|
Previous: 4.5.16 Некоторые другие процедуры Интернет
UP:
4.5 Процедуры Интернет |
|
Previous: 4.5.16 Некоторые другие процедуры Интернет
UP:
4.5 Процедуры Интернет |
4.5.17 Сетевое моделирование
Семенов Ю.А. (ГНЦ ИТЭФ)
| Аналитическое моделирование |
| Симуляционное моделирование |
| Моделирование сети с помощью процессов (тредов) |
Ни один проект крупной сети со сложной топологией в настоящее время не обходится без исчерпывающего моделирования будущей сети (речь, разумеется, идет не о России). Программы, выполняющие эту задачу, достаточно сложны и дороги. Целью моделирования является определение оптимальной топологии, адекватный выбор сетевого оборудования, определение рабочих характеристик сети и возможных этапов будущего развития. Ведь сеть, слишком точно оптимизированная для решений задач текущего момента, может потребовать серьезных переделок в будущем. На модели можно опробовать влияние всплесков широковещательных запросов или реализовать режим коллапса (для Ethernet), что вряд ли кто-то может себе позволить в работающей сети. В процессе моделирования выясняются следующие параметры:
Перечисленные задачи предъявляют различные требования к программам. В одних случаях достаточно провести моделирование на физическом (MAC) уровне, в других нужен уже уровень транспортных протоколов (например, UDP и TCP), а для наиболее сложных задач нужно воспроизвести поведение прикладных программ. Все это должно учитываться при выборе или разработке моделирующей программы. Ведь нужно учесть, что ваша машина должна в той или иной мере воспроизвести действия всех машин в моделируемой сети. Таким образом, машина эта должна быть достаточно быстродействующей и, несмотря на это, моделирование одной секунды работы сети может занять при определенных условиях не один час.
Результаты моделирования должны иметь точность 10-20%, так как этого достаточно для большинства целей и не требует слишком много машинного времени. Следует иметь в виду, что для моделирования поведение реальной сети, надо знать все ее рабочие параметры: длины кабеля от концентратора до конкретной ЭВМ, задержки используемых кабелей, задержки концентраторов (этот параметр часто отсутствует в документации и его придется брать из документации на сетевой протокол, например из IEEE 802.3). Параметры могут быть определены и прямым измерением. Чем точнее вы воспроизводите поведение сети, тем больше машинного времени это потребует. Кроме того, вам предстоит сделать некоторые предположения относительно распределения загрузки для конкретных ЭВМ и других сетевых элементов, задержек в переключателях, мостах, времени обработки запросов в серверах. Здесь нужно учитывать и характер решаемых на ЭВМ задач. www/ftp-сервер или обычная персональная рабочая станция создают различные сетевые трафики. Определенное влияние на результат могут оказывать и используемые ОС. В случае моделирования реальной сети можно произвести соответствующие измерения, что иногда тоже не слишком просто. Учитывая сложность моделирования на одной ординарной ЭВМ, следует ограничиваться моделированием не более чем одной минуты для каждого из наборов параметров (этого времени достаточно для копирования практически любого файла через локальную сеть). Исключение может составлять моделирование внешнего трафика, но в этом случае весь локальный трафик должен рассматриваться как фоновый.
Определение характеристик сети до того, как она будет введена в эксплуатацию, имеет первостепенное значение. Это позволяет отрегулировать характеристики локальной сети на стадии проектирования. Решение этой проблемы возможно путем аналитического или статистического моделирования. Для реализации такого моделирования можно использовать общедоступные пакеты NS-2 или программа моделирования NS-2, или Macedon.
Аналитическая модель сети представляет собой совокупность математических соотношений, связывающих между собой входные и выходные характеристики сети. При выводе таких соотношений приходится пренебрегать какими-то малосущественными деталями или обстоятельствами.
