|
Previous: 4.5.13 Система поиска файлов Archie
UP:
4.5 Процедуры Интернет |
|
Previous: 4.5.13 Система поиска файлов Archie
UP:
4.5 Процедуры Интернет |
4.5.14 Современные поисковые системы
Семенов Ю.А. (ГНЦ ИТЭФ)

| Знай я тогда то, что знаю сейчас, сейчас бы я этого не знал... Станислав Ежи Лец, "Непричесанные мысли" |
| Стоп-списки (stop-list) |
| Базовые процессы поискового сервера |
| Функция файла robots.txt |
| Проблема релевантности документа |
| Кластерные методы |
| Список литературы |
Развитие Интернет начиналось как средство общения и удаленного доступа (электронная почта, telnet, FTP). Но постепенно эта сеть превратилась в средство массовой информации, отличающееся тем, что операторы сети сами могут быть источниками информации и определяют, в свою очередь то, какую информацию они хотят получить.
Среди первых поисковых систем были archie, gopher и wais. Эти относительно простые системы казались тогда чудом. Использование этих систем показало их недостаточность и определенные врожденные недостатки: ограниченность зоны поиска и отсутствие управления этим процессом. Поиск проводился по ограниченному списку серверов и никогда не было известно, насколько исчерпывающую информацию получил клиент.
Следующим шагом возможно станут семантические сети и использование контекста. Такие поисковые системы могут стать основой мощных информационных систем.
Первые WWW-системы работали в режиме меню (Mosaic появилась несколько позже) и обход дерева поиска производился вручную. Структура гиперсвязей могла иметь циклические пути, как, например, на рис. 4.5.14.1. Число входящих и исходящих гиперсвязей для любого узла дерева может быть произвольным.
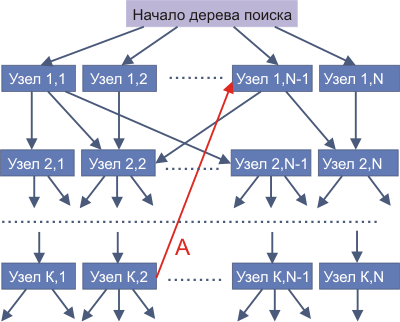
Рис. 4.5.14.1. Пример дерева гиперсвязей
Гиперсвязь, помеченная буквой А (стрелка красного цвета), может явиться причиной образования цикла при обходе дерева. Исключить такие связи невозможно, так как они носят принципиально смысловой характер. По этой причине любая автоматизированная программа обхода дерева связей должна учитывать такую возможность и исключать циклы обхода.
Задача непроста даже в случае поиска нужного текста в пределах одного достаточно большого по емкости диска, когда вы заранее не знаете или не помните в каком субкаталоге или в каком файле содержится искомый текст. Для облегчения ручного поиска на серверах FTP в начале каждого субкаталога размещается индексный файл.
Для решения этой задачи в большинстве операционных систем имеются специальные утилиты (например, grep для UNIX). Но даже они требуют достаточно много времени, если, например, дисковое пространство лежит в пределах нескольких гигабайт, а каталог весьма разветвлен. В полнотекстных базах данных для ускорения поиска используется индексация по совокупности слов, составляющих текст. Хотя индексация также является весьма времяемкой процедурой, но производить ее, как правило, приходится только один раз. Проблема здесь заключается в том, что объем индексного файла оказывается сравным (а в некоторых случаях превосходит) с исходным индексируемым файлом. Первоначально каждому документу ставился в соответствие индексный файл, в настоящее время индекс готовится для тематической группы документов или для поисковой системы в целом. Такая схема индексации экономит место в памяти и ускоряет поиск. Для документов очень большого размера может использоваться отдельный индекс, а в поисковой системе иерархический набор индексов. Индексированием называется процесс перевода с естественного языка на информационно-поисковый язык. В частности, под индексированием понимается отнесение документа в зависимости от содержимого к определенной рубрике некоторой классификации. Индексирование можно свести к проблеме распознавания образов. Классификация определяет разбиение пространства предметных областей на непересекающиеся классы. Каждый класс характеризуется набором признаков и специфических для него терминов (ключевых слов), выражающих основные понятия и отношения между ними.
Слова в любом тексте в информационном отношении весьма неравнозначны. И дело не только в том, что текст содержит много вспомогательных элементов предлогов или артиклей (напр., в англоязычных текстах). Часто для сокращения объема индексных регистров и ускорения самого процесса индексации вводятся так называемые стоп-листы. В эти стоп-листы вносятся слова, которые не несут смысловой нагрузки (например, предлоги или некоторые вводные слова). Но при использовании стоп-листов необходима определенная осторожность. Например, занеся в стоп-лист, неопределенный артикль английского языка "а", можно заблокировать нахождение ссылки на "витамин А".
Немалое влияние оказывает изменяемость слов из-за склонения или спряжения. Последнее делает необходимым лингвистический разбор текста перед индексацией. Хорошо известно, что смысл слова может меняться в зависимости от контекста, что также усложняет проблему поиска. Практически все современные информационные системы для создания и обновления индексных файлов используют специальные программные средства.
Существующие поисковые системы успешно работают с HTML-документами, с обычными ASCII-текстами и новостями usenet. Трудности возникают для текстов Winword и даже для текстов Postscript. Связано это с тем, что такие тексты содержат большое количество управляющих символов и текстов. Трудно (практически невозможно) осуществлять поиск для текстов, которые представлены в графической форме. К сожалению, к их числу относятся и математические формулы, которые в HTML имеют формат рисунков (это уже недостаток самого языка). Так что можно без преувеличения сказать, что в этой крайне важной области, имеющей немалые успехи, мы находимся лишь в начале пути. Ведь море информации, уже загруженной в Интернет, требует эффективных средств навигации. Ведь оттого, что информации в сети много, мало толку, если мы не можем быстро найти то, что нужно. И в этом, я полагаю, убедились многие читатели, получив на свой запрос список из нескольких тысяч документов. Во многих случаях это эквивалентно списку нулевой длины, так как заказчик в обоих случая не получает того, что хотел.
