относится к объему данных недоставленных на этапе 5, когда произошел выход из режима быстрого восстановления. Если выбрана вторая опция, реализации разрешено принять меры, чтобы избежать возможного всплеска информационного потока, в случае, когда объем недоставленных данных в сети много меньше, чем допускает окно перегрузки. Простым механизмом является ограничение числа информационных пакетов, которые могут быть посланы в ответ на одно подтверждение; это называется "maxburst_" в программе моделирования NS. Выход из режима быстрого восстановления.
Частичное подтверждение:
Если это ACK в действительности не подтверждает доставку всех данных вплоть до позиции, заданной recover включительно, тогда это частичное ACK. В этом случае передается первый неподтвержденный сегмент. Снижается значение окна перегрузки с учетом объема новых данных, подтвержденных с использованием поля группового подтверждения. Если частичное ACK подтверждает как минимум один SMSS данных, тогда к окну перегрузки добавляется SMSS байт. Так как на этапе 3, это искусственно увеличивает окно перегрузки, для того чтобы учесть сегмент, который покинул сеть. Посылается новый сегмент, если это разрешено новым значением cwnd. Это "частичное сокращение окна" пытается гарантировать то что, когда режим быстрого восстановления в конце концов завершится, объем недоставленных данных будет примерно равен ssthresh. Выхода из режима быстрого восстановления не производится (т.e., если позднее придет какой-либо задублированный ACK, выполняются шаги 3 и 4).
Для первого частичного ACK, который приходит во время реализации быстрого восстановления, сбрасывается таймер повторной передачи.
6) Таймауты повторной передачи:
После RTO в переменную recover записывается наибольший порядковый номер переданного сегмента и производится выход из режима быстрого восстановления, если это возможно.
Этап 1 специфицирует проверку того, что поле кумулятивного подтверждения покрывает больший диапазон, чем это задано переменной recover. Так как поле подтверждения содержит порядковый номер, который получатель ожидает получить, "ack_number" подтверждения покрывает больший диапазон номеров, чем recover когда:
ack_number - 1 > recover;
т.e., получено подтверждение по крайней мере на один байт данных больше, чем наибольший байт из недоставленных данных, с момента последнего входа в режим быстрой повторной отправки.
4. Сброс таймера повторной передачи в ответ на частичное подтверждение. Возможным вариантом реакции на частичные подтверждения может быть сброс таймера повторной передачи после частичного подтверждения. В этом случае, если в пределах окна потеряно большое число пакетов, таймер повторной передачи TCP-отправителя выдает таймаут, а отправитель данных запускает процедуру медленного старта.
Одной из возможностей получения более оптимального алгоритма в случае множественных потерь пакетов является схема, подобная медленному старту, когда осуществляется сброс таймера повторной посылки при каждом частичном подтверждении. Следует заметить, что существует определенное ограничение эффективности в случае отсутствия поддержки опции SACK.
5. Повторные передачи после частичного подтверждения
Возможным вариантом реакции на частичное подтверждение может быть повторная посылка более чем одного пакета, и сброс таймера повторной пересылки после повторной посылки. В случае множественных потерь пакетов повторная посылка двух пакетов при получении частичного подтверждения обеспечивает более быстрое восстановление системы. Такой подход требует меньше времени, чем N RTT в случае потери N пакетов. Однако при отсутствии опции SACK, медленный старт обеспечивает достаточно быстрое восстановление системы без пересылки лишних пакетов.
Этап 5 определяет, что TCP отправитель реагирует на частичные ACK сокращением окна перегрузки на величину, соответствующую объему подтвержденных данных, добавляя назад SMSS байт, если частичное ACK подтверждает по крайней мере SMSS байт новых данных, и, посылая новый сегмент, если это допускается новым значением cwnd. Таким образом, посылается только один посланный ранее пакет в ответ на каждое частичное подтверждение, но могут быть посланы и новые пакеты, в зависимости от объема подтвержденной частично доставки. Напротив, в варианте NewReno, описанном в (Fall, K. and S. Floyd, "Simulation-based Comparisons of Tahoe, Reno and SACK TCP", Computer Communication Review, July 1996. URL ftp://ftp.ee.lbl.gov/papers/sacks.ps.Z), в случае частичного подтверждения устанавливается значение окна перегрузки равным ssthresh. Такой подход является более консервативным, и не пытается точно определить число недоставленных пакетов после получения частичного подтверждения.
6. Исключение кратных быстрых повторных передач
В отсутствии опции SACK или временных меток, задублированные подтверждения не несут какой-либо информации, позволяющей идентифицировать информационные пакеты, которые вызвали задублированные подтверждения. В этом случае, отправитель TCP данных не может разделить задублированные подтверждения, вызванные потерей или задержкой пакетов, от задублированных ACK, связанных с повторно посланными информационными пакетами, уже полученными адресатом.
Проблемы оптимальности для алгоритмов быстрого восстановления и быстрой повторной пересылки в Reno TCP, связанные с множественными быстрыми повторными пересылками, относительно меньше по сравнению с аналогичными проблемами в случае алгоритма Tahoe TCP, который не использует быстрого восстановления. Несмотря ни на что ненужные быстрые повторные пересылки могут произойти в Reno TCP, если не использовать дополнительные механизмы связанные с применением переменной recover.
Алгоритм, описанный в RFC-3782, соответствует варианту Careful алгоритма NewReno TCP из RFC 2582, и исключает проблему множественных повторных пересылок. Этот алгоритм использует переменную recover, значение которой соответствует исходному порядковому номеру посланного пакета. После каждого таймаута повторной передачи, наибольший порядковый номер переданного пакета записывается в переменную recover.
Если после таймаута повторной передачи, отправитель TCP повторно пошлет пакеты, уже полученные адресатом, тогда отправитель получит три задублированных отклика, которые перекроют диапазон, заданный переменной recover. В этом случае задублированные ACK не указывают на случай перегрузки. Они просто сообщают, что отправитель повторно послал, по крайней мере, три пакета.
Однако, когда повторно посланные пакеты сами теряются, отправитель может получить три задублированные отклика, которые перекрывают меньший диапазон чем определяется переменной recover. Для протокола TCP, который использует рассмотренный здесь алгоритм, отправитель в данном сценарии не предполагает, что потерянный пакет сопряжен с одним из задублированных подтверждений.
Существует несколько эвристических подходов, основанных на временных метках или на преимуществах поля кумулятивных (групповых) подтверждений, которые отправитель в некоторых случаях использует, чтобы различить случаи с тремя задублированными ACK, следующие за повторно посланным пакетом, который был потерян, и тремя задублированными подтверждениями, сопряженными с откликами на повторно посланные по ошибке сегменты. Отправитель может использовать эвристику, чтобы решить следует ли запускать режим быстрой повторной передачи, даже если задублированные ACK не перекрывают диапазон номеров, определенный переменной recover.
TCP-Vegas [9, 1994г] контролирует размер окна путем мониторирования отправителем RTT для пакетов, посланных ранее. Если обнаруживается увеличение RTT, система узнает, что сеть приближается к перегрузке и сокращает ширину окна. Если RTT уменьшается, отправитель определит, что сеть преодолела перегрузку, и увеличит размер окна. Следовательно, размер окна в идеальной ситуации будет стремиться к требуемому значению. В частности на фазе исключения перегрузки, размер окна будет равен
 (2)
(2)где rtt[сек] зарегистрированное RTT, base_rtt[сек] наименьшее встретившееся в данном цикле RTT, а a и b - некоторые константы (смотри также [3]). Эта модификация ТСР требует высокого разрешения таймера отправителя. t - текущий момент времени.
Алгоритм TCP-Tahoe является наиболее старым и широко распространенным [16]. Этот алгоритм был сформулирован Джакобсоном в 1988 году, некоторые коррекции были внесены в него позднее.
Если буфер переполнен, какое-то число сегментов будет потеряно. При этом может быть запущено несколько сценариев. Основной вариант - медленный старт, запускается в рамках классического алгоритма ТСР-Tahoe при потере сегмента и сопряженным с ним таймаутом (RTO) у отправителя, так как отправитель не получит сигнала подтверждения ACK для потерянного сегмента. Медленный старт предполагает установку окна перегрузки (CWND) равным 1, а порога медленного старта (ssthresh) равным половине значения CWND, при котором произошел таймаут. Сокращение CWND до единицы происходит потому, что отправитель не имеет никакой информации о состоянии сети. Далее после каждого подтверждения CWNDi+1 = CWNDi+1. Эта формула работает до тех пор, пока CWND не станет равным ssthresh. После этого рост CWND становится линейным (смотри формулу 1). Смысл этого алгоритма заключается в удержании значения CWND в области максимально возможных значений. По существу эта оптимизация осуществляется с помощью потери пакетов. Если потери пакетов не происходит, значение CWND достигает значения window по умолчанию, задаваемого при конфигурации ТСР-драйвера. На рис. 2 показана эволюция CWND при потере пакетов.