Телекоммуникационная сеть при некотором упрощении может быть представлена в виде совокупности процессоров (узлов), соединенных каналами связи. Сообщение, пришедшее в узел, ждет некоторое время до того, как оно будет обработано. При этом может образоваться очередь таких сообщений, ожидающих обработки. Время передачи или полное время задержки сообщения d равно:
D = Tp + S + W,
где Tp, S и W, соответственно, время распространения, время обслуживания и время ожидания. Одной из задач аналитического моделирование является определение среднего значения D. При больших загрузках основной вклад дает ожидание обслуживания W. Для описания очередей в дальнейшем будет использована нотация Д. Дж. Кенделла: A/B/C/K/m/z,
где А - процесс прибытия: В - процесс обслуживания; С - число серверов (узлов); К - максимальный размер очереди (по умолчанию -  ); m - число клиентов (по умолчанию - ); z - схема работы буфера (по умолчанию FIFO). Буквы А и В представляют процессы прихода и обслуживания и обычно заменяются следующими буквами, характеризующими закон, соответствующий распределения событий.
); m - число клиентов (по умолчанию - ); z - схема работы буфера (по умолчанию FIFO). Буквы А и В представляют процессы прихода и обслуживания и обычно заменяются следующими буквами, характеризующими закон, соответствующий распределения событий.
D - постоянная вероятность;
M - марковское экспоненциальное распределение;
G - обобщенный закон распределения;
Ek - распределение Эрланга порядка k;
Hk - гиперэкспоненциальное распределение порядка k;
Наиболее распространенными схемами работы буферов являются FIFO (First-In-First-Out), LIFO (Last-In-First-Out) и FIRO (First-In-Random-Out). Например, запись M/M/2 означает очередь, для которой времена прихода и обслуживания имеют экспоненциальное распределение, имеется два сервера, длина очереди и число клиентов могут быть сколь угодно большими, а буфер работает по схеме FIFO. Среднее значение длины очереди Q при заданной средней входной частоте сообщений l и среднем времени ожидания W определяется на основе теоремы Литла (1961):
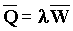
Для варианта очереди M/G/1 входной процесс характеризуется распределением Пуассона со скоростью поступления сообщений l. Вероятность поступления k сообщений на вход за время t равно:
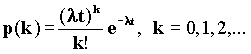
Пусть N - число клиентов в системе, Q - число клиентов в очереди и пусть вероятность того, что входящий клиент обнаружит j других клиентов, равна:
Пj = P[n=j], j=0,1,2,… 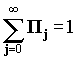 ; П0 = 1- r; r = lt;
; П0 = 1- r; r = lt;
Тогда среднее время ожидания w:
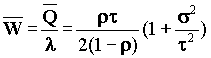 (формула Поллажека-Хинчина)
(формула Поллажека-Хинчина)
s - среднеквадратичное отклонение для распределения времени обслуживания.
Для варианта очереди M/G/1 H(t) = P[X≤ t] = 1 - e-mt (H - функция распределения времени обслуживания). Откуда следует s2 = t2.
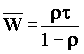
Для варианта очереди m/d/1 время обслуживания постоянно, а среднее время ожидания составляет:
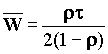
Аналитическая модель для сетей Ethernet (CSMA-CD) разработана Лэмом (S.S.Lam: “A Carrier Sense Multiple Access Protocol for Local Networks,” Computer Networks, vol. 4, n. 1, pp. 21-32, January 1980). Здесь предполагается, что сеть состоит из бесконечного числа станций, соединенных каналами с доменным доступом. То есть станция может начать передачу только в начале какого-то временного домена. Распределение сообщений подчиняется закону Пуассона с постоянной скоростью следования l. Среднее значение времени ожидания для таких сетей составляет:

где е - основание натурального логарифма, t - задержка распространения сигнала в сети. 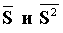 , соответственно первый и второй моменты распределения передачи или обслуживания сообщения. f(l) преобразование Лапласа для распределения времени передачи сообщения. Следовательно
, соответственно первый и второй моменты распределения передачи или обслуживания сообщения. f(l) преобразование Лапласа для распределения времени передачи сообщения. Следовательно
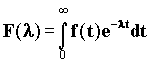 , а для сообщений постоянной длины f(l)=e-r
, а для сообщений постоянной длины f(l)=e-r 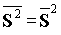 , где
, где  . Для экспоненциального распределения длин сообщений:
. Для экспоненциального распределения длин сообщений:
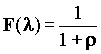 ,
, 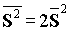 .
.