Встроенная в язык HTML метка <meta> создана для предоставления информации о содержании документа для поисковых роботов, броузеров и других приложений. Структура метки: <meta http-equiv=response content=description name=description URL=url>. Параметр http-equiv=response ставит в соответствие элементу заголовок HTTP ответа. Значение параметра http-equiv интерпретируется приложением, обрабатывающим HTML документ. Значение параметра content определяется значением, содержащимся в http-equiv.
Современная поисковая система содержит в себе несколько подсистем.
После того как Брин и Пейдж опубликовалисвой доклад в 1997 году, первоначальная схема поисковой системы parsing/indexing/sorting/serving (синтаксический анализ/индексация/сортировка/выдача результата) была дополнена сотнями алгоритмов. Помимо поиска того, что нужно клиенту, система анализирует характер запросов каждого из клиентов, составляя его профиль, а также частоту идентичных или схожих запросов, приходящих от разных клиентов.
Результатом такого анализа является формирование целевой рекламы, ориентированной на интересы определенного клиента, а также система автозаполнения. После того как в поле запроса клиент начинает вбивать текст запроса, система предлагает ему целый список возможных запросов, начинающихся с введенных букв или слов.
Поисковые системы довольно часто используют хакеры, пытаясь сделать так, чтобы среди первых найденных URL были ссылки на нужный вредоносный сайт.
Все чаще к поисковикам пытаются предъявить требования, чтобы они не выдавли ссылки на сайты, не отвечаюшие моральным критериям, критериям безопасности или противоречащим законодательству той или иной страны. Выполнить такие требования иной раз достаточно сложно.
Следует иметь в виду, что работа web-агентов и системы поиска напрямую независимы. WEB-агенты (роботы) работают постоянно, вне зависимости от поступающих запросов. Их задача - выявление новых информационных серверов, новых документов или новых версий уже существующих документов. Под документом здесь подразумевается HTML-, текстовый или nntp-документ. WEB-агенты имеют некоторый базовый список зарегистрированных серверов, с которых начинается просмотр. Этот список постоянно расширяется. При просмотре документов очередного сервера выявляются URL и по ним производится дополнительный поиск. Таким образом, WEB-агенты осуществляют обход дерева ссылок. Каждый новый или обновленный документ передается системе обработки. Роботы могут в качестве побочного продукта выявлять разорванные гиперсвязи, способствовать построению зеркальных серверов.
Обычно работа роботов приветствуется, ведь благодаря ним сервер может обрести новых клиентов, ради которых и создавался сервер. Но при определенных обстоятельствах может возникнуть желание ограничить неконтролируемый доступ роботов к серверам узла. Одной из причин может быть постоянное обновление информации каких-то серверов, другой причиной может стать то, что для доставки документов используются скрипты CGI. Динамические вариации документа могут привести к бесконечному разрастанию индекса. Для управления роботами имеются разные возможности. Можно закрыть определенные каталоги или сервера с помощью специальной фильтрации по IP-адресам, можно потребовать идентификации с помощью имени и пароля, можно, наконец, спрятать часть сети за Firewall. Но существует другой, достаточно гибкий способ управления поведением роботов. Этот метод предполагает, что робот следует некоторым неформальным правилам поведения. Большинство из этих правил важны для самого робота (например, обхождение так называемых "черных дыр", где он может застрять), часть имеет нейтральный характер (игнорирование каталогов, где лежит информация, имеющая исключительно локальный характер, или страниц, которые находятся в состоянии формирования), некоторые запреты призваны ограничить загрузку локального сервера.
Когда воспитанный робот заходит в ЭВМ, он проверяет наличие в корневом каталоге файла robots.txt. Обнаружив его, робот копирует этот файл и следует изложенным в нем рекомендациям. Содержимое файла robots.txt в простейшем случае может выглядеть, например, следующим образом.
# robots.txt for http://store.in.ru
| user-agent: * | # * соответствует любому имени робота |
| disallow: /cgi-bin/ | # не допускает робот в каталог cgi-bin |
| disallow: /tmp/ | # не следует индексировать временные файлы |
| disallow: /private/ | # не следует заходить в частные каталоги |
Файл содержит обычный текст, который легко редактировать, после символа # следуют комментарии. Допускается две директивы. user-agent: - определяет имя робота, к которому обращены следующие далее инструкции, если не имеется в виду какой-то конкретный робот и инструкции должны выполняться всеми роботами, в поле параметра записывается символ *. disallow - указывает имя каталога, посещение которого роботу запрещено. Нужно учитывать, что не все роботы, как и люди, следуют правилам, и не слишком на это полагаться (см. http://info.webcrawler.com/mak/projects/ robots.html).
Автор исходного текста может заметно помочь поисковой системе, выбрав умело заголовок и подзаголовок, профессионально пользуясь терминологией и перечислив ключевые слова в подзаголовках. Исследования показали, что автор (а иногда и просто посторонний эксперт) справляется с этой задачей быстрее и лучше, чем вычислительная машина. Но такое пожелание вряд ли станет руководством к действию для всех без исключения авторов. Ведь многие из них, давая своему тексту образный заголовок, рассчитывают (и не без успеха) привлечь к данному тексту внимание читателей. Но машинные системы поиска не воспринимают (во всяком случае, пока) образного языка. Например, в одном лабораторном проекте, разработанном для лексического разбора выражений, состоящих из существительных с определяющим прилагательным, и по своей теме связанных с компьютерной тематикой, система была не способна определить во фразе "иерархическая компьютерная архитектура" то, что прилагательное "иерархическая" относится к слову "архитектура", а не к "компьютерная" (Vickery & Vickery 1992). То есть система была не способна отличать образное использование слова в выражении от его буквального значения.
