|
Previous: 4.7.9 Охлаждение вычислительной техники
UP:
4.7 Прикладные сети Интернет |
|
Previous: 4.7.9 Охлаждение вычислительной техники
UP:
4.7 Прикладные сети Интернет |
4.7.10 Большие объемы данных (big data)
Семенов Ю.А. (ГНЦ ИТЭФ)
| В обиход введен термин "технологии больших объемов данных" (Big data technologies). Это новое поколение технологий и архитектур, разработанных для эффективного извлечения нужной информации из гигантских объемов данных, относящихся к различным типам. |
Термин "большие объемы" - оценочный. На разных этапах развития информационных технологий проблемы обработки данных возникали регулярно. Все зависило от уровня развития техники устройств памяти и обработки информации и в разное время под этим термином подразумевались разные значения. На текущем этапе все шире и чаще используются большие таблицы переадресации (маршрутизации) и гигантские индексные файлы баз данных. Время выборки из хэш-массивов и индексных файлов имеет экспоненциальную зависимость от объема хэша.
В 2012 года темп роста объемов "big data" достиг 62% в год, из них 85% остаются не управляемыми (вне баз данных). (см. The Truth About Big Data и For Big Data Analytics There’s No Such Thing as Too Big). На рисунке ниже отражена эволюция технологии big data и ожиданий пользователей (см. "2013 in review: Big data, bigger expectations?", Larry Freeman, December 16, 2013).

Рис. 1. Эволюция big data (Olga Tarkovskiy)
Лет 10-15 назад на вопрос, базу данных какого типа следует использовать, ответ был однозначен, - реляционную. У меня проблемы с MySQL стали возникать несколько лет назад, когда объем индексного файла по сетевым атакам превысил 40 ГБайт. Время выборки по мере роста объема данных начало быстро рости. Ниже на рисунке показаны источники больших объемов данных ("Big security for big data". HP)
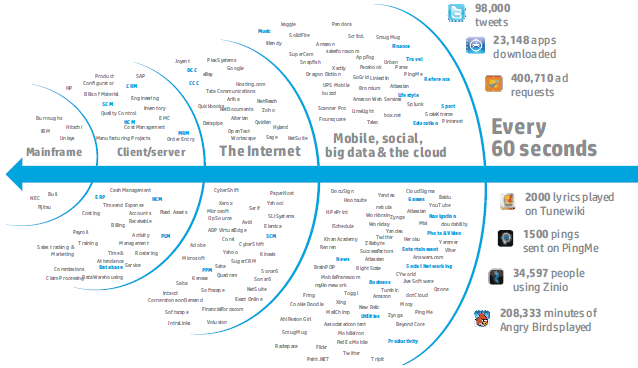
Рис. 2. Источники больших объемов данных
Только в одном Twitter формируется почти 100 млн. коротких сообщений в сутки. Специалисты из исследовательской компании IDC полагают, что до 2020г, объемы информации цифровой вселенной увеличится на 35 триллионов гигабайт. В 2011 объем цифровых данных, генерируемых и копируемых, превысит 1.8 триллиона гигабайт – темп роста 9 раз за пять лет. Компания Google обрабатывает более одного петабайта в час.
Рис. 2а демонстрирует нелинейную зависимость времеени выборки из банка данных MySQL (база данных сетевых атак сети МСЦ РАН) от размера банка.
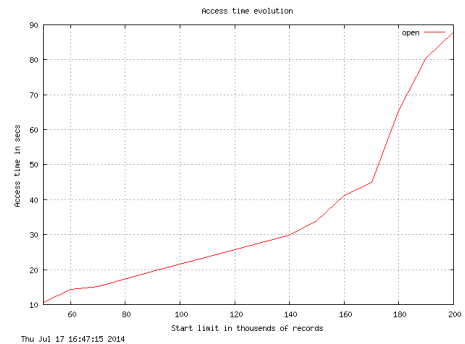
Рис. 2a. Эволюция времени выборки для рекордов с номерами в диапазоне от 50 до 200 млн. (Nрек=202.420.028 БД attacks.SUM)
К 2020 году на каждого жителя Земли, включая стариков и детей, будет приходиться 5200 ГБ данных. Только 15% этих данных будет записано в облачной среде (прогноз Digital Universe by Lucas Mearian). Предполагается, что объем данных будет удваиваться каждый год. Компания IDC оценивает, что к 2020, 33% всех данных будут содержать информацию, которая может быть ценной, если ее анализировать. К 2020 году полный объем данных, которыми будет обладать человечество, составит 35 ЗБ.