Рассмотрим вариант сети Ethernet на основе концентратора-переключателя с числом каналов N. При этом будет предполагаться, что сообщения на входе всех узлов имеют пуассоновское распределение со средней интенсивностью li, распределение сообщений по длине произвольно. Сообщения отправляются в том же порядке, в котором они прибыли. Трафик в сети предполагается симметричным. Очередь имеет модель M/G/1. Среднее время ожидания в этом случае равно:
 ,
,
где 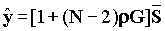 ,
,
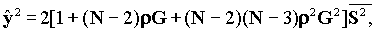

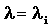 , а G=1/(N-1) равно вероятности того, что сообщение отправителя i направлено получателю j. Требование стабильности
rЈ 1 требует, чтобы
, а G=1/(N-1) равно вероятности того, что сообщение отправителя i направлено получателю j. Требование стабильности
rЈ 1 требует, чтобы 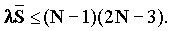 Для больших n это приводит к
Для больших n это приводит к  .
.
Среднее время распространения сообщения в сети равно 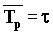 , где t равно RTT.
, где t равно RTT.
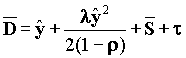
Симуляционное (статистическое) моделирование служит для анализа системы с целью выявления критических элементов сети. Этот тип моделирование используется также для предсказания будущих характеристик системы. Такое моделирование может осуществляться с использованием специализированных языков симулирования и требует априорного знания относительно статистических свойств системы в целом и составляющих ее элементов. Процесс моделирования включат в себя формирование модели, отладку моделирующей программы и проверку корректности выбранной модели. Последний этап обычно включает в себя сравнение расчетных результатов с экспериментальными данными, полученными для реальной сети.
При статистическом моделировании необходимо задать ряд временных характеристик, например:
| Системное время | Интервал от момента генерации сообщения до получения его адресатом, включая ожидание в очереди |
| Время ожидания | Промежуток от приема сообщения сетевым интерфейсом до обработки его процессором |
| Время распространения | Задержка передачи сообщения от одного сетевого интерфейса до другого |
| Время передачи | Задержка пересылки сообщения от одного процессора до другого |
Полный список таких временных характеристик включает в себя значительно больше величин.
В процессе моделирования рассчитываются следующие параметры:
| Статистика очередей |
| Средняя длина очереди |
| Пиковая длина очереди |
| Среднеквадратичное отклонение длины очереди от среднего значения |
| Статистика времени ожидания |
| Среднее время ожидания |
| Максимальное время ожидания |
| Среднеквадратичное отклонение времени ожидания |
| Статистика системного времени |
| Среднее системное время |
| Максимальное системное время |
| Среднеквадратичное отклонение системного времени |
| Полное число сообщений в статистике системного времени |
| Пиковое значение числа системных сообщений |
| Среднеквадратичное отклонение числа системных сообщений |
| Статистика потерь сообщений |
| Полное число потерянных сообщений |
| Частота потери сообщений |
| Доля потерь из-за переполнения очереди |
| Доля потерь из-за таймаутов |
Разумеется, реальный перечень вычисляемых параметров может быть существенно шире и определяется конкретными целями расчетов. Рассмотрим частную задачу определения среднего числа связей между процессорами (узлами). Предполагается, что полное число узлов равно N, а схема соединения узлов соответствует изображенной на рис. 4.5.7.1.

Рис. 4.5.7.1.
Среднее расстояние от произвольного узла до всех остальных узлов равно D(N+1)/3, где D - расстояние между соседними узлами (предполагается константой).
Возможны разные подходы к моделированию. Классический подход заключается в воспроизведении событий в сети как можно точнее и поэтапное моделирование последствий этих событий. В реальной жизни события могут происходить одновременно в различных точках сети. По этой причине для моделирования идеально подошел бы многопроцессорный компьютер, где можно воспроизводить любое число процессов одновременно. В любом случае необходимо выбрать некоторый постоянный временной интервал и считать, что события произошли одновременно, если расстояние между ними меньше этого интервала. Для сетей типа ethernet таким временным интервалом может быть бит-тайм (для 10-мегагбитного ethernet это 100нс). Понятно, что это уже отступление от реальности (ведь задержки в сетевом кабеле не кратны этому времени), но не слишком значительное. Надо сказать, что такого рода предположений при моделировании приходится делать много. По этой причине крайне важно сравнивать результаты моделирования с данными, полученными для реальной сети. Если отличия лежат в пределах 10-20%, можно считать, что сделанные предположения не увели программу слишком далеко от жизни и ею можно пользоваться для расчетов. Рассмотренный выше подход пригоден для моделирования сетевого коллапса, так как скорость расчетов здесь зависит от числа узлов и почти не зависит от сетевой загрузки.