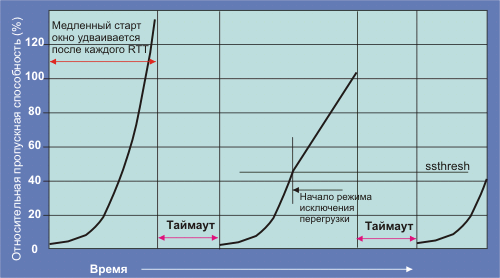
Рис. 2.
Значение таймаута вычисляется по формуле:
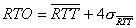
где s - средне-квадратичное отклонение среднего значения RTT.
Потерянный пакет и все, посланные после него, пакеты (вне зависимости оттого, подтверждено их получение или нет) пересылаются повторно. При большой вероятности потери это существенно понижает пропускную способность и увеличивает и без того высокую загрузку канала.
Может возникнуть вопрос, почему при потере пакета CWND делается равным 1, а не CWND-1 или CWND/2? Ведь эффективность канала максимальна при наибольшем, возможном значении CWND. Если произошла потеря пакета из-за переполнения буфера, оптимальное значение CWND может быть выбрано лишь при исчерпывающем знании прогноза состояния виртуального канала. Постольку такая информация обычно недоступна, система переходит в режим освобождения буфера (CWND=1). Ведь если потеря была связана с началом сессии обмена с конкурирующим клиентом, операция CWND= CWND-1 проблему не решит. А потеря пакета вызовет таймаут и канал будет блокирован минимум на 1 секунду, что вызовет резкое падение скорости передачи.
Использование стартового значения CWND>1 может увеличить эффективность виртуального ТСР-канала. Стартовое значение CWND = 2*MSS представляется вполне разумным. Понятно, что в критических ситуациях CWND=1 должно быть непременно разрешено. На рис. 3 показана эволюция CWND (результат моделирования [3]) при двух последовательных медленных стартах (один из них может быть вызван случайной потерей сегмента). Отсюда видно, что случайные потери сильно понижают пропускную способность канала.
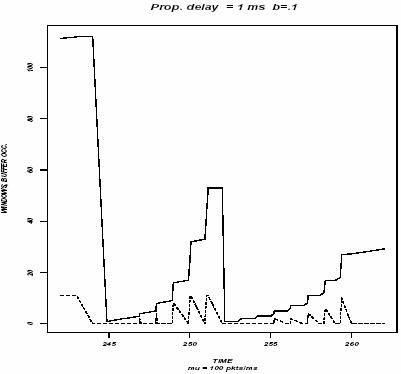
Рис. 3. Эволюция cwnd при двух медленных стартах
(T. V. Lakshman, Upamanyu Madhow, “The performance of TCP/IP for networks with high bandwidth-delay products and random loss”, IEEE/ACM Trans. Networking, V5, N3, p.336-350, June 1997)
Среди множества предлагаемых моделей реализации ТСР можно выделит еще одну - TCPW (TCP Westwood). Эта модель позволяет достичь большей эффективности использования канала. В этой модификации протокола используется новый алгоритм управления окном перегрузки, основанный на оценке потока данных (RE - Rate Estimation) и текущего значения полосы пропускания. На основе этих оценок производится вычисление cwin и ssthresh. Для больших произведений полоcы на RTT этот алгоритм может дать лучший результат, чем NewReno.
if(получено 3 DUPACK)
ssthresh = (BE*RTTmin)/seg_size;
if(cwin > ssthresh) /* исключение перегрузки */
cwin=ssthresh;
endif
endif
где seg_size идентифицирует длину ТСР-сегмента в битах, а DUPACK -задублированное подтверждение, BE - (bandwidth estimation) оценка полосы. Заметим, что после получения n DUPACK следует повторная пересылка потерянных сегментов, как это делается в стандартном режиме быстрой повторной пересылке ТСР Reno. Окно ростет после установление его ширины равной ssthresh согласно правилам алгоритма быстрой повторной пересылки (cwin=cwin+1 при получении каждого ACK и делается равным ssthresh при получении ACK для новых данных). Следовательно, когда получено n DUPACK, мы достигли предела пропускной способности сети. window = BE × RTTmin.
Переход к фазе исключения перегрузки связан с плавным поиском доступного значения полосы пропускания канала. Значение RTTmin равно наименьшему значению измеренному протоколом ТСР. Заметим, что после установления ssthresh значение ширины окна перегрузки делается равным порогу медленного старта, только если cwin > ssthresh. В протоколе TCPW для оценки BE используются ACK. Для этого регистрируется частота ACK и измеряется объем данных, доставленных в единицу времени. bk=dk/Dtk; Dtk = tk-tk-1, где tk время прихода k-го ACK отправителю, dk - длина подтвержденного сегмента.
В случае, когда потеря пакета индицируется истечением времени таймаута, значения cwin и sstresh устанавливаются согласно:
if(произошел таймаут RTO)
cwin=1;
ssthresh=(BE*RTTmin/seg_size;
if(ssthresh<2)
ssthresh=2;
endif
endif
В случае использования комбинированного алгоритма CRB (Combined RE/BE), где применен более сложный алгоритм оценки загрузки и доступной полосы пропускания, присвоение значений cwin и ssthresh производится согласно следующим соотношениям: (вариант потери с индикацией посредством присылки 3 DUPACK)
| if(получено 3 DUPACK) | |
| if(cwin/((RE*RTTmin)/seg_size>0) | /* сеть перегружена */ |
| ssthresh = (RE*RTTmin)/seg_size; | |
| else | /* перегрузки нет */ |
| ssthresh = (BE*RTTmin)/seg_size; | |
| endif | |
| if(cwin> ssthresh) | /* исключение перегрузки */ |
| cwin = ssthresh; | |
| endif; endif | |
В случае, когда потеря пакета индицируется по таймауту, значения cwin и ssthresh вычисляются следующим образом.
if(произошел таймаут RTO)
cwin=1;
ssthresh=(BE*RTTmin/seg_size;
if(ssthresh<2)
ssthresh=2;
endif;
endif
Заметим также, что объекты, вовлеченные в соединения, оказываются в определенной мере синхронизованными. Это связано с тем, что когда происходит любое столкновение, сопряженное с увеличением ширины окна, когда буфер полон, все приходящие ячейки, принадлежащие пакетам, отбрасываются. В предположении о постоянной готовности отправителя к передаче и о том, что временной разброс ячеек не превосходит время пересылки пакета во входном канале, все соединения будут передавать ячейки в течение времени транспортировки пакетов вовлеченных в столкновение. Следовательно, все соединения теряют пакеты и сокращают вдвое ширину окна в пределах RTT.
Помимо таймаута, в протоколе TCP предусмотрена еще одна возможность уведомления отправителя о потере сегмента. Получатель, контролируя номера приходящих сегментов и обнаружив потерю, может начать посылать двойные ACK для пакетов, следующих за потерянным сегментом. Приход таких дублированных ACK позволяет разрешить проблему до истечения времени таймаута RTO (смотри описание алгоритма TCP-reno). Понятно, что для последнего сегмента в сообщении этот метод не работает и остается только таймаут. Получения двойного ACK не является надежным сигналом потери пакета. Двойные ACK возникают и при смене маршрута обмена. По этой причине сигналом потери считается получение трех ACK пакетов подряд (сигнал быстрой повторной посылки сегмента - fast retransmit). В этом режиме при потере одиночного пакета (Fast Recovery) CWND устанавливается на три сегмента больше, чем значение ssthresh. После получения сигнала ACK значение CWND становится равным ssthresh с дальнейшим линейным увеличением. Здесь приход очередного ACK увеличивает CWND на (MSS*MSS)/CWND. Область линейного увеличения CWND часто называется режимом исключения перегрузки (congestion avoidance) или AIMD (Additive Increase, Multiple Decrease).
На пути сегмента может повстречаться перегруженный переключатель (L2), который поддерживает алгоритм “обратного давления”. Такой сетевой прибор при переполнении его буферов пошлет отправителю уведомление о перегрузке в виде пакета ICMP(4). В ответ на такой сигнал отправитель должен понизить скорость передачи пакетов в два раза. Следует иметь в виду, что такое событие слабо коррелированно с процессами ТСР-обмена и определяется условиями, складывающимися в независимых соседних каналах. Характер реакции на ICMP(4) определяется конкретными особенностями ТСР-драйвера отправителя.
Вспомним, что помимо управления перегрузкой со стороны отправителя в ТСР предусмотрен механизм управления со стороны получателя. Получатель в отклике АСК посылает значение параметра window, которое определяет число сегментов, которое готов принять получатель. Механизм управления скользящим окном особенно важен при работе в сетях с большой величиной RTT (например, в случае спутниковых каналов). При этом размер буфера при заданной полосе пропускания канала B и времени задержке t должен равняться Bt /T, где t - время обслуживания пакета, а T = t + t. Канал можно рассматривать как трубу, которая при работе всегда должна быть заполнена. Емкость этой трубы определяется величиной cwnd. Максимально возможная емкость такой трубы Vt в стационарном режиме равна Vt = T/t + B = t /t +B +1. При этом буфер будет полностью заполнен и Т/t пакетов находится в пути. В алгоритме TCP-Tahoe после потери сегмента ssthresh = Vt/2. Понятно, что когда cwnd становится равным Vt, происходит переполнение буфера и потеря пакета. Задача управления перегрузкой виртуального канала является классической проблемой теории массового обслуживания. Аналитическое рассмотрение проблемы и результаты моделирования можно найти в [3].
