|
Previous: 4.7.17 Цифровая медицина
UP:
4.7 Прикладные сети Интернет |
|
Previous: 4.7.17 Цифровая медицина
UP:
4.7 Прикладные сети Интернет |
4.7.18 ДНК-компьютинг
Семенов Ю.А. (ГНЦ ИТЭФ)
Еще в 1964 году Ричард Фейнман высказал предположение, что со временем компьютеры будут состоять из молекул, а не транзисторов. Позднее в 1994 году Адлеман рассмотрел возможность создания компьютера на основе ДНК-структур. (см. "Introduction to DNA Computing", Shivam Saxena, SSRG-IJCSE – Volume 7 Issue 2 – February 2020).
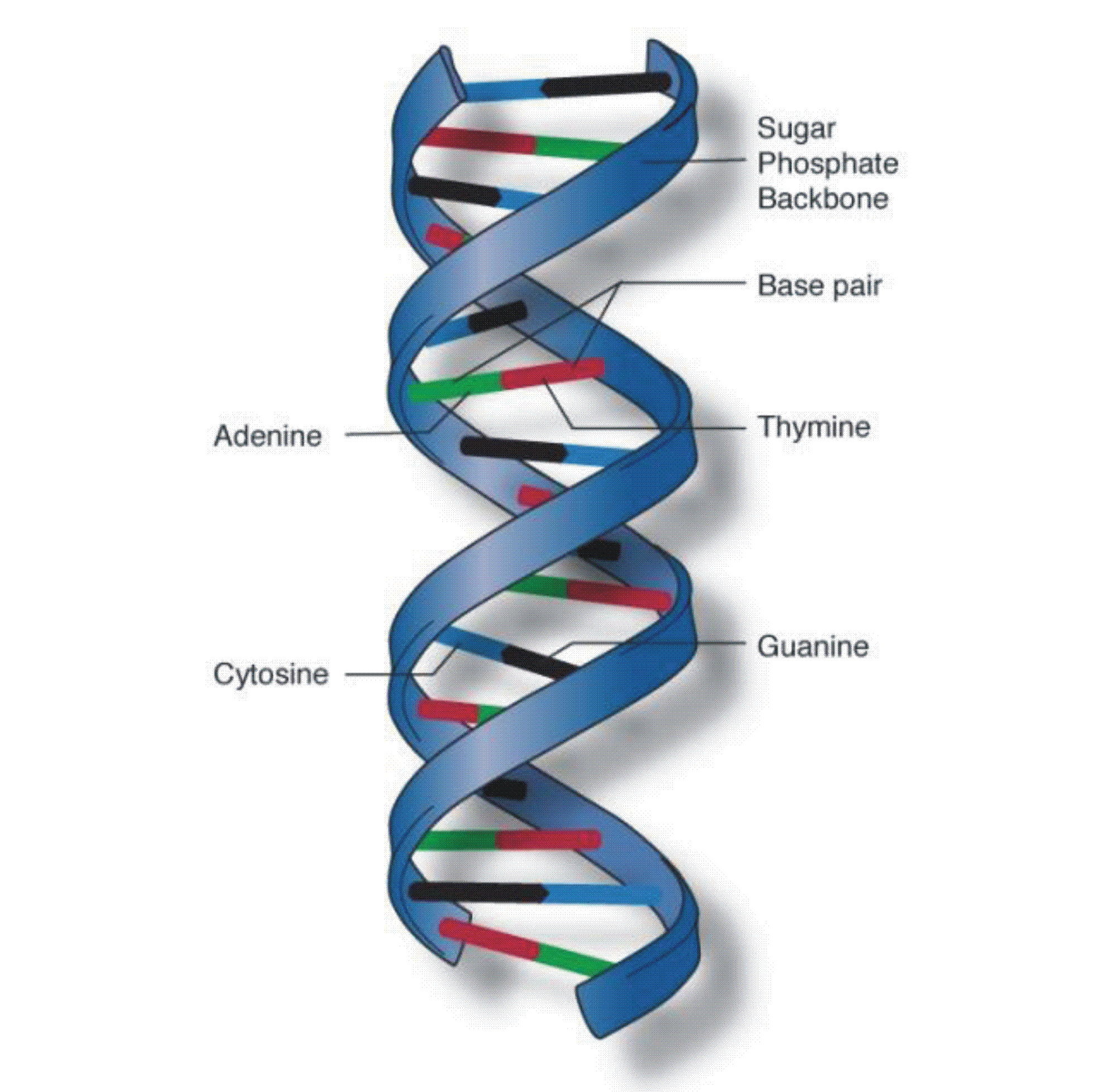
Рис. 1. Структура ДНК
Молекулы ДНК (дезоксирибонуклеиновая кислота) выполняют в любом живом организме достаточно сложную работу, обеспечивая все без исключения жизненные процессы в клетках объекта. Это прежде всего обеспечение передачи наследственных данных от одного поколения живых организмов к другому. Информация в ДНК записывается с помощью последовательностей четырех нуклеотидов: аденин (A), гуанин (G), тимин (T) и цитозин (C). Нуклеотиды образуют пары A с T и C с G (A-T и C-G). Эти структуры служат для развития организма, выживания и воспроизводства. ДНК человека содержит около 3 миллиардов таких нуклеотидов.