Другим подходом может стать метод, где для каждого логического сегмента (зоны столкновений) сначала моделируется очередь событий. При этом в каждой рабочей станции моделируется последовательность пакетов, ожидающих отправки. Эта очередь может время от времени модифицироваться, например, при получении ЭВМ пакета извне и необходимости послать на него отклик. После того как такая очередь для каждого сетевого объекта (сюда помимо ЭВМ входят мосты, переключатели и маршрутизаторы) построена, запускается программа отправки пакетов. При этом выбирается самый первый по времени пакет (ожидающий дольше других) и проверяются для него условия начала передачи (отсутствие несущей на входе сетевого интерфейса в данный момент и в течение 9,6 мксек до рассматриваемого момента - 96 тайм-битов). Если условия отправки выполнены, он “посылается” в сеть. Вычисляются моменты достижения им всех узлов данного логического сегмента, проверяются условия его столкновения с другими пакетами. Следует заметить, в этом подходе снимаются ограничения “дискретности” временной шкалы, использованной в предыдущем “классическом” подходе. Этот подход позволяет заметно ускорить расчеты при большом числе узлов, но малой загрузке сети. Проблемы реализации данной концепции моделирования связаны с обслуживанием довольно сложного списка, описывающего очередь пакетов, ожидающих отправки. В структуру этого списка включается и описание ситуации в сети на данный временной период. Дополнительные трудности сопряжены с поведением мостов, переключателей и маршрутизаторов, так как они могут вставлять в очередь дополнительные элементы, требующие немедленного обслуживания. Аналогичные вставки в очередь будут вызывать полученные станцией пакеты ICMP или TCP, требующие откликов. Причем такое вставление в очередь асинхронно по отношению к процедуре “отправки” пакетов. Очередь для всей локальной сети может быть единой, тогда пакеты разных логических сегментов должны быть помечены определенными флагами. При переходе из сегмента в сегмент флаг будет меняться. Возможно и построение независимых очередей для каждого из логических сетевых сегментов.
Данный метод был использован студентом ТСС МФТИ Алексеем Овчаровым в его магистрской диссертации (2000 год) для определения свойств фрагмента сети в условиях, близких к предельным (загрузка на уровне 70-100%). Такие режимы трудно реализовать на практике без нанесения серьезного ущерба клиентам сети. Результаты расчета представлены на рис. 4.5.7.2.

Рис. 4.5.7.2. Зависимость вероятности потери пакета в процентах от загрузки фрагмента сети
В рамках ядра Linux можно сформировать треды, воспроизводящие работу маршрутизаторов, переключателей, сервера или рабочих станций. При этом в такой виртуальной сети внутри ядра Linux можно организовать любые обмены, воспроизвести любой, в том числе нестандартный транспортный протокол, задать любой в уровень перегрузки каналов, любую схему организации очередей. Полоса канала может быть определена с помощью алгоритма маркерное ведро. Если мощности одной машины недостаточно, можно подключить еще одну или более машин, чтобы моделировать более сложную сеть. Привлекательность этого метода заключается в том, что треды работают точно та же как обычные сетевые устройства. В качестве же программ используются модифицированные модули сетевых демонов. К минусам метода можно отнести сложность программирования в рамках ядра Linux.
Целью моделирования является определение зависимости пропускной способности сети и вероятности потери пакета от загрузки, числа узлов в сети, длины пакета и размера области столкновений.
Исходные данные о структуре и параметрах сети берутся из базы данных. Ряд параметров сети задаются конфигурационным файлом (профайлом). Сюда могут записываться емкость буфера интерфейса и драйвера, время задержки обработки запроса (хотя в общем случае эта величина может также иметь распределение) и т.д.. К таким параметрам относятся также: MTU, MSS, TTL, window, некоторые значения таймаутов и т.д.