В свою очередь специалисты, занятые в области поисковых и информационных систем, способны заметно облегчить работу авторам, снабдив их необходимыми современными тезаурусами, где перечисляются нормативные значения базовых терминов в той или иной научно-технической области, а также устойчивых словосочетаний. Параллельно могут быть решены проблемы синонимов.
Число WEB-сайтов и депозитариев растет экспоненциально, среди них есть немало таких, которые можно идентифицировать как SPAM, так как их задачей в лучшем случае является навязчивая реклама.. Одной из проблем поисковой системы является идентификация таких объектов и игнорирование их.
В настоящее время, несмотря на впечатляющий прогресс в области вычислительной техники, степень соответствия документа определенным критериям запроса надежнее всего может определить человек. Но темп появления электронных документов в сети достигает ошеломляющего уровня (частично это связано с преобразованием в электронную форму старых документов и книг методом сканирования). Написание рефератов для последующего их использование поисковыми системами достаточно изнурительное занятие, требующее к тому же достаточно высокой профессиональной подготовки. Именно по этой причине уже достаточно давно предпринимаются попытки перепоручить этот процесс ЭВМ. Для этого нужно выработать критерии оценки важности отдельных слов и фраз, составляющих текст. Оценку значимости предложений выработал Г.Лун. Он предложил оценивать предложения текста в соответствии с параметром: Vпр = 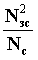 , где Vпр - значимость предложения; Nзс - число значимых слов в предложении; а Nc - полное число слов в предложении. Используя этот критерий, из любого документа можно отобрать некоторое число предложений. Понятно, что они не будут составлять членораздельного текста. Нужно учитывать также, что "значимые слова" должны браться из тематического тезауруса или отбираться экспертом. По той причине методика может лишь помочь человеку, а не заменить его (во всяком случае, на современном этапе развития вычислительной техники).
, где Vпр - значимость предложения; Nзс - число значимых слов в предложении; а Nc - полное число слов в предложении. Используя этот критерий, из любого документа можно отобрать некоторое число предложений. Понятно, что они не будут составлять членораздельного текста. Нужно учитывать также, что "значимые слова" должны браться из тематического тезауруса или отбираться экспертом. По той причине методика может лишь помочь человеку, а не заменить его (во всяком случае, на современном этапе развития вычислительной техники).
Автоматическая система выявления ключевых слов обычно использует статистический частотный анализ (методика В. Пурто). Пусть f - частота, с которой встречаются различные слова в тексте, а u - относительное значение полезности (важности).
Предположим, что мы ищем документ по теме "релевантность". Пусть существует документ, где слово "релевантность" повторяется подряд 1000 раз. Примитивная система статистического анализа поместит такой документ на первое место в списке результата поиска. Это вряд ли на порадует.
Существует и другая крайность, которую можно проиллюстрировать историей из Марка Твена. Он как-то посетил Кентерберийское аббатство, настоятель которого славился своими замечательными проповедями. После проповеди настоятель спросил Марка Твена о его впечатлении. Марк Твен заметил, что у него есть дома книга, где содержатся все слова из проповеди. Настоятель был удивлен и спросил, что это за книга и Марк Твен ответил, - Большая Британская Энциклопедия. Как это ни странно этот пример имеет непосредственное отношение к поисковым системам. Если не принять мер, большинство энциклопедических словарей может оказаться в списке отклика на любой поисковый запрос.
Тогда зависимость f(u) апроксимируется формулой 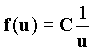 , то есть произведение частоты встречи слов и их полезности является константой. В теории автоматического анализа документов данная гипотеза используется для вывода следствия о существовании двух пороговых значений частот. Слова с частотой менее нижнего порога считаются слишком редкими, а с частотой, превосходящей верхний порог, - общими, не несущими смысловой нагрузки. Слова с частотой, находящейся посередине между данными порогами, в наибольшей степени характеризуют содержимое данного конкретного документа [Г. Лун; 2 (cм. также http://www.medialingvo.ru)]. К сожалению, выбор порогов процедура достаточно субъективная. Ключевые слова, выявляемые программно, аранжируются согласно частоте их использования. Замечено, что определенное значение имеет не только частота применения слова в конкретном документе, но и число документов, в которых это слово встречается. В работах Спарка Джонса экспериментально показано, что если N - число документов и n - число документов, в которых встречается данный индексный термин (ключевое слово), то вычисление его веса по формуле:
, то есть произведение частоты встречи слов и их полезности является константой. В теории автоматического анализа документов данная гипотеза используется для вывода следствия о существовании двух пороговых значений частот. Слова с частотой менее нижнего порога считаются слишком редкими, а с частотой, превосходящей верхний порог, - общими, не несущими смысловой нагрузки. Слова с частотой, находящейся посередине между данными порогами, в наибольшей степени характеризуют содержимое данного конкретного документа [Г. Лун; 2 (cм. также http://www.medialingvo.ru)]. К сожалению, выбор порогов процедура достаточно субъективная. Ключевые слова, выявляемые программно, аранжируются согласно частоте их использования. Замечено, что определенное значение имеет не только частота применения слова в конкретном документе, но и число документов, в которых это слово встречается. В работах Спарка Джонса экспериментально показано, что если N - число документов и n - число документов, в которых встречается данный индексный термин (ключевое слово), то вычисление его веса по формуле: 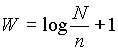 приводит к более эффективным результатам поиска, чем вообще без использования оценки значимости индексного термина.