Одна из существенных трудностей оптимизации виртуального соединения ТСР связана с тем, что между участниками обмена может находиться неизвестное число сетевых устройств, загрузка которых может варьироваться произвольным образом, а управление находится в компетенции внешних сетевых администраторов.
Поиски решения оптимизации ТСР-каналов можно вести по двум направлениям. Модифицировать сам ТСР-протокол, адаптируя его для новых условий и требований, или изменять сетевую среду, делая ее более дружественной по отношению к ТСР. Любое изменение ТСР-протокола должно обеспечить обратную совместимость, чтобы миллионы “старых” программ могли по-прежнему работать в этой среде. А это в свою очередь предполагает некоторый диалог при установлении виртуального соединения, который бы позволял выяснить, какими версиями ТСР обладают будущие партнеры. Причем сессии с модернизированным ТСР должны уживаться со старыми на всех уровнях. Совокупность этих соображений удерживала до сих пор Интернет общественность от радикальных модификаций протокола ТСР.
Одним из подходов, который используется весьма широко, является переход, там, где возможно, на протокол UDP.
Другой возможностью является привлечение вместо ТСР протокола T/TCP (TCP for Transactions), который улучшает эксплуатационные характеристики виртуального канала в случае коротких транзакций. T/TCP помещает данные запроса и флаг завершения FIN в начальный SYN-сегмент. Это может интерпретироваться, как попытка открыть сессию, передать данные, и закрыть сессию со стороны отправителя. Если сервер воспринимает такой формат, он откликнется одним пакетом, содержащим SYN-отклик, ACK на полученные данные и закрывающий сессию флаг FIN. Для окончательного завершения сессии клиент должен послать серверу сегмент с флагами ACK и FIN. К сожалению, внедрение T/TCP предполагает модификацию программного обеспечения, как сервера, так и клиента. По этой причине протокол T/TCP не получает широкого распространения. Кроме того, он достаточно уязвим с точки зрения безопасности.
Бесспорные преимущества при потере нескольких сегментов за один период RTT предлагает алгоритм выборочного подтверждения SACK (Selective Acknowledgement). Понятно, что следует избегать повторной пересылки благополучно доставленных пакетов (как это делается, например, в протоколе XTP).
Дополнительные проблемы возникают при реализации ТСР через спутниковые каналы, где RTT превышает 250 мсек, да и BER оставляет желать лучшего. При таких значениях RTT время преодоления ситуации перегрузки может занимать много циклов RTT и достигать десятка секунд. Короткие ТСР-сессии для таких каналов крайне неэффективны (не успеет система поднять значение CWND до приемлемого размера, а уже все данные переданы). Частично это может компенсироваться за счет реализации большого числа ТСР-сессий параллельно.
Хотя ТСР использует соединение точка-точка, имеется возможность попытаться улучшить рабочие характеристики канала, оптимизируя алгоритм управления очередями. Одним из возможных подходов является алгоритм RED (Random Early Detection). RED позволяет маршрутизатору отбрасывать пакеты, даже когда в очереди еще имеется место.
| Следует помнить, что установка пакета в очередь или его отбрасывание согласно правилам RED/WRED (или FQ) осуществляется на уровне IP-протокола (ведь именно он содержит поле заголовка DSCP или метка потока). |
Алгоритм RED использует взвешенное значение длины очереди в качестве фактора, определяющего вероятность отбрасывания пакета. По мере роста средней длины очереди растет вероятность отбрасывания пакетов. Если средняя длина очереди меньше определенного порога вероятность отбрасывания пакета равна нулю. Небольшие кластеры пакетов могут успешно пройти через фильтр RED. Более крупные кластеры могут понести потери. Это приводит к тому, что ТСР-сессии с большими открытыми окнами имеют большую вероятность отбрасывания пакетов. Главной целью алгоритма RED является исключение ситуация, когда несколько ТСР-потоков перегружаются почти одновременно и затем синхронно начинают процедуру восстановления. Интересное предложение относительно выборочного (приоритетного) отбрасывания пакетов содержится в работе [36] в отношении мультимедиа потоков.
Алгоритм RED позволяет организовать очереди таким образом, что их размер отслеживает осцилляции величины RTT. RED пытается увеличить число коротких перегрузок и избежать долгих. Задача RED заключается в том, чтобы сообщить отправителю о возможности перегрузки, и отправитель должен адаптироваться к этой ситуации.
| RED пытается увеличить число коротких перегрузок и избежать долгих. Задача RED заключается в том, чтобы сообщить отправителю о возможности перегрузки, а отправитель должен адаптироваться к этой ситуации. |
Существует модификация алгоритма обработки очередей WRED (Weighted Random Early Detection), широко используемая в маршрутизаторах. Этот алгоритм применяется и при реализации DiffServ и гарантированной переадресации (AF), когда решение об обработке пакета принимается в каждом транзитном узле независимо (PHB). При этом может учитываться код DSCP IP-заголовка.
Алгоритм WRED удобен для адаптивного трафика, который формируется протоколом ТСР, так как здесь потеря пакетов приводит к снижению темпа их посылки отправителем. Алгоритм WRED приcваивает пакетам не IP типа нулевой приоритет, повышая вероятность потери таких пакетов. Имеется возможность конфигурации WRED и WFQ для одного и того же интерфейса.
WRED полезен для любого выходного интерфейса, где ожидается перегрузка. Когда приходит пакет, вычисляется среднее значение длины очереди. Если вычисленное значение меньше минимального порога очереди, приходящий пакет ставится в очередь. Если вычисленное значение лежит между минимальным порогом очереди для данного типа трафика и максимальным порогом для интерфейса, пакет ставится в очередь или отбрасывается в зависимости от вероятности отброса, установленной для данного типа трафика. И, наконец, если размер очереди больше максимального порога, пакет отбрасывается.

Рис. 4.
WRED статистически отбрасывает больше пакетов для сессий с большими потоками. По этой причине ТСР-отправители больших потоков будут вынуждены в большей степени понизить поток, чем отправители малого трафика.
Ни АТМ-интерфейсы маршрутизаторов, ни АТМ-коммутаторы не предоставляют гарантий QoS для UBR виртуальных каналов. Маршрутизатор CISCO может специфицировать только пиковую скорость передачи (PCR) для UBR-канала.
Маршрутизатор автоматически определяет параметры, которые нужно использовать в вычислениях WRED. Среднее значение длины очереди определяется на основе предыдущего значения и текущего размера очереди, согласно:
Среднее = (old_evarage × (1-2-n)) + (current_queue_size × 2-n),
где n - экспоненциальный весовой фактор, конфигурируемый пользователем.
Большое значение этого фактора сглаживает пики и провалы значения длины очереди. Средняя длина очереди не будет меняться быстро. Процесс WRED не сразу начнет отбрасывать пакеты при перегрузке, зато продолжит отбрасывание даже когда перегрузки уже нет (очередь уже сократилась ниже минимального порога). Когда n становится слишком большим, WRED не будет реагировать на перегрузку. Пакеты будут посылаться или отбрасываться так, как если бы WRED не работал.
Для малых значений n среднее значение длины очереди практически совпадает c текущей ее величиной, что вызывает значительные флуктуации среднего значения. В этом случае реакция WRED на превышение длины очереди становится практически мгновенной. Если значение n слишком мало, WRED чрезвычайно чувствителен к флуктуациям трафика, что может снижать пропускную способность.
Вероятность отбрасывания пакета зависит от минимального порога, максимального порога и маркерного деноминатора вероятности. Когда средняя длина очереди выше минимального порога, RED начинает отбрасывать пакеты. Частота отбрасываний увеличивается линейно по мере роста длины очереди до тех пор, пока размер очереди не достигнет максимального порога.
Маркерный деноминатор вероятности равен доле теряемых пакетов, когда средняя длина очереди равна максимальному порогу. Например, если деноминатор равен 512, один из 512 пакетов отбрасывается, когда средняя дина очереди достигает максимального порога (см. рис. ниже). Когда длина очереди превышает максимальный порог, отбрасываются все пакеты. Минимальный порог следует выбрать достаточно высоким, чтобы максимизировать использование канала.
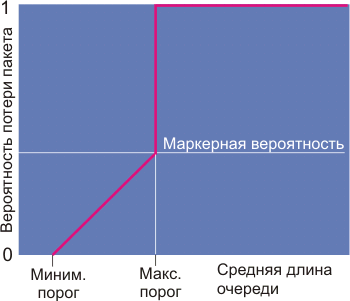
Рис. 5.