Сеть разбивается на логические сегменты (зоны столкновений), в каждой из которых работает независимая синхронизация процессов (хотя эти процессы и влияют друг на друга через мосты, переключатели и маршрутизаторы).
Полное моделирование сети с учетом рабочих приложений предполагает использование следующих распределений:
Последние два пункта существенным образом коррелированы с первым, так как используемые протоколы зависят от приложения, а активность узла может определяться, например длиной пересылаемого файла. По этой причине при полномасштабном моделировании сначала определяется, что собирается делать рабочая станция или сервер, (с учетом распределения по приложениям определяется характер задачи: FTP, MS explorer и т.д.). После этого разыгрываются параметры задания (длина файла, удаленность объекта и пр.), а уже на основе этого формируется фрагмент очереди пакетов.
Задача первого этапа: проверка пропускной способности при вариации загрузки и длин пакетов, подсчет числа столкновений, проверка влияния размера буфера сетевого интерфейса на пропускную способность (влияние размера буфера переключателей по пути до адресата).
Исходные данные для первого этапа:
Структура описания каждого из узлов включает в себя (формируется с учетом будущего расширения):
Формат описания топологии сети (список)
Элемент списка:
Процесс посылки пакета включает в себя (в соответствии с требованиями документа IEEE 802.3):
Попытка начала передачи предполагает проверку:
Процесс приема предполагает:
Центральный менеджер осуществляет:
Вариант 1 (равномерное распределение по времени)
Для каждого узла устанавливается определенная средняя частота посылки пакетов. Время посылки предполагается случайным. Средняя частота может быть задана равной для всех узлов. Так как минимальный размер пакета равен 64 байт (51.2 мксек=512 бит-тактов), максимальная частота посылки пакетов составляет ~19.5 кГц.
Минимальный средний период посылки пакетов определяется в бит-тактах и должен быть больше 512 бит-тактов. Понятно, что пока узел осуществляет передачу, он не может пытаться передать новый пакет (многозадачные, многопользовательские системы с несколькими сетевыми интерфейсами пока рассматривать не будем). По этой причине частота посылки пакетов однозначно определяется паузой между концом предыдущего пакета и началом нового (d). Среднее значение периода посылки пакетов равно Тпакета+96(бит-тактов)+d (значение d величина статистическая). Для каждого узла задается значение d (сначала равное для всех узлов). Если предположить равномерное распределение вероятности (передача пакета может начаться в любой бит-такт с равной вероятностью).
При определении того, пытаться ли начинать передачу в данный бит-такт будет проверка условия:
rndm<1/d (выполнение условия предполагает попытку начала передачи).
Если вероятность прихода n пакетов на время t распределена по закону Пуассона:
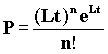 , где L -
средняя частота следования событий, то реальное время между событиями t может быть определено как t = -T ln(R). R - случайное число 0≤
R ≤ 1, а T = 1/L.
, где L -
средняя частота следования событий, то реальное время между событиями t может быть определено как t = -T ln(R). R - случайное число 0≤
R ≤ 1, а T = 1/L.
Результатами моделирования могут являться (фиксируются отдельно для каждого набора входных параметров):
| 1. | Вероятность потери пакета для логического сегмента и каждой из рабочих станций. |
| 2. | Пропускная способность серверов для каждого из логических сегментов (путь сервер -> логический сегмент) |
| 3. | Вероятность столкновения для каждого логического сегмента и каждой рабочей станции. |
| 4. | Распределение потоков по логическим сегментам (и рабочим станциям) независимо для каждого направления (вход и выход). |
| 5. | Распределение потоков для всех входов/выходов переключателей мостов и маршрутизаторов. |
| 6. | Доля вспомогательного трафика (ICMP, SNMP, отклики TCP, широковещательные запросы и т.д.) по отношению к информационному потоку для различных узлов сети (серверов, маршрутизаторов) |
| 7. | Уровень широковещательного трафика для каждого из логических сегментов |
Previous: 4.5.16 Некоторые другие процедуры Интернет
UP:
4.5 Процедуры Интернет |