приводит к более эффективным результатам поиска, чем вообще без использования оценки значимости индексного термина.
Одним из известных путей облегчения процедуры поиска является группирование документов по определенной достаточно узкой тематике в кластеры. В этом случае запрос с ключевым словом, фигурирующем в заголовке кластера, приведет к тому, что все документы кластера будут включены в список найденных. Кластерный метод наряду с очевидными преимуществами (прежде всего заметное ускорение поиска) имеет столь же явные недостатки. Документы, сгруппированные по одному признаку, могут быть случайно включены в перечень документов, отвечающих запросу, по той причине, что одно из ключевых слов кластера соответствует запросу. В результате в перечне найденных документов вы можете с удивлением обнаружить тексты, не имеющие никакого отношения к интересующей вас теме.
Некоторые поисковые системы предоставляют возможность нахождения документов, где определенные ключевые слова находятся на определенном расстоянии друг от друга (proximity search).
Наиболее эффективным инструментом при поиске можно считать возможность использования в запросе булевых логических операторов AND, OR и NOT. Объединение ключевых слов с помощью логических операторов может сузить или расширить зону поиска.
Проблема соответствия (релевантности) документа определенному запросу совсем не проста.
Индексные файлы, содержащие информацию о WEB-сайтах, занимают около 200 Гигабайт дискового пространства, поиск по содержимому которых производится за время, меньшее одной секунды (на самом деле, реальный поиск производится в более чем в десять раз меньшем объеме). Такой объем содержащейся информации делает Altavista неоценимым помощником в поиске нужных документов и серьезным конкурентом для остальных компаний, содержащих поисковые серверы. Поисковая система Altavista работает на самых мощных компьютерах, произведенных компанией Digital Equipment Corporation - это 16 серверов Alphaserver 8400 5/440, объединенных в сетевой кластер. Каждый из серверов имеет 8 Гбайт оперативной памяти (может иметь до 28 Гбайт), содержит 12 (до 14) процессоров Digital Alfa с тактовой частотой 437 МГц, в качестве жестких дисков используются высокоскоростные и надежные дисковые системы RAID с общим объемом 300 Гбайт. Для обеспечения связи с Интернет используются каналы с суммарной пропускной способностью 100 Мбит/с через шлюз DEC Palo Alto - что является самым мощным корпоративным шлюзом в Интернет.
Пример широко известной поисковой системы alta vista (данная статья готовилась в конце 90-х годов), где задействовано большое число суперЭВМ, показывает, что дальнейшее движение по такому пути вряд ли можно считать разумным, хотя прогресс в вычислительной технике может и опровергнуть это утверждение. Тем не менее, даже в случае фантастических достижений в области создания еще более мощных ЭВМ, можно утверждать, что распределенные поисковые системы могут оказаться эффективнее. Во-первых, местный администратор быстрее может найти общий язык с авторами текстов, которые могут точнее выбрать набор ключевых слов. Во-вторых, распределенная система способна распараллелить обработку одного и того же информационного запроса. Распределенная система памяти и процессоров может, в конце концов, стать более адекватной потокам запросов к информации, содержащейся на том или ином сервере. Способствовать этому может также создание тематических серверов поиска, где концентрируется информация по относительно узкой области знаний. Для таких серверов возможен отбор документов экспертами, они же могут определить списки ключевых слов для многих документов. Здесь возможна автоматическая предварительная процедура фильтрации документов по наличию определенного набора ключевых слов. Способствует этому и существование тематических журналов, где сконцентрированы статьи по определенной тематике.
В случаях, когда поисковая система выдает заказчику большой список документов, отвечающих критериям его запроса, бывает важно, чтобы они были упорядочены согласно их степени соответствия (наличие ключевых слов в заголовке, большая частота использования ключевых слов в тексте документа и т.д.). Но простые критерии здесь не всегда срабатывают, так объемный документ имеет больше шансов попасть в список результата поиска, так как в нем много слов и с большой вероятностью там встречается ключевое слово. По этому критерию Британская энциклопедия должна попасть в результирующий список любого запроса. Для компенсации искажений, вносимых длиной документов, используется нормализация весов индексных терминов.
Нормализация представляет собой способ уменьшения абсолютного значения веса индексных терминов, обнаруженных в документе. Одним из наиболее распространенных методов, решающих данную проблему, является косинусная нормализация. При использовании этого метода нормализации вес каждого индексного термина делится на Евклидову длину вектора оцениваемого документа. Евклидова длина вектора определяется формулой:  - вес i-того термина в документе, tf - (term frequency), частота, с которой встречается данный индексный термин; IDF (Inverted Document Frequency) - величина, обратная частоте, с которой данный термин встречается во всей совокупности документов. Окончательная формула для вычисления веса термина (w) в документе с учетом косинусного фактора нормализации представляется формулой:
- вес i-того термина в документе, tf - (term frequency), частота, с которой встречается данный индексный термин; IDF (Inverted Document Frequency) - величина, обратная частоте, с которой данный термин встречается во всей совокупности документов. Окончательная формула для вычисления веса термина (w) в документе с учетом косинусного фактора нормализации представляется формулой: 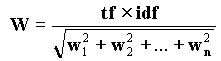 . Термины, которые отсутствуют в тексте документа, имеют нулевой вес. В списке, возвращаемом на запрос, документы перечисляются в порядке уменьшения данного численного значения.
. Термины, которые отсутствуют в тексте документа, имеют нулевой вес. В списке, возвращаемом на запрос, документы перечисляются в порядке уменьшения данного численного значения.