Разница между максимальным и минимальным порогом должна быть достаточно велика, чтобы избежать глобальной синхронизации ТСР агентов (синхронное изменение CWND).
В качестве альтернативы можно рассмотреть ситуацию, когда маршрутизатор осуществляет пометку пакетов с помощью бита-флага СЕ (Congestion Experienced). Отправитель должен реагировать на этот флаг так, как если бы произошла потеря пакета. Этот механизм, называемый ECN (Explicit Congestion Notification), использует двух битную схему оповещения, занимая биты 6 и 7 в поле ToS заголовка IPv4 (или два неиспользуемые бита в поле IP Differentiated Services). Бит 6 устанавливается отправителем с целью индикации того, что эта система совместима с ECN (бит ECN). Бит 7 является СЕ-битом и устанавливается маршрутизатором, когда размер очереди превышает заданное при конфигурации значение. ECN-алгоритм реализует в маршрутизаторе RED. Когда какой-то пакет выбран, он помечается битом СЕ, если в нем установлен бит ECN, в противном случае пакет отбрасывается.
Заметим, что механизмы управления очередями во многих случаях не будут работать, так как перегрузка происходит в сетевом устройстве (например, L2), которым вы управлять не можете.
Исходный диалог установления соединения ТСР при реализации данного алгоритма предполагает добавление возможности ECN-эха и CWR (Congestion Window Reduced) для уведомления партнера о возможности работы с СЕ-битом. Отправитель устанавливает бит ECN во всех посылаемых пакетах. Если отправитель получит ТСР-сегмент с флагом ECN-эхо, он должен подстроить ширину CWND в соответствии с алгоритмом быстрого восстановления при потере одиночного пакета. Следующий посланный пакет должен иметь TCP CWR-флаг, оповещающий получателя о его реакции на перегрузку. Отправитель реагирует подобным образом, по крайней мере, один раз за время RTT. Далее ТСР-пакеты с установленным флагом ECN не вызывают никакой реакции в пределах интервала RTT. Получатель устанавливает ECN-флаг во всех пакетах, когда он получает пакет с установленным битом СЕ. Это продолжается до тех пор, пока он не получит пакет с флагом CWR, указывающим на реакцию отправителя на перегрузку. ECN-флаг устанавливается только в пакетах, которые содержат поле данных. Пакеты ТСР ACK, которые не имеют поля данных, должны содержать флаг ECN=0.
Соединение не должно ждать получения трех ACK, чтобы детектировать перегрузку. Вместо этого получатель уведомляется о зарождающейся ситуации перегрузки путем установления соответствующего бита, который в свою очередь вызывает соответствующий отклик. Широкое использование ECN в ближайшее время не ожидается, во всяком случае, в контексте IPv4. По этой причине не принято никакого стандарта для позиционирования соответствующих бит в IP-заголовке.
ECN предоставляет некоторое улучшение эксплуатационных характеристик канала по сравнению со схемой RED, в частности для коротких ТСР-транзакций. Главной особенностью алгоритма ECN является необходимость изменения программ работы как маршрутизатора так и стека TCP/IP. Выгоды этого алгоритма могут стать заметными лишь при достаточно широком внедрении. Можно ожидать более быстрого по отношению ECN распространения алгоритма RED, так как он требует лишь локальной модификации программного обеспечения маршрутизатора.
| Следует также помнить, что работа слишком тихоходной станции с малым объемом оперативной памяти в быстродействующей сети ухудшает характеристики обмена не только для нее, но и для соседей. |
Оптимизировать виртуальный канал можно, если отправитель и получатель имеют исчерпывающую информацию о состоянии партнера и самого канала. К сожалению такой информации обычно нет. Получатель, например, не знает, находится ли отправитель в режиме медленного старта, исключения перегрузки или проходит стадию восстановления после перегрузки.
Другим подходом управления перегрузкой является использование откликов ACK для контроля поведения отправителя. Предпосылкой для такого решения является то, что путь трафика симметричен и устройство, где происходит перегрузка, может идентифицировать пакеты ACK, двигающиеся в противоположном направлении. Для такого подхода имеется две альтернативы.
ACK Pacing (прореживание): Каждый кластер пакетов будет генерировать соответствующий кластер откликов ACK. Расстояние между этими откликами определяет частоту следования пакетов в кластере. Для систем с большими временами RTT размер кластера может оказаться ограничивающим скорость передачи фактором. Если вы можете замедлить скорость передачи, размер очереди в буфере может быть сокращен. Одним из подходов к снижению скорости передачи, является увеличение периода следования ACK на выходе транзитного маршрутизатора. Такой подход может оказаться эффективным для каналов с большими задержками. Этот механизм предполагает, информационные сегменты и отклики идут по тому же маршруту (но естественно в разных направлениях).
Манипуляция окном. Каждый пакет ACK несет в себе размер окна получателя. Такое окно определяет максимальный размер кластера, который может прислать отправитель. Манипулируя размером окна, можно регулировать скорость передачи.
Оба указанных механизма подразумевают достаточно широкие предположения о GW сети. Главное предположение заключается в том, что в точке GW потоки симметричны. Оба механизма подразумевают, что GW может кэшировать статусные данные для каждого из потоков, так что RTT текущего потока, текущее значение скорости передачи и размер окна получателя доступны контролеру услуг. Прореживание ACK предполагает также, что один ACK-отклик активен в любое время вдоль сетевого маршрута. Задержка ACK может привести к истечению времени таймаута у отправителя.
Если потеря из-за перегрузки происходит на ранней фазе медленного старта, в сети недостаточно пакетов, чтобы сгенерировать три дублированных ACK-отклика для запуска быстрой повторной пересылки и быстрого восстановления. Вместо этого отправитель должен подождать таймаута RTO (минимальное время равно одной секунде). Для коротких сессий длиной (6-7) RTT ~ нескольких миллисекунд издержки, связанные с потерей одного пакета слишком велики. Приблизительно 56% повторных передач осуществляется после таймаута RTO.
Возможным усовершенствованием данного алгоритма может быть механизм, называемый ограниченной передачей (Limited Transmit).
При реализации этого механизма налагаются два условия. Присланное получателем значение окна разрешает передачу данного сегмента, а часть данных остается за пределами окна перегрузки плюс порог двойного ACK, который используется для запуска быстрой повторной передачи. Второе условие предполагает, что отправитель может послать только два сегмента вне пределов CWND и делает это только в качестве отклика на удаления сегмента из сети.
Базовый принцип этой стратегии заключается в продолжении сигнального обмена между отправителем и получателем, несмотря на потерю пакета, увеличивающего вероятность того, что отправитель восстановится после потери, используя дублированные ACK и быстрый алгоритм восстановления и уменьшая шанс односекундного (или даже долее) восстановления после RTO.
Ограниченная передача уменьшает также возможность того, что процедуры восстановления приведут к новым потерям пакетов.
Иногда возникают ситуации, когда приложение воспринимает управляющие функции ТСР слишком лимитирующими. Это может происходить, например, при управлении общедоступными коммутирующими телефонными сетями через Интернет. В таком варианте не требуется обеспечение строгой последовательности пакетов (отсутствие перепутывания порядка). Кроме того, ограниченное число TCP-сокетов усложняет поддержку приложений, использующих несколько сетевых интерфейсов, да и сам протокол ТСР уязвим для ряда атак, например SYN-шторм. Решение такого типа проблем возможно с привлечением протокола SCTP (Stream Control Transmission Protocol).
Основным отличие между SCTP и TCP проявляется на фазе инициализации, когда партнеры SCTP обмениваются списком оконечных адресов (IP-адресов и номеров портов), которые ассоциируются с текущей сессией. Стартовая процедура SCTP также отличается от четырех ходового диалога. Здесь получатель не выделяет никаких ресурсов для соединения, что делает процедуру более устойчивой против атак типа SYN-шторма. Инициатор соединения может, в конце концов, откликнуться, послав COOKIE-ECHO, куда вкладывается порция данных. Таким образом, информационный обмен начинается уже на фазе формирования виртуального соединения. С этого момента сессия считается открытой.
Закрытие сессии SCTP также отличается от ТСР. В SCTP закрытие сессии с одной стороны означает опустошение очередей и прекращение посылки данных и с другой стороны. Здесь через одну и ту же ассоциацию транспортного уровня может осуществляться несколько обменов. Порядок сообщений в рамках одного обмена неукоснительно соблюдается. Каждый поток имеет однозначную идентификацию. Протокол SCTP поддерживает также доставку вне очереди, когда пакет помечается для немедленной доставки, и тогда он получает приоритет и будет доставлен раньше, чем это предписывалось его порядковым номером. Протокол SCTP требует предварительного выяснения значения MTU. предусмотрен в SCTP (как и в ТСР) и таймер повторных передач, запускаемый при посылке каждого сегмента. Получатель SCTP использует режим подтверждений SACK, реализуемый для каждого второго полученного сегмента. Если сообщение оказалось в зазоре между SACK, после трех таких откликов отправитель повторно посылает такое сообщение и сокращает вдвое CWND.