Типовой пассажирский лайнер генерирует 20 терабайт данных на каждый из двигателей в час. За один полет из Нью-Йорка в Лос Анжелес Боинг 737 генерирует 240 терабайт данных. Если принять во внимание, что в день осуществляется около 30,000 полетов (США), объемы данных быстро стремятся к петабайтам.
Большие потоки создают исследования, связанные с геномом, так в швейцарском институте биоинформатики: только один эксперимент порождает до 743000 файлов со средним размером 2 ТБ, такие эксперименты выполняются до двух раз в неделю. Гигантские объемы данных создают различные системы видео мониторинга. Ожидается, что к 2015 года такие системы потребуют памяти с объемом 4 петабайт.
Самым мощным источником данных сегодня являются детекторы, работающие на большом адронном коллайдере (LHC) в ЦЕРН. Они генерируют несколько петабайт в секунду. Ожидается, что через пару лет этот поток увеличится в несколько раз.
Обычно организация, имеющая более 1000 сотрудников, имеет около 200 ТБ данных.
К 2015 году глобальный мобильный трафик через Интернет достигнет 6.30 экзабайт в месяц (оценка компании Cisco - Cisco UCS Ecosystem for Oracle: Extend Support to Big Data and Oracle NoSQL Database, 2012г. см. также For Big Data Analytics There’s No Such Thing as Too Big. The Compelling Economics and Technology of Big Data Computing. March 2012). Один экзабайт эквивалентен 10 млрд. копий печатной версии еженедельного журнала новостей.
В США 8 организаций порождают и накопили наибольшие объемы данных:
Отдельную проблему составляет задача работы с большими объемами информации в рамках баз данных. По мере роста объема информации у вас возникают проблемы с нужными объемами на жестких дисках (эта часть проблемы относительно легко решается), и, что более важно, с временами доступа к нужным данным. Можно, разумеется, использовать изощренные кэши, но и это в конце концов не поможет. Можно секционировать БД, помещая каждый класс информации в свою БД.
По мере роста объема банка данных сильно снижается быстродействие системы. Одним из путей уменьшения времени доступа к данным является размещение базы данных в оперативной памяти (см. "In-memory databases - what they do and the storage they need", Chris Evans). Эта техника позволяет получить выигрыш в быстродействии до 100 раз.
Для решения этой проблемы (big data) разработана специальная разновидность баз данных NoSQL (http://www.nosql-database.org). Сопоставление свойств реляционных баз данных и NoSQL представлено в таблице ниже.
| Реляционные базы данных | Базы данных NoSQL |
|
|
Технология NoSQL (например, Cassandra) не предназначена заменить реляционные базы данных, скорее она помогает решить проблемы, когда объем данных становится слишком велик. NoSQL часто использует кластеры недорогих стандартных серверов. Это решение позволяет понизить стоимость на гигабайт в секунду в несколько раз. Компания CISCO предлагает решения для унифицированных компьютерных систем (UCS), содержащих как blade, так и стоечные серверы (см. http://www.cisco.com/go/bigdata). Отдельную проблему составляет обеспечение безопасности при работе с Big Data. Ниже на рис. 3 показано дерево технологий NoSQL. Ожидается, что к 2020 году рынок NoSQL увеличится вдвое и достигнет 3,4 млрд долларов.
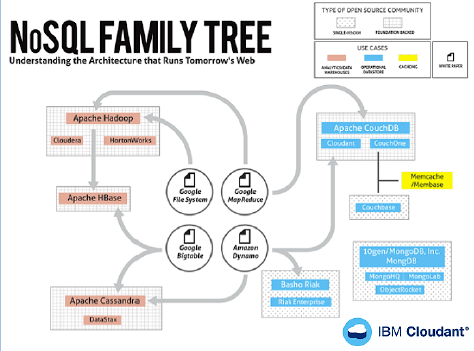
Рис. 3. Дерево NoSQL
Big data будут использоваться для разработки новых методов образования (индивидуализация обучения), диагностики болезней, выработки индивидуального плана лечения, прогнозирования тенденций в сфере бизнеса и т.д.