В работах Букштейна, Свенсона и Хартера было показано, что распределение функциональных слов в отличие от специфических слов с хорошей точностью описывается распределением Пуассона. То есть, если ищется распределение функционального слова w в некотором множестве документов, тогда вероятность f(n) того, что слово w будет встречено в тексте n раз представляется функцией: 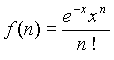 - распределение Пуассона. Значение параметра x варьируется от слова к слову, и для конкретного слова должно быть пропорционально длине текста. Слова, распределенные в совокупности документов согласно Пуассону, полезной информации не несут.
- распределение Пуассона. Значение параметра x варьируется от слова к слову, и для конкретного слова должно быть пропорционально длине текста. Слова, распределенные в совокупности документов согласно Пуассону, полезной информации не несут.
Для представления документов используется векторная модель, где любой документ характеризуется бинарным вектором x = x1,x2,…, xn, где значения xi = 0 или 1, в зависимости от того, присутствует в тексте i-ый индексный термин или нет. Рассматриваются два взаимно исключающих события:
w1 - документ удовлетворяет запросу
w2 - документ удовлетворяет запросу
Для каждого документа необходимо вычислить условные вероятности P(w1|x) и P(w2|x) для определения, какие документы удовлетворяют запросу, а какие нет.
Непосредственно получить значения этих вероятностей нельзя, поэтому необходимо найти другой альтернативный подход для их определения с помощью известных нам величин. По формуле Байеса для дискретного распределения условных вероятностей: 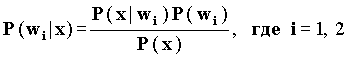 .
.
В приведенной формуле P(w1) - первоначальная вероятность соответствия (i = 1) или несоответствия (i = 2) запросу, величина P(x|wi) пропорциональна вероятности соответствия или несоответствия запросу для данного x; в недискретном случае она представляет собой функцию плотности распределения и обозначается как P(x|wi).
Окончательно:  , что представляет собой вероятность получения документа x в ответ на запрос при условии, что он будет ему соответствовать или нет. P(x) выступает в качестве нормализующего фактора (т.е. с его помощью достигается выполнение условия
, что представляет собой вероятность получения документа x в ответ на запрос при условии, что он будет ему соответствовать или нет. P(x) выступает в качестве нормализующего фактора (т.е. с его помощью достигается выполнение условия 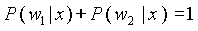 ).
).
Для определения релевантности документа используется вполне очевидное правило:
Если 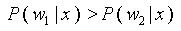 , то документ удовлетворяет запросу [1].
, то документ удовлетворяет запросу [1].
В противном случае считается, что документ не удовлетворяет запросу. При равенстве значений вероятности решение о релевантности документа принимается произвольно.
Правило [1] основано на том, что при его использовании просто минимизируется средняя вероятность ошибки принятия нерелевантного документа за релевантный и наоборот. То есть, для любого документа x вероятность ошибки 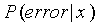 равна:
равна:

Таким образом, для минимизации средней вероятности ошибки необходимо минимизировать функцию 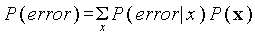 .
.
Не углубляясь в теорию вероятностного нахождения релевантных документов, укажем еще одно правило, которое можно использовать вместо [1]:

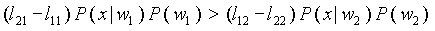 . [2]
. [2]
В формуле [2] коэффициенты lij стоимостной функции определяют потери, вносимые при ожидании события wi, когда на самом деле произошло событие wj.
Для практической реализации вероятностного поиска вводится упрощающее предположение относительно P(x|wi). Принимается, что значения xi вектора x являются статистически независимыми. Данное утверждение математически представляется в виде: 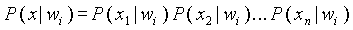 .
.
Определим переменные: 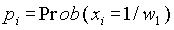 и
и 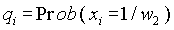 , представляющие собой вероятность того, что в документе присутствует i-ый индексный термин при условии, что документ является релевантным (нерелевантным). Соответствующая вероятность для отсутствия индексных терминов имеет вид
, представляющие собой вероятность того, что в документе присутствует i-ый индексный термин при условии, что документ является релевантным (нерелевантным). Соответствующая вероятность для отсутствия индексных терминов имеет вид 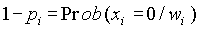 .
.
Вероятностные функции, используемые для подстановки в правило [1] имеют вид:
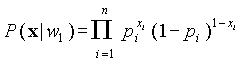 и
и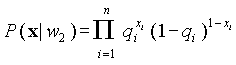 .
.Подставляя значения  в [2] и логарифмируя, получаем:
в [2] и логарифмируя, получаем:
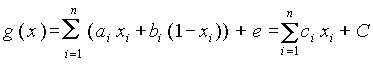 , где
, где
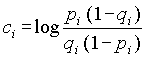 и
и 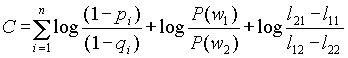 .
.
Функция G(x) представляет собой ничто иное, как весовую функцию, в которой коэффициенты Сi представляют собой веса присутствующих в документе индексных терминов. Константа С одинакова для всех документов x, но, конечно, различна для разных запросов и может рассматриваться в качестве порогового значения для поисковой функции. Единственными параметрами, которые могут меняться для данного запроса являются параметры стоимостной функции, вариации которых позволяют получать в ответе большее или меньшее число документов.
Теперь рассмотрим коэффициенты Сi функции G(x) с использованием следующей терминологии:
Таблица 4.5.14.1.
| Релевантные документы | Нерелевантные документы | Общее количество документов | |
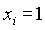 |
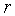 |
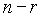 |
 |
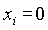 |
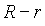 |
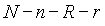 |
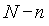 |
| Всего |  |
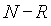 |
 |
N - полное число документов в системе.