Использование обменов точка-мультиточка предполагает, что каждый оконечный адрес, ассоциированный с одной и той же ЭВМ, не обязательно использует один и тот же путь. По этому для каждой конечной точки периодически должна производится проверка осуществимости связи (процедура keepalive).
Идея совмещения состояния ТСР перегрузки для нескольких каналов применима и для смеси потоков с гарантией и без гарантии доставки, осуществляющих одновременно обмен между общими конечными пунктами. Именно такая схема мультиплексирования реализуется в модели менеджера перегрузки. Менеджер перегрузки представляет собой модуль оконечной системы, который позволяет набору одновременных потоков от ЭВМ к некоторой точке назначения совместно использовать общую систему управления перегрузкой.
Основной причиной для использования менеджера перегрузки послужило то, что наиболее критическим пунктом управления сетью является управление взаимодействием между ТСР потоками с контролем перегрузки и информационными UDP потоками. В крайних случаях такого взаимодействия каждый из классов трафика может отказывать в сервисе другому, оказывая достаточное давление на сетевые механизмы управления очередями и тем самым лишая этих ресурсов другой класс трафика. Ситуация достаточно типична, например для WEB-сервера, который может организовать несколько виртуальных соединений для одного клиента для разных классов трафика.
Реализация общей функции управления перегрузкой может базироваться на механизме отзыва (callback), когда приложение посылает запрос менеджеру перегрузки (МП). МП откликается посылкой отзыва и приложение после этого может послать информационный сегмент протокольному драйверу.
Другой поддерживаемый механизм МП называется синхронной передачей. Здесь МП предоставляет приложению данные о состоянии канала (пропускная способность, RTT и т.д.) и оно может осуществить запрос лишь, когда состояние сети изменится существенным образом (пороги по базовым параметрам задаются при конфигурации). Удаленная ЭВМ информирует МП о числе полученных и потерянных байтов, о результатах измерения RTT, полученных на уровне приложения. Приложение предоставляет информацию о причинах потерь (истечение таймаута, состояние транзитных сетей или отбрасывание на основе ECN-флагов).
В последнее время появилось достаточно много версий протокола “лучше чем ТСР”, большинство из них предлагаются в комплекте с WEB-сервером. Чаще всего это модифицированные версии ТСР. Например, за счет таймера более высокого разрешения, позволяющего реагировать более быстро на изменения в сети. Некоторые версии предлагают большее стартовое значение CWND или более быструю версию медленного старта, где размер окна не удваивается, а утраивается на каждом из шагов (за RTT). Сходные модификации могут быть использованы на фазе избежания перегрузки (линейный участок увеличения CWND). Все эти модификации вынуждают отправителя вести себя более агрессивно, увеличивая давления на сетевые буферы. Возможно создание программ обмена, где, например, при копировании через сеть файла, формируется не одно, а несколько виртуальных соединений. Такого рода решения дают выигрыш главным образом за счет ухудшения условий реализаций других одновременных сессий. Это противоречит общей философии Интернет (Интернет - это клуб джентльменов). Но на самом деле агрессивное поведение ТСР приложения в конечном итоге делает его неэффективным (менее эффективным, чем стандартный ТСР). Как правило, такие решения приводят к большим потерям пакетов, так как их усилия максимально загрузить ресурсы сети приводят к понижению чувствительности к сигналам перегрузки. Если же таких приложений в Интернет станет много, это приведет к серьезной деградации пропускной способности каналов из-за перегрузки. Приемлемыми усовершенствованиями ТСР можно признать только такие, которые не ухудшают условий работы для окружающих. Это наилучшая стратегия, так как позволяет использовать ресурсы сети более эффективно.
Работа протокола TCP AIMD в режиме исключения перегрузок можно характеризовать формулой [1]:
BW=
где BW - полоса пропускания;
MSS - максимальный размер сегмента в байтах, используемый сессией.
RTO - таймаут повторной пересылки.
r - частота потери пакетов (0.01 означает 1% потерь)
Эта формула является наилучшей аппроксимацией. Некоторое упрощение формулы можно получить, считая RTO=5*RTT.
Еще более упрощенная формула может быть взята из работы [31].
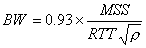
Данные формулы выведены при следующих предположениях:
Суммируя, можно сказать, что мы идентифицировали несколько недостатков TCP, мы также представили возможные средства получения хороших рабочих характеристик посредством решений сетевого уровня, таких как изоляция соединений друг от друга, и предоставление буферов достаточного объема, чтобы устранить быстрые вариации доступной канальной емкости. Но нужно помнить, что нельзя увеличивать объем буфера беспредельно, так как это может привести к таймаутам и в конечном итоге к большим потерям пропускной способности. Особенно интересным является вопрос, как наилучшим образом поддержать TCP поверх ATM классов услуг ABR и UBR, так как это включает адаптацию сетевого и транспортного уровней. Другой важной областью исследований является разработка альтернативного механизма управления окном, который устранит некоторые недостатки TCP, сохранив его децентрализованную структуру. Децентрализованное адаптивное управление скоростью передачи, при сохранении справедливости распределения ресурсов является трудным, если вообще возможным, но некоторое улучшение TCP несомненно реально. Возможные усовершенствования могут превзойти алгоритм исключение перегрузки за счет более изощренной оценки задержек RTT, и использования селективного подтверждения, чтобы улучшить рабочие характеристики при наличии случайных потерь.
Здесь уместно сказать, что радикальным решением могло бы быть исчерпывающее информирование отправителя о состояние и динамике заполнения всех буферов вдоль виртуального соединения. Такой алгоритм можно реализовать лишь при условии, что все сетевое оборудование вдоль виртуального пути способно распознавать сегменты-отклики и выдавать требующиеся данные в рамках определенного протокола (в том числе и оборудование уровня L2!). Здесь предполагается, что маршрут движения сегментов туда и обратно идентичны. В последнее время появилось оборудование L2 (Ethernet), способное фильтровать трафик по IP-адресам и даже номерам портов (а это уже уровень L4). Так что это уже не представляется чем-то совершенно фантастическим. Такие сетевые приборы могли бы помещать в пакеты откликов ACK информацию о состоянии своих буферов. Учитывая, что объемы буферов в разных устройствах могут отличаться весьма сильно, имеет смысл выдавать не число занятых позиций, а относительную долю занятого буферного пространства. Проблема здесь в том, что длительное время даже в локальных сетях, я уже не говорю про Интернет, будут сосуществовать сетевые устройства, как поддерживающие этот новый протокол, так и старые - не поддерживающие. Но даже в таких условиях этот протокол будет давать заметный выигрыш. Ведь новые устройства будут ставиться в первую очередь именно в “узких” местах сети, где потери были наиболее значимы. Условия загрузки нового устройства останутся теми же, но о них отправитель получит исчерпывающую информацию и за счет этого оптимизировать трафик. При этом отправитель должен отслеживать не просто состояние на текущий момент, но и темп заполнения и освобождения буферов. Ширина окна в этом случае может определяться на основе прогноза состояния буфера на момент, когда туда придет соответствующий ТСР-сегмент. Для этого отправителю придется выделить дополнительную память для хранения коэффициентов заполнения буферов. Задержка в цепи отслеживания состояния тракта при этом будет минимальной.
Проблема усложнена разнообразием технологий L2, ведь трудно себе представить, чтобы нужную информацию о состоянии буферов будет выдавать ATM или SDH. Но наметившаяся тенденция использования Ethernet не только в LAN, но в региональных сетях, может упростить задачу.
Альтернативой этому алгоритму могла бы служить схема, где каждому виртуальному соединению в каждом вовлеченном сетевом устройстве (включая L2) выделялся свой независимый буфер известного объема.
Любое из названных решений требует замены огромного объема оборудования. Но, во-первых, раз в 2-5 лет оборудование все равно обновляется, во-вторых, это даст выигрыш в пропускной способности не менее двух раз и существенно упростит задачу обеспечения требуемого уровня QoS.
Первым шагом на пути внедрения отслеживания уровня заполнения буфера может служить ECN-алгоритм, описанный выше.
Разрабатывая новые версии драйверов ТСР-протокола надо с самого начала думать и о сетевой безопасности, устойчивости программ против активных атак.