Под ДНК-компьютингом понимается использование ДНК-структур для запоминания данных и их преобразование посредством ДНК-операций. Т.о. ДНК- компьютер - это совокупность ДНК-структур, которые пригодны для решения определенных задач.
Устройства памяти на основе ДНК-структур могут обеспечить увеличение плотности записи по сравнения с традиционными методами в 100000 раз. Данная технология может реализовать распараллеливание вычислительных операций в миллиардном масштабе. Оптимистическая оценка быстродействия таких компьютеров обещает удвоение скорости по сравнению с самыми мощными суперкомпьютерами (за счет распараллеливания).
Сначала Адлеман, затем Липтон и Розенберг показали возможность решения некоторых проблем на ДНК-компьютере. Считается, что некоторые проблемы с NP-сложностью, нереализуемые на традиционных суперкомпьютерах сегодня, могут быть решены с помощью ДНК-компьютера.
В 1997 году исследователи из университета Рочестера разработали логические ключи на основе ДНК. В 2006 году исследователи из Колумбийского университета и университета Нью-Мексико анонсировали разработку ДНК-компьютера, который может диагностировать вирусы Западного Нила и птичьего гриппа. В мае 2010 года компания IBM и Калифорнийский Технологический институт создали компьютерный чип, использующий синтезированные ДНК-молекулы. Но конкретные данные о быстродействии ДНК-компьютеров пока отсутствуют. Не решены проблемы и сохранности данных.
Одним из важных преимуществ ДНК-компьютеров является также низкое энергопотребление. Но нужно иметь в виду, что ДНК-компьютеры нельзя программировать, это устройства, создаваемые под решение определенной задачи
Использование синтетических ДНК открывает перспективу увеличения плотности активных элементов в компьютере (см. "Demonstration of End-to-End Automation of DNA Data Storage", Christopher N. Takahashi, Bichlien H. Nguyen, Karin Strauss и Luis Ceze, March 2019). Авторы разработали полностью автоматизированную, модульную ДНК-систему памяти, использующую синтезатор ДНК, пригодную для чтения-записи 5-байт.
Прежде чем данные будут записаны в такую память, они должны быть преобразованы из логических <0> и <1> в формат A, C, T и G и снабжены компонентами для коррекции ошибок. После этого данные передаются ДНК-синтезатору. При чтении процедцры преобразования кодов производятся в обратном порядке. Смотри рис. 1.
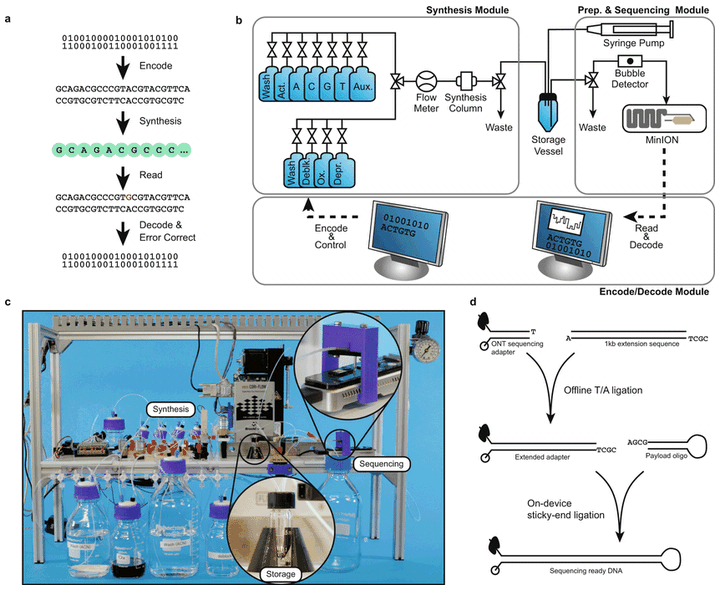
Рис. 1. Структура автоматизированной ДНК-памяти
Previous: 4.7.17 Цифровая медицина
UP:
4.7 Прикладные сети Интернет |