R - число релевантных документов
r - число релевантных документов, выданных в ответ на запрос
n - полное число документов, выданных в ответ на запрос
Таблица представляет результаты запроса, направленного системе поиска. Представленная таблица должна существовать для каждого из индексных терминов.
Если мы обладаем всей информацией о релевантных и нерелевантных документах в коллекции документов, то применимы следующие оценки:  и
и 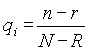 . Тогда функция g(x) может быть переписана в виде
. Тогда функция g(x) может быть переписана в виде 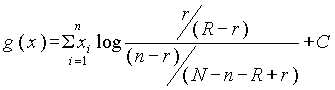 .
.
Коэффициент при xi показывает, до какой степени можно провести дискриминацию по i-тому термину в рассматриваемой коллекции документов. В действительности, N может рассматриваться не только как полное количество документов во всей коллекции, но и в некотором ее подмножестве.
Все приведенные формулы были выведены при условии, что индексные термины являются статистически независимыми. В общем случае это, конечно, не так. В теории вероятностного поиска моделируется зависимость между различными индексными формулами, в связи с чем, вид функции G(x) несколько меняется.
Многие системы поиска информации основаны на словарях и тезаурусах для корректировки запросов и представления индексируемых документов, чтобы увеличить шансы найти необходимый документ. На практике, большинство словарей составляется вручную. Словари создаются с помощью одного из двух основных способов:
В первом случае связываются слова, являющиеся взаимозаменяемыми, то есть, в словарях и тезаурусах они принадлежат одному и тому же классу. То есть, можно выбрать по одному слову из каждого класса и совокупность выбранных слов может быть использована для создания контролируемого словаря. Выбирая слова из созданного контролируемого словаря можно проводить индексацию документов или создавать поисковые запросы.
Во втором случае для создания тезауруса используются семантические связи между словами для построения, например, иерархической структуры связей. Создание такого типа словарей является достаточно сложным и трудоемким процессом.
Однако, были предложены способы и для автоматического создания словарей. В то время как созданные вручную словари опираются на семантику (т.е. распознают синонимы, являются более обширными, используют более тонкие взаимосвязи), автоматически созданные тезаурусы, в основном, основаны на синтаксическом и статистическом анализе. Но, так как, использование синтаксиса не приводит к серьезному увеличению эффективности работы систем, то значительно большее внимание уделяется статистическим методам.
Основное допущение, используемое для автоматического создания классов ключевых слов, заключается в следующем. Если ключевые слова a и b могут быть взаимозаменяемы в том смысле, что мы готовы принять документ, содержащий ключевое слово b вместо ключевого слова a и наоборот, то данное обстоятельство имеет место из-за того, что слова a и b имеют одинаковое значение или ссылаются на одинаковые темы.
Основываясь на описанном принципе нетрудно видеть, что создание классификации слов может быть автоматизировано. Можно определить два основных приближения для использования классификации ключевых слов:
Для простейшей поисковой стратегии, использующей только что описанные дескрипторы, независимо от того, являются ли они ключевыми словами или названиями классов, созданных на основе группы ключевых слов, "расширенное" представление документов и запросов с помощью любого из вышеописанных способов может существенно повысить число соответствий между документами и запросами и, следовательно, увеличить значение параметра recall. Правда, последнее обстоятельство не является определяющим, так как значение имеет только совокупность параметров (recall, precision), а одно лишь увеличение параметра recall может привести лишь к увеличению объема выдаваемых в ответ на запрос различных документов.
В отчетах об экспериментальных работах по использованию автоматической классификации ключевых слов, проведенных уже упоминавшимся ранее Спарком Джонсом, сообщается, что использование автоматической классификации приводит к увеличению эффективности работы системы по сравнению с системой, использующей неклассифицированные ключевые слова.
Работа Минкера и др. не подтвердила выводы Спарка Джонса и, фактически, показала, что в некоторых случаях использование классификации ключевых слов приводит к существенному ухудшению работы системы в целом. Д. Сальтон в своем отзыве о работе Минкера определил, что целесообразность использования классификации ключевых слов для улучшения эффективности работы поисковых систем еще полностью не определена и является объектом дальнейших экспериментальных исследований. Действительно, при работе в Интернет с поисковыми системами, использующими классификацию ключевых слов, (такими как lycos и excite) заметно существенное увеличение документов, не представляющих ничего общего с запросом, но, тем не менее, имеющих довольно высокий ранг и, следовательно, по мнению поисковой системы, наиболее точно соответствующих заданному запросу.
Для дальнейшего увеличения эффективности системы используется так называемая кластеризация документов.
Существуют две основные области применения методов классификации в системах поиска и локализации информации. Это - кластеризация (классификация) ключевых слов и кластеризация документов.
Под кластеризацией документов понимается создание групп документов, таких, что документы, принадлежащие одной группе, оказываются, в некоторой степени, связанными друг с другом. Другими словами, документы принадлежат одной группе потому, что ожидается, что эти документы будут находиться вместе в результате обработки запроса. Логическая организация документов достигается, в основном, двумя следующими способами.
Первый - путем непосредственной классификации документов и второй - посредством промежуточного вычисления некоторой величины соответствия между различными документами.
Было теоретически доказано, что первый метод является очень сложным для практической реализации, так что любые экспериментальные результаты не могут считаться достаточно надежными. Второй способ классификации заслуживает подробного внимания, и, по сути, является единственным реальным подходом к решению проблемы.