Новые трудности в реализации модели протокола ТСР возникли при работе с современными быстрыми (1-10 Гбит/с) и длинными (RTT>200мсек) каналами. Для пакетов с длиной 1500 байт время формирования окна оптимального размера достигает 83333 RTT (режим предотвращения перегрузки), что при RTT=100мсек составляет 1,5 часа! При этом требования к вероятности потери пакетов становятся невыполнимыми. Это явление называется реактивностью. В норме для таких каналов BER лежит в пределах 10-7 - 10-8. Разрешение проблемы возможно путем использования опции Jumbo пакетов или за счет открытия нескольких параллельных ТСР-соединений. В последнее время предложено несколько новых моделей реализации ТСР: High Speed TCP (HSTCP - S.Floyd), Scalable TCP (STCP - T.Kelly), FAST (http://datatag.web.cern.ch/datatag/pfldnet2003/papers/ low.pdf), XCP (http://portal.acm.org/citation.cfm?doid=633035), SABUL (Y.Gu, X.Hong). Модификации HSTCP и STCP характеризуются тем, что при нескольких потоках с разными RTT они некорректно распределяют полосу. В этих условиях заметные трудности создает синхронизация потерь для конкурирующих потоков. Специально для случая высокой скорости и больших задержек разработана модификация BI-TCP (Binary Increase TCP - http://www.csc.ncsu.edu/faculty/rhee/export/bitcp.pdf, Lisong Xu, Khaled Harfoush and Injong Rhee, Binary Increase Congestion Control for Fast, Long Distance Networks). Протокол BI-TCP имеет следующие свойства:
AIMD демонстрирует квадратичный рост пропускной способности при увеличении отношения RTT (линейный рост "несправедливости"). Для других протоколов степень несправедливости еще выше.
Функция отклика протокола на перегрузку определяется отношением скоростей передачи пакетов в зависимости от вероятности их потери.
BI-TCP встраивается в TCP-SACK. В протоколе используются следующие фиксированные параметры:
Low_window - если размер окна больше чем этот порог, используется BI-TCP, в противном случае обычный ТСР.
Smax - максимальное приращение
Smin - минимальное приращение
b - мультипликативный коэффициент сокращений ширины окна.
default_max_win - значение максимума окна по умолчанию
В протоколе используются следующие параметры:
| max_win | максимальное значение ширины окна, в начале равно величине по умолчанию |
| min_win | минимальная ширина окна |
| prev_win | максимальное значение ширины окна до установления нового максимума |
| target_win | средняя точка между максимумом и минимумом ширины окна |
| Cwnd | размер окна перегрузки |
| is_BITCP_ss | Булева переменная, указывающая, находится ли протокол в режиме медленного старта. В начале = false |
| ss_cwnd | переменная, отслеживающая эволюцию cwnd при медленном старте |
| ss_target | значение cwnd после одного RTT при медленном старте BI-TCP |
При входе в режим быстрого восстановления:
if (low_window <= cwnd) {
prev_max = max_win;
max_win = cwnd;
cwnd = cwnd *(1-b);
min_win = cwnd;
if (prev_max > max _win) //Fast. Conv.
max_win = (max_win + min_win)/2;
target_win = (max_win + min_win)/2;
} else {
cwnd = cwnd*0,5; //normal TCP
Когда система не находится в режиме быстрого восстановления и приходит подтверждение для нового пакета, то
if (low_window > cwnd) {
cwnd =cwnd + 1/cwnd; // normal TCP
return
}
if (is_BITCP_ss is false) { //bin.increase
if (target_win - cwnd < Smax) // bin.search
cwnd += (target_win - cwnd)/cwnd;
else
cwnd += Smax/cwnd; // additive incre.
if (max_win > cwnd) {
min_win = cwnd;
target_win = (max_win + min_win)/2;
} else {
is_BITCP_ss = true
ss_cwnd =1;
ss_target = cwnd+1;
max_win = default_max_win;
}
} else {
cwnd = cwnd + ss_cwnd/cwnd;
if(cwnd >= ss_target) {
ss_cwnd = 2*ss_cwnd; ss_target = cwnd + ss_cwnd;
}
if(ss_cwnd >= Smax)
is_BITCP_ss = false;
}
При анализе характеристик протокола предполагается, что потери пакетов происходят с вероятностью 1/р. Авторы определяют эпоху перегрузки, как время между двумя последовательными потерями пакетов.
Пусть Wmax обозначает размер окна непосредственно перед потерей пакета. После потери размер окна уменьшается до Wmax(1 - b). BI-TCP переключается от аддитивного увеличения к двоичному поисковому увеличению окна, когда различие между текущим значением ширины окна и конечным значением (target) меньше Smax. Так как конечное (target) значение ширины окна является средней точкой между Wmax и текущим значением ширины окна, можно сказать, что BI-TCP переключается между этими двумя приращениями, когда разница между текущей шириной окна и Wmax меньше 2Smax . Ниже в таблицах 2.2 и 2.3 представлены расчетные характеристики протоколов AIMD, BI-TCP, HSTCP и STCP для каналов с быстродействием 100 и 2500 Мбит/c.
Таблица 2.2. Отношения пропускной способности протоколов при 100Мбит/c
| Отношение RTT | 1 | 3 | 6 |
| AIMD | 0,99 | 7,31 | 26,12 |
| BI-TCP | 0,94 | 13,06 | 33,81 |
| HSTCP | 1,13 | 10,42 | 51,09 |
| STCP | 1,12 | 27,84 | 72,74 |
Таблица 2.3. Отношения пропускной способности протоколов при 2,5Гбит/c
| Отношение RTT | 1 | 3 | 6 |
| AIMD | 1,05 | 6,56 | 22,55 |
| BI-TCP | 0,96 | 9,18 | 35,76 |
| HSTCP | 0,99 | 47,42 | 131,03 |
| STCP | 0,92 | 140,52 | 300,32 |
На рис. 6 приведены расчетные данные для откликов при использовании разных модификаций протокола ТСР.
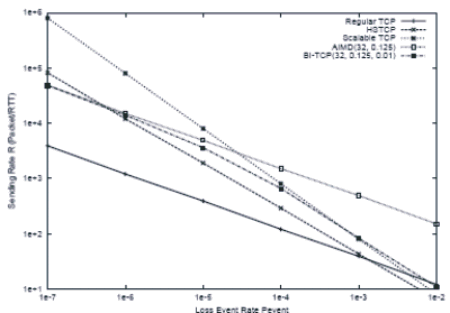
Рис. 6. Сравнение функций отклика для разных протоколов (http://www.csc.ncsu.edu/faculty/rhee/export/bitcp.pdf)
Версия TCP Hybla разработана в 2003-4 годах и имеет целью исключить издержки соединения TCP, которое включает участки каналов с большой задержкой (большие значения RTT). Это достигается путем аналитической оценки динамики окна перегрузки, которая предлагает модификации, исключающие зависимость от RTT.
TCP Hybla является экспериментальным улучшением TCP, имеющим целью блокировать ухудшения рабочих характеристик соединения при больших RTT, типичных для спутниковых каналов. Протокол включает в себя следующие процедуры:
TCP Hybla предполагает модификацию TCP только на стороне отправителя. По этой причине алгоритм полностью совместим со стандартными получателями.
Достаточно подробные описания модели Hybla можно найти в TCP Hybla Homepage:
Действующие версии протокола TCP (Tahoe, Reno, NewReno) страдают от проблем, связанных неоптимальностью рабочих характеристик при больших значениях задержек в канале, что достаточно часто встречается в наземных или спутниковых радио каналах. Так как протокол TCP был первоначально создан для противодействия перегрузкам, потери TCP-сегментов из-за искажений при передаче, ошибочно приписываемые переполнению буфера, запускают механизмы исключения перегрузки, которые в такой ситуации приносят только вред [1, 2]. Эта проблема может быть решена либо путем соответствующей модификации протокола TCP, либо, когда это возможно, с помощью повышения надежности ниже лежащего протокольного слоя [3]. Однако, следует иметь в виду, что даже в случае отсутствия ошибок в канале, радио соединения часто характеризуются большими задержками. Это связано с тем, что алгоритм передачи, базирующийся на CWND, запускаемый приходом пакетов ACK, зависят от сетевых задержек. Большие времена RTT сдерживают рост окна перегрузки и приводят к значительному снижению пропускной способности и некорректному перераспределению полосы пропускания между разными соединениями. В этом случае деградация рабочих параметров является прямым следствием свойств TCP-протокола и не может быть устранена без существенной модификации алгоритма управления перегрузкой. Эту задачу может решить алгоритм TCP Hybla.
Алгоритм TCP HYBLA. Основной идеей TCP Hybla является достижение для соединений с большим RTT (напр. спутниковых) тех же скоростей передачи, B(t), что и для проводных TCP-каналов. Соотношения B(t)= W(t)/RTT, W(t) - окно перегрузки, показывает, что цель может быть достигнута в два этапа: во-первых, сделав W(t), независимым от RTT, за счет модификации временного масштаба, во-вторых, скомпенсировав эффект деления на RTT. Оба эти этапа легче описать после введения нормализованного значения RTT, r, определенного как.
r= RTT/RTT0 (I)
где RTT0 равно RTT эталонного соединения, к которому хотим привести рабочие свойства канала. Сначала умножаем время на r (или время достижения ssthresh), делая W(t) независимым от RTT. Далее, умножив на r окно перегрузки, полученное на первом этапе (включая исходное значение ssthresh, g), достигаем независимости от RTT и B(t). В заключение мы получаем:
 II)
II)
где верхний индекс H указывает на принадлежность алгоритму Hybla. (SS - Slow Start; CA - Congestion Avoidance). Как следствие модификации, выполненной на втором этапе, время переключения tg0, определенное как время, когда окно перегрузки достигает значения rg, остается тем же для любого RTT, и равным tg0 = RTT0 log2 g. Эволюция окна перегрузки со временем, полученная в (6), представлена на рис. 7.