В LANL (Lawrence Livermore National Laboratory) создан суперкомпьютер (Catalyst), предназначенный для переработки больших объемов данных (см. "Need to crunch 150 teraflops per second? Meet first-of-a-kind supercomputer Catalyst", Darlene Storm, May 07, 2014). Мощность Catalyst составляет 150 терафлопов/сек Он сожержит в себе 324 узла, 7776 ядер и использует 12-ядерные процессоры Intel Xeon E5-2695v2. В Catalyst применена архитектура Cray CS300, адаптированная для переработки больших объемов данных для целей науки и промышленности. Catalyst содержит по 128 гигабайт динамической памяти (DRAM) и по 800 Гбайт нестираемой памяти (NVRAM) для каждого из узлов. Плюс 3,2 тбайта для распределённая файловая система с массовым параллелизмом (lustre). Эта память предназначена для улучшения сетевых характеристик кластера с двух-магистральным QDR-80 (Quad Data Rate). В дополнение к этому узлы имеют SSD Intel. Данный комплекс планируется использовать для бизнес аналитики и для исследования свойств сверхтяжелых элементов, в частности с атомным номером 117.
Компания Databricks сообщила, что ей удалось отсортировать 100 ТБ данных за 23 минуты, что является новым мировым рекордом (см. "World record set for 100 TB sort by open source and public cloud team", Reynold Xin, 15 Jan 2015). Для этих целей использовались виртуальные машины Apache Spark on 207 EC2.
Источниками больших объемов данных являются: базы данных (63%), электронная почта (61%), операционные данные (53%), технологическая информация (51%).
Проекты компании IBM генерируют каждый день 2,5 квадрильона байт данных. 90% всех данных, полученных человечеством, возникло за последние два года. Объемы некоторых банков данных достигли терабайтного диапазона.
От этих даннах зависят многие аспекты жизни человека, быстро развиватеся направление компьютерной аналитики и по этой причине здесь требуется очень высокий уровень безопасности (см. "Big data needs big security changes", Andrew C. Oliver, InfoWorld). Данные больших объемов стали материалом, с которым нужно работать компаниям, которые хотят понять своих клиентов.
Компания IDC прогнозирует, что к 2025 году объем данных в мире достигнет 175 зеттабайт (см. "IDC: Expect 175 zettabytes of data worldwide by 2025", Andy Patrizio, Network World, DEC 3, 2018). Большая часть этого объема будет храниться в облаках и информационных центрах. В этом прогнозе использованы результаты исследований компании Cisco. Если для записи этих данных попытаться использовать самый емкий тип современных драйвов, то потребуется 12,5 миллиарда таких приборов. Ожидается, что ближайшие 7 лет будут закуплены устройства памяти с объемом 42 зеттабайт. 90 зеттабайт придется к 2025 году на приборы IoT, а 49% объемов данных будет храниться в облачной среде. Следует иметь в виду, что самые продвинутые современные смартфоны имеют память 256 ГБайт.
"The Digitization of the World. From Edge to Core", David Reinsel, John Gantz, John Rydning, November 2018.
К 2025 году число пользователей этих данных достигнет 5 миллиардов. 90 зеттабайт в 2025г будет создаваться устройствами IoT. На рис. 4 показан рост глобального объема данных по годам. Данные были получены от 1100 экспертов из 110 стран.
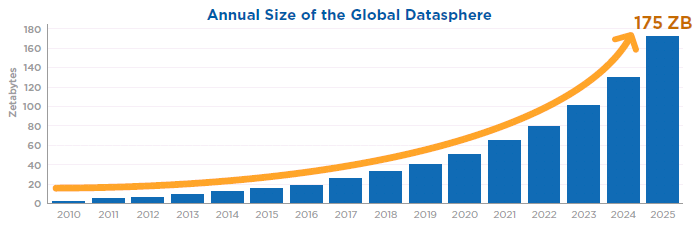
Рис. 4. Глобальный рост объема данных в 2010-2025гг
В последние годы глобальный трафик Интернет заметно превысил 100 Гбайт в секунду, полагаю, что пока я пишу эти строки, превзоден и терабайтеый порог. Рост носит стабильно экспоненциальный характер.
Previous: 4.7.9 Охлаждение вычислительной техники
UP:
4.7 Прикладные сети Интернет |