На практике почти невозможно сопоставить каждый из документов каждому из запросов из-за слишком больших затрат машинного времени на проведение таких операций. Было предложено много различных способов для уменьшения количества необходимых для выполнения запроса операций сравнения. Наиболее многообещающим было предложение использовать группы взаимосвязанных документов, используя процедуры автоматического определения соответствия документов. Проводя сравнения запроса всего лишь с одним документом, являющимся представителем группы (заранее определенным) и, таким образом, определяя группу документов, в которой и происходит дальнейший поиск, существенно уменьшается затрачиваемое на обработку запроса машинное время. Однако, Дж. Сальтон полагал, что, хотя использование кластеризации документов и уменьшает время поиска, но неизбежно снижает эффективность поисковой системы. Точка зрения других исследователей несколько отличается от мнения Дж. Сальтона, так, в работе Jardine, N. и Van Rijsbergen, c.j., "The Use of Hierarchic Clustering in Information Retrieval", Information Storage and Retrieval, 7, 217-240 (1971) делаются выводы о достаточно высоком потенциале методов кластеризации для увеличения эффективности работы поисковых систем.
Для построения систем поиска информации с использованием кластеров необходимо использовать методы для определения степени взаимосвязи между объектами. На основе определенных взаимосвязей можно построить систему кластеров. Взаимосвязь между документами определяется понятиями "степень сходства", "степень различия" и "степень соответствия". Значение степени сходства и степени соответствия между документами увеличивается по мере увеличения количества совпадающих параметров. В рассмотрении могут участвовать совершенно разные параметры. Некоторыми исследователями отмечалось, что различие в производительности поисковых систем при использовании различных способов определения степени ассоциации является несущественным, при условии, что функции, используемые для ее определения, являются соответствующим образом нормализованными. Интуитивно, такой вывод можно понять, так как большинство методов определения взаимосвязи между документами используют одни и те же параметры (использующие, в большинстве, статистический анализ текстовых документов). Данное предположение подтверждается в работах И. Лермана, где показано, что многие из способов определения степени соответствия являются монотонными по отношению друг к другу.
В теории поиска информации используется пять основных способов определения степени соответствия. Документы и запросы представляются, в основном, с помощью индексных терминов или ключевых слов, поэтому для облегчения описания моделей обозначим посредством 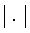 размер множества ключевых слов, представляющих рассматриваемый документ или запрос.
размер множества ключевых слов, представляющих рассматриваемый документ или запрос.
Самая простая из моделей для определения степени соответствия - это так называемый простой коэффициент соответствия:
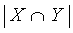 , показывающий количество общих индексных терминов. При вычислении коэффициента не берутся в рассмотрение размеры множеств X и Y.
, показывающий количество общих индексных терминов. При вычислении коэффициента не берутся в рассмотрение размеры множеств X и Y.
В следующей таблице показаны другие подходы к определению степени соответствия, использующие коэффициенты, учитывающие размеры множеств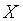 и
и 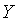 .
.
Таблица 4.5.14.2
| Коэффициент | Название |
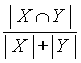 |
Коэффициент Дайса (dice) |
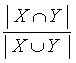 |
Коэффициент Джаккарда (jaccard) |
 |
Косинусный коэффициент |
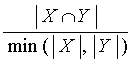 |
Коэффициент перекрытия |
Приведенные коэффициенты, по сути, представляют собой нормализованные варианты простого коэффициента соответствия.
Скажем несколько слов о функциях, определяющих степень различия между документами. Причины использования в системах поиска информации функций, определяющих степень различия между документами, вместо степени соответствия являются чисто техническими. Добавим, что любая функция оценки степени различия между документами d может быть преобразована в функцию, определяющую степень соответствия s следующим образом:  . Надо сказать, что обратное утверждение, вообще говоря, не верно.
. Надо сказать, что обратное утверждение, вообще говоря, не верно.
Если P - множество объектов, предназначенных для кластеризации, то функция D определения степени различия документов - это функция, ставящая в соответствие 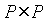 неотрицательное рациональное число. Функция определения степени различия d удовлетворяет следующим условиям:
неотрицательное рациональное число. Функция определения степени различия d удовлетворяет следующим условиям:


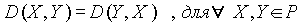
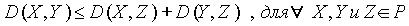
Четвертое свойство неявно отображает тот факт, что функция определения степени различия между документами является, в некоторой степени, функцией, определяющей "расстояние" между двумя объектами и, следовательно, логично предположить, что должна удовлетворять неравенству треугольника. Данное свойство выполняется практически для всех функций определения степени различия.
Пример функции, удовлетворяющей свойствам 1 - 4:
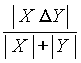 , где
, где 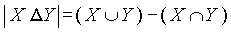 представляет собой разность множеств x и y. Она связана, например, с коэффициентами Дайса соотношением
представляет собой разность множеств x и y. Она связана, например, с коэффициентами Дайса соотношением 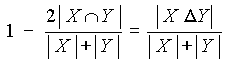 .
.
Наконец, представим функцию определения степени различия в альтернативной форме:  , где суммирование производится по всем различным индексным терминам, входящим в коллекцию документов.
, где суммирование производится по всем различным индексным терминам, входящим в коллекцию документов.
Используя векторное представление документов, для 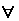 двух векторов
двух векторов 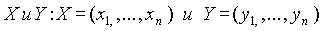 для косинусного коэффициента соответствия
для косинусного коэффициента соответствия
 получаем следующую формулу:
получаем следующую формулу: 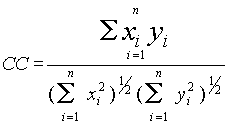 .
.
Скажем несколько слов о вероятностном подходе для функций, определяющих степень соответствия. Степень соответствия между объектами определяется по тому, насколько их распределения вероятности отличаются от статистически независимого. Для определения степени соответствия используется ожидаемая взаимная мера информации. Для двух дискретных распределений вероятности 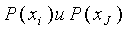 она может быть определена как:
она может быть определена как:
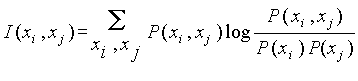 .