Из формулы (II) следует, что скорость передачи сегментов BH(t) = WH(t)/RTT для TCP Hybla имеет вид:
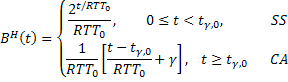 (III)
(III)
которое очевидно не зависит от RTT и равно скорости передачи сегментов в эталонном стандартном TCP-соединении.
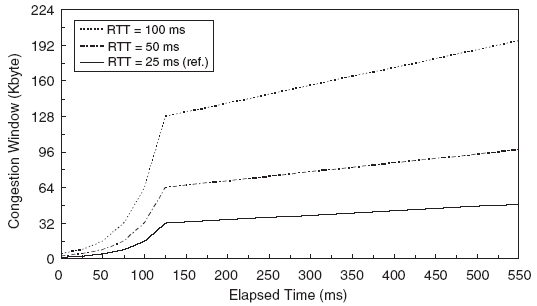
Рис. 7. TCP Hybla: эволюция окна перегрузки со временем для нескольких значений RTT
Используя (III), можно легко получить аналитическое выражение для числа сегментов, переданных с начала соединения TCP Hybla,
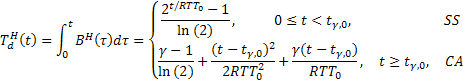 (IV)
(IV)
Из (IV), ясно, что поведение TCP Hybla не зависит от реального значения RTT. Это подтверждается числовыми значениями, представленными на рис. 8, где показаны данные для стандартного TCP и TCP Hybla для разных значений RTT, в условиях идеального канала (отсутствие потерь). В то время как объем переданных данных в стандартном TCP-соединении падает с ростом RTT, TCP Hybla демонстрирует характеристики близкие к эталонным.
Так как пригодность предлагаемого подхода уже продемонстрирована, давайте рассмотрим, какую динамику окна перегрузки для Hybla можно получить, модифицировав правила задания значения окна перегрузки следующим образом:
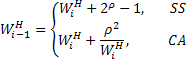 (V)
(V)
поддерживая механизм управления окном перегрузки с помощью откликов ACK. SS - Slow Start. Заметим, что правила модификации на фазе CA (congestion avoidance - исключение перегрузки), являются теми же, что и для случая постоянной скорости передачи [14], которая, впрочем, не учитывает фазу медленного старта. Другим важным отличием является то, что в практических реализациях (V) TCP Hybla устанавливает минимальное значение r равным 1. Таким образом, TCP Hybla работает как стандартный TCP для быстрых каналов (т.e. соединение с RTT≤RTT0, которые поддерживают стандартную скорость роста. Кроме того в (IV), как исходное значение cwnd, так и ssthresh должны умножаться на r, это же относится и к размеру буфера. Наконец, заметим, что выражения (III) и (IV) справедливы в предположении, что отправитель ограничен окном перегрузки. Если это предположение не выполняется, ограничение, накладываемое принимающей стороной, может быть снято путем увеличения значения window умноженного на r, гарантируя идентичное верхнее значение скорости передачи для всех соединений. Заметим однако, что эта модификация принимающей стороны не является обязательной.
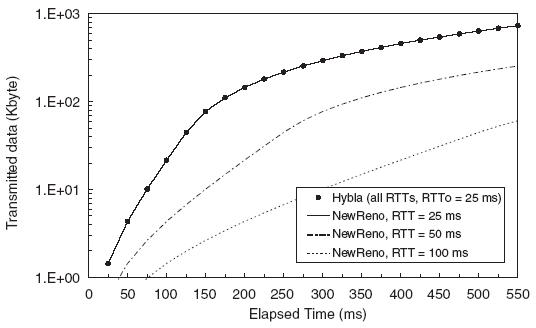
Рис. 8. Сравнение TCP Hybla со стандартным TCP: передача данных при нескольких значениях RTT для канала без потерь.

Рис. 9. Несовершенство версии протокола TCP Newreno для каналов с разными значениями RTT
BIC TCP (Binary Increase Congestion) является реализацией TCP с оптимизацией алгоритма управления перегрузкой для сетей с большими задержками: так называемые "длинные широкополосные сети".
BIC TCP реализован и используется в ядре Linux версии 2.6.8 и выше. По умолчанию модель реализации протокола была заменена на CUBIC TCP в версии 2.6.19.
Ниже следующий текст в заметной мере базируется на статье Sangtae Ha, Injong Rhee, Lisong Xu, "CUBIC: A New TCPFriendly HighSpeed TCP Variant".
CUBIC представляет собой реализацию протокола TCP с оптимизацией алгоритма управления перегрузкой для быстродействующих сетей с большими задержками (LFN: длинные широкополосные сети).
Версия CUBIC является менее агрессивной и более системной, чем BIC TCP, в которой значение ширины окна является кубичной функцией времени после последнего события перегрузки, с точкой перегиба, привязанной к окну, а не к событию как раньше.
CUBIC TCP был реализован для ядра Linux версии 2.6.19 и выше (2006 год).
Так как в Интернет существует много скоростных протяженных сегментов, для протокола постоянно возникают проблемы. Такие сети характеризуются большим произведением полосы на задержку BDP (bandwidth and delay product). В таких сетях для полного использования полосы большое число пакетов должно быть в пути, т.е. размер окна перегрузки должен быть большим. В стандартном TCP, например, TCP-Reno, TCP-NewReno и TCP-SACK, окно увеличивается один раз за RTT. Это делает передачу данных в рамках протокола TCP, используемого в большинстве операционных систем, включая Windows и Linux, достаточно вялой, не использующей всю имеющуюся полосу пропускания. Это особенно характерно для коротких сессий, где окно не успевает даже приблизиться к оптимальному значению. Например, если полоса фрагмента сети равна 10 Гбит/c, а RTT = 100 мсек, при длине пакетов 1250 байт, BDP сегмента будет составлять примерно 100,000 пакетов. Для TCP, чтобы довести окно со значения 50,000 до 100000 потребуется около 50,000 RTT, что составляет 5000 секунд (1.4 часа). Если сессия завершится раньше, полоса канала будет существенным образом недоиспользована.
Модель BIC-TCP обеспечивает хорошую масштабируемость для скоростных сетей, эквивалентность для конкурирующих потоков и стабильность с низким уровнем осцилляций размера окна. Однако функция роста окна BIC-TCP может быть слишком агрессивной для TCP, в особенности при малых значениях RTT или для низкоскоростных сетей. Более того, несколько фаз (двоичный поисковый рост, поиск max, Smax и Smin) управления окном добавляет излишнюю сложность в реализацию протокола и анализ его рабочих характеристик. Предложенная модель CUBIC TCP лишена многих недостатков BIC TCP.
В модели CUBIC используется кубичная функция роста окна, которая по форме очень близка к соответствующей функции BIC-TCP. В CUBIC при реализации функции роста окна используется время, прошедшее с момента последнего события перегрузки. В то время как большинство моделей реализации стандартного TCP используют выпуклые функции роста после потери пакета, CUBIC использует как выпуклые, так и вогнутые профили кубической функции роста окна . На рис. 10 показана эволюция окна в BIC (a) и CUBIC (b).
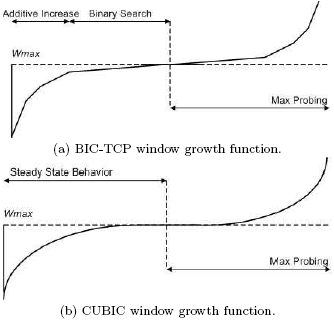
Рис. 10. Функция роста окна для BIC-TCP и CUBIC
После уменьшения размера окна при потере пакета, записывается значение окна Wmax, которое оно имело в момент потери, и уменьшаетсяразмер окна в b раз, где b равно постоянной уменьшения окна TCP. После этого система переходит из режима быстрого восстановления в режим исключения перегрузки, начинается увеличение окна с использованием вогнутого профиля кубической функции. Кубическая функция параметризована так, чтобы ее плато приходилось на Wmax, так что вогнутый рост продолжается до тех пор пока ширина окна не станет равным Wmax. После этого, кубическая функция становится выпуклой. Такой способ подстройки ширины окна (вогнутый, а затем выпуклый) улучшает протокол и сетевую стабильность, сохраняя высокий уровень использования полосы канала [12]. Это происходит потому, что размер окна остается почти постоянным, образуя плато в области Wmax, где уровень использования сети считается высоким и стабильным.