.
Если xi и xj - независимы, тогда
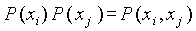 и
и 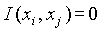 (и
(и
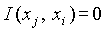 ). Дополнительно выполняется
условие, что
). Дополнительно выполняется
условие, что 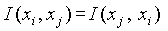 , показывающее, что функция является симметричной.
, показывающее, что функция является симметричной.
Функция  интерпретируется как статистическая мера информации, содержащейся в документе
интерпретируется как статистическая мера информации, содержащейся в документе 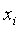 о документе
о документе 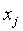 (и наоборот). Когда данная функция применяется для определения степени связи между двумя индексными терминами, например, i и j, тогда xi и xj являются бинарными переменными. Таким образом,
(и наоборот). Когда данная функция применяется для определения степени связи между двумя индексными терминами, например, i и j, тогда xi и xj являются бинарными переменными. Таким образом,  является вероятностью присутствия индексного термина i и, соответственно P(xi=0) является вероятностью его отсутствия.
является вероятностью присутствия индексного термина i и, соответственно P(xi=0) является вероятностью его отсутствия.
Та степень взаимосвязи, которая существует между индексными терминами i и j вычисляется затем функцией , показывающей степень отклонения их распределений от статистически независимого.
Были предложены и другие функции, похожие на описанную выше функцию для определения степени соответствия (см. Jardine, N. and Sibson, R., Mathematical Taxonomy, Wiley, London and New York (1971)) между парами документов.
Как и в случае автоматической классификации документов, использование вероятностных методов при формировании кластеров содержит в себе достаточно высокий потенциал и представляет крайне интересную область для исследований.
Итак, для формирования кластеров необходимо использовать некую функцию соответствия для определения степени связи между парами документов из коллекции.
Постулируем теперь основную идею, на которой, собственно говоря, и построена вся теория кластерного представления коллекции документов. Гипотеза, приведшая к появлению кластерных методов, называется Гипотезой Кластеров и может быть сформулирована следующим образом: "Связанные между собой документы имеют тенденцию быть релевантными одним и тем же запросам".
Базисом, на котором построены все системы автоматического поиска информации, является то, что документы, релевантные запросу, отличаются от нерелевантных документов. Гипотеза кластеров указывает на целесообразность разделения документов на группы до обработки поисковых запросов. Естественно, она ничего не говорит о том, каким образом должно проводиться это разделение.
Проводился ряд исследований по поводу применения кластерных методов в поисковых системах. Некоторые отчеты приведены в работах Б. Литофски, Д. Крауча, Н. Привеса и Д. Смита, а также М. Фритше.
Кластерные методы, выбираемые для использования в экспериментальных поисковых системах должны удовлетворять некоторым определенным требованиям. Это:
Основной вывод из вышесказанного состоит в том, что любой кластерный метод, не удовлетворяющий приведенным условиям, не может производить сколько-нибудь значащие экспериментальные результаты. Надо сказать что, к сожалению, далеко не все работающие кластерные методы удовлетворяют приведенным требованиям. В основном, это происходит из-за значительных различий между реализованными методами кластеризации от теоретически разработанных ад-хок алгоритмов.
Другим критерием выбора является эффективность процесса создания кластеров с точки зрения производительности и требований к объему необходимого дискового пространства.
Необходимость учета данного критерия находится, естественно, в сильной зависимости от конкретных условий и требований.
Возможно, использование процедур фильтрации базы данных таким образом, что из базы данных будет удаляться информация об индексных терминах, встречающихся в более чем, скажем 80% проиндексированных документов. Таким образом, список стоп-слов будет динамически изменяющимся. Как уже говорилось, использование списка стоп-слов может приводить к 30% уменьшению размеров индексных файлов. Для построения кластеров обычно используется два основных подхода:
В первом случае кластеры можно представить с помощью графов, построенных с учетом значений функции соответствия для каждой пары документов.
Рассмотрим некоторое множество объектов, которые должны быть кластеризованы. Для каждой пары объектов из данного множества вычисляется значение функции соответствия, показывающее насколько эти объекты сходны.
Если полученное значение оказывается больше величины заранее определенного порогового значения, то объекты считаются связанными. Вычислив значения функции соответствия для каждой пары объектов, строится граф, по сути, представляющий собой кластер. То есть определение кластера строится в терминах графического представления.
В середине 2016 года число поисковых запросов к системе Google в секунду достигло 57000 (а в 2015г -1,2 триллиона в год).
| 1 | Salton, G., "Automatic Text Analysis", Science, 168, 335-343 (1970) |
| 2 | Luhn, H. P. "The automatic creation of literature abstracts", IBM Journal of Research and Development, 2, 159-165 (1958) |
| 3 | Gerard Salton, Chris Buckley and Edward A. Fox, "Automatic Query Formulations in Information Retrieval", Cornell University, http://cs-tr.cs.cornell.edu/ |
| 4 | Tandem Computers Inc. "Three Query Parsers", http://oss2.tandem.com /search97/doc/srchscr/tpappc1.htm |
| 5 | Object Design Inc., "Persistent Storage Engine PSE-Pro documentation", http://www.odi.com/ |
| 6 | Roger Whitney, "CS 660: Combinatorial Algorithms. Splay Tree", San Diego State University. http://saturn.sdsu.edu:8080/~whitney/ |
| 7 | Список публикаций по технологиям поиска |
Previous: 4.5.13 Система поиска файлов Archie
UP:
4.5 Процедуры Интернет |