Рост окна в модели CUBIC осуществляется в соответствии с выражением:
W(t) = C(t-K)3 + Wmax (1)
где C параметр CUBIC, t - время с момента последнего уменьшения ширины окна, а K равно периоду времени, который необходим для увеличения W до Wmax, его значение вычисляется с привлечением выражения:
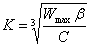 (2)
(2)При получении подтверждения ACK на фазе исключения перегрузки, CUBIC вычисляет скорость роста ширины окна за время последующего RTT-периода, используя выражение (I). Программа устанавливает значение W(t + RTT) в качестве вероятной величины окна перегрузки. Предположим, что ширина окна равна cwnd. В зависимости от его значения, CUBIC реализует три разных режима. Если cwnd меньше чем размер окна, который был бы достигнут в стандартном TCP, спустя время t после последнего случая потери, тогда CUBIC оказывается в TCP-режиме (как определить этот размер окна в зависимости от t будет описано ниже). В противном случае, если cwnd меньше Wmax, тогда CUBIC находится в вогнутой области, и если cwnd больше Wmax, CUBIC находится в выпуклой области функции роста. Алгоритм 1 представлен в псевдопрограммном виде для варианта Linux.

a и множитель b образуют следующую функцию:
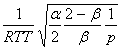 (3)
(3)С помощью аналогичного анализа получается среднее значение ширины окна TCP с a = 1 и b = 0.5 равное 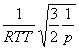 . Таким образом, для равенства (3), которое является аналогичным со случаем TCP, a должна быть равна
. Таким образом, для равенства (3), которое является аналогичным со случаем TCP, a должна быть равна  . Если TCP
увеличивает свое окно на каждый период RTT, мы можем получить размер окна TCP, выраженное через t:
. Если TCP
увеличивает свое окно на каждый период RTT, мы можем получить размер окна TCP, выраженное через t:
 (4)
(4) Если cwnd меньше Wtcp(t), тогда протокол находится в режиме TCP, cwnd делается равным Wtcp(t) при каждом получении подтверждения ACK. Сubic TCP friendliness() в алгоритме 1 описывает это поведение. Рис. 11 позволяет сравнить характеристики стандартной модели ТСР с HSTCP и CUBIC.

Рис. 11. Функции отклика для стандартов TCP, HSTCP и CUBIC в сетях с RTT 10 мсек (a) и 100 мсек (b) соответственно.
На рис. 12 показано, как могут конкурировать друг с другом два потока CUBIC при RTT=246 мсек.
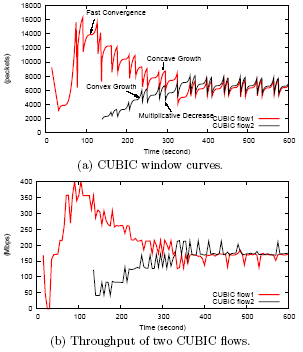
Рис. 12. Two CUBIC flows with 246ms RTT
Более подробное описание модели протокола CUBIC TCP можно найти в статье, ссылка на которую помещена в начале этого раздела.
Среднее значение окна в CUBIC можно оценить из формулы:
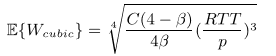 (4)
(4) TCP-Illinois [26] использует задержку в очереди, чтобы определить коэффициент увеличения a и мульикативный коэффициент уменьшения b во время фазы увеличения окна. Точнее, TCP-Illinois устанавливает большое значение a и малое b, когда средняя задержка d мала. Задержка является указателем того, что перегрузка не ожидается, и устанавливает малое a и большое b, когда d велико, что индицирует приближение перегрузки.
TCP-Veno [17] определяет размер окна перегрузки очень схоже с TCP-NewReno, но он использует информацию о задержках TCP-Vegas, чтобы выделить потери не связанные с перегрузкой. Когда происходит потеря пакета, если размер очереди, определяемый по задержке, находится ниже заданного порога, что указывает на случайную потерю, TCP-Veno уменьшает окно перегрузки на 20%, а не на 50%.
2018 TCP Selective Acknowledgement Options. M. Mathis, J. Mahdavi, S. Floyd, A. Romanow. October 1996.
2042 Registering New BGP Attribute Types. B. Manning. January 1997.
2126 ISO Transport Service on top of TCP (ITOT). Y. Pouffary, A. Young. March 1997.
2140 TCP Control Block Interdependence. J. Touch. April 1997.
2309 Recommendations on Queue Management and Congestion Avoidance in the Internet. B. Braden, D. Clark, J. Crowcroft, B. Davie, S. Deering, D. Estrin, S. Floyd, V. Jacobson, G. Minshall, C. Partridge, L. Peterson, K. Ramakrishnan, S. Shenker, J. Wroclawski, L. Zhang. April 1998.
2398 Some Testing Tools for TCP Implementors. S. Parker, C. Schmechel. August 1998. (Also FYI0033)
2414 Increasing TCP's Initial Window. M. Allman, S. Floyd, C. Partridge. September 1998.
2415 Simulation Studies of Increased Initial TCP Window Size. K. Poduri, K. Nichols. September 1998.
2416 When TCP Starts Up With Four Packets Into Only Three Buffers. T. Shepard, C. Partridge. September 1998.
2488 Enhancing TCP Over Satellite Channels using Standard Mechanisms. M. Allman, D. Glover, L. Sanchez. January 1999. (Also BCP0028)
2525 Known TCP Implementation Problems. V. Paxson, M. Allman, S. Dawson, W. Fenner, J. Griner, I. Heavens, K. Lahey, J. Semke, B. Volz. March 1999.
2581 TCP Congestion Control. M. Allman, V. Paxson, W. Stevens. April 1999.
2582 The NewReno Modification to TCP's Fast Recovery Algorithm. S. Floyd, T. Henderson. April 1999.
2675 IPv6 Jumbograms. D. Borman, S. Deering, R. Hinden. August 1999.
2760 Ongoing TCP Research Related to Satellites. M. Allman, Ed., S. Dawkins, D. Glover, J. Griner, D. Tran, T. Henderson, J. Heidemann, J. Touch, H. Kruse, S. Ostermann, K. Scott, J. Semke. February 2000.
2760 Ongoing TCP Research Related to Satellites. M. Allman, Ed., S. Dawkins, D. Glover, J. Griner, D. Tran, T. Henderson, J. Heidemann, J. Touch, H. Kruse, S. Ostermann, K. Scott, J. Semke. February 2000.
2873 TCP Processing of the IPv4 Precedence Field. X. Xiao, A. Hannan, V. Paxson, E. Crabbe. June 2000.
2883 An Extension to the Selective Acknowledgement (SACK) Option for TCP. S. Floyd, J. Mahdavi, M. Mathis, M. Podolsky. July 2000.
2923 TCP Problems with Path MTU Discovery. K. Lahey. September 2000.
2988 Computing TCP's Retransmission Timer. V. Paxson, M. Allman. November 2000.
3042 Enhancing TCP's Loss Recovery Using Limited Transmit. M. Allman, H. Balakrishnan, S. Floyd. January 2001.
3081 Mapping the BEEP Core onto TCP. M. Rose. March 2001.
3168 The Addition of Explicit Congestion Notification (ECN) to IP. K. Ramakrishnan, S. Floyd, D. Black. September 2001.
3293 General Switch Management Protocol (GSMP) Packet Encapsulations for Asynchronous Transfer Mode (ATM), Ethernet and Transmission Control Protocol (TCP). T. Worster, A. Doria, J. Buerkle. June 2002.
3390 Increasing TCP's Initial Window. M. Allman, S. Floyd, C. Partridge. October 2002.
3448 TCP Friendly Rate Control (TFRC): Protocol Specification. M. Handley, S. Floyd, J. Padhye, J. Widmer. January 2003.
3449 TCP Performance Implications of Network Path Asymmetry. H. Balakrishnan, V. Padmanabhan, G. Fairhurst, M. Sooriyabandara. December 2002.
3465 TCP Congestion Control with Appropriate Byte Counting (ABC). M. Allman. February 2003
3481 TCP over Second (2.5G) and Third (3G) Generation Wireless Networks. H. Inamura, Ed., G. Montenegro, Ed., R. Ludwig, A. Gurtov, F. Khafizov. February 2003.
3517 A Conservative Selective Acknowledgment (SACK)-based Loss Recovery Algorithm for TCP. E. Blanton, M. Allman, K. Fall, L. Wang. April 2003.
3522 The Eifel Detection Algorithm for TCP. R. Ludwig, M. Meyer. April 2003.
3708 Using TCP Duplicate Selective Acknowledgement (DSACKs) and Stream Control Transmission Protocol (SCTP) Duplicate Transmission Sequence Numbers (TSNs) to Detect Spurious Retransmissions. Blanton, E. and M. Allman, February 2004.
3782 The NewReno Modification to TCP's Fast Recovery Algorithm. Floyd, S., Henderson, T., and A. Gurtov. April 2004.
UP:
4.4.3 Протокол TCP |



