|
Previous: 4.7.20 Гиперконвергентная инфраструктура (HCI)
UP:
4.7 Прикладные сети Интернет |
|
Previous: 4.7.20 Гиперконвергентная инфраструктура (HCI)
UP:
4.7 Прикладные сети Интернет |
4.7.21 Метод описания проблем
Семенов Ю.А. (ГНЦ ИТЭФ)
Надо выработать технику построения функциональной схемы (блок-схемы), описывающей решение проблемы. Граф такого описания, к сожалению, может содержать в себе циклы. В графе надо выделить области без циклов. Если граф построен, разбить проблему на субзадачи станет относительно просто.
Базовые операторы и структуры языка PDL описываются с помощью BNF.
Следует иметь в виду, что диалоговый метод не позволяет описать проблему полностью из-за конечности числа ветвей. Уточнение может выполнить программист с помощью языка PDL или с помощью вставок на каком-то языке высокого уровня. Чем большее число тем M покрывает диалог, тем сложнее программа и тем выше вероятность ошибок в ней. По этой причине М не желательно делать больше 100. Диалоговую программу должна формировать программа-робот, а программист заполняет тексты вопросов и возможных ответов.
В нем должно быть сказано, что следует сделать, что является входными данными, включая их формат, какой результат должен быть получен, и каким должен быть формат выходной информации (это справедливо для вычислительных задач). Язык описания проблемы будем называть Problem Description Language (PDL). Возможно, потребуется создать несколько модификаций PDL, ориентированных на разную проблематику, включая не программную.
Число вариантов описаний различных задач равно бесконечности. Более того, одна и та же проблема может быть описана разными способами. Варианты:
a. используются примитивы;
б. используются программные модули, хранящиеся в банке данных;
в. Без примитивов и программных модулей (большие трудности в отсутствии искусственного интеллекта или активного участия программиста).
Современные программы действуют в соответствии с заложенным в них алгоритмом и по этой причине не могут быть универсальными. Пока реального искусственного интеллекта в компьютерах нет, нужно обеспечить эффективное взаимодействие между компьютером и программистом.
Транслятор должен конвертировать текст описания проблемы с естественного или метаязыка в текст описания алгоритма на одном из языков программирования высокого уровня (например, Perl).
В случае использования естественного языка должен анализироваться контекст описаний и выявляться контекстные значения некоторых слов и словосочетаний. Ведь, например, значение слов "удельный вес" в конструкциях "удельный вес вещества" и "удельный вес капиталовложений" имеет разный смысл.
Для решения проблем контекста надо создать тематические тезаурусы для каждой из областей знания, начиная с ИТ. Но и в ИТ могут применяться разные версии PDL для описания разного класса проблем.
В языке PDL могут быть определены модули описаний некоторых элементарных процедур.
Даже если контекст очевиден, для преобразования описания проблемы на естественном языке в программу потребуются средства ИИ (Искусственного Интеллекта). Но ИИ не может гарантировать безошибочность.
В случае задачи управления (сетевого) должен быть предоставлен список мониторируемых или управляемых объектов, параметров управления, протокол доступа (напр., SNMP и MIB), охарактеризованы требования к управлению (измерение параметров, поддержание максимального, минимального или предопределенного значения параметра, вариация параметра по оговоренному закону, частота измерения). В данном случае может потребоваться также описание свойств имеющегося оборудования.
Любое описание алгоритма на одном из известных языков можно представить в виде графа, где ребрам соответствуют последовательности исполняемых команд или команды передачи управления, а узлам команды проверки определенных условий (точки ветвлений).
Описание задания должно быть преобразовано в совокупность графов, реализующих определенные алгоритмы. Описания алгоритмов, будут храниться в специальном банке.
Для описания параметров оборудования надо будет организовать дополнительный диалог. При этом определяются имена или IP-адреса интернет-объектов, порты (возможно, pid), а также имена каталогов и проходы (напр., для access_log - /var/log/httpd/access_log). Отдельную задачу может составлять хранение и передача паролей, например для баз данных.
Процедура описания проблемы начинается с определения базового языка программирования высокого уровня, выяснения области, к которой проблема относится. Это может быть сделано в результате диалога компьютер-программист или посредством задания списка ключевых слов.
Определение области проблемы производится в диалоговом режиме по-этапно:
Вычисления, включая параллельные
Анализ текста и его преобразование
.............................................................................
Решение задач пункта Д и З может сильно зависеть от свойств имеющегося оборудования (напр., SNMP или SDN).
Каждый из пунктов может стать корнем дерева субпроблем и представлять собой URL перехода к процедуре уточнения.Далее после выбора на первом этапе осуществляется уточнение типа проблемы (например, Г, измерение трафика, регистрация сетевых атак (например, посредством IDS, выявлением необычного поведения), динамика роста объема данных и т.д.).
Далее проблему надо разбить на подзадачи, для каждой из которых следует сформулировать задание и провести поиск в банке алгоритмов. Когда число примитивов станет достаточно большим, можно будет пополнять банк описаний алгоритмов, за счет программ, созданных на основе примитивов.
Перед помещением описания алгоритма в банк данных надо определить является ли данная программа достаточно изолированной и универсальной, имеющей самостоятельное значение. Если это так, готовится исчерпывающее ее описание, и она заносится в банк. Рассматривается возможность расширения функциональности программного модуля с управлением входными или выходными параметрами, задаваемыми программистом.
Если это не так, программа может быть разбита на части, каждая из которых станет независимым модулем, укладываемым в банк.
Рекорд БД алгоритма должен содержать:
Структура банка описаний алгоритмов. Для каждого описания алгоритма фиксируется:
В секции “описание” должны быть названы все необходимые библиотеки с указанием места, где их можно найти, и инструкции их установки. Установка библиотек должна выполняться специальной программой - конфигуратором. Желательно создать скрипты, которые позволят автоматизировать процедуру установки библиотеки.
Как делить проблему на части? Разумно описать эту процедуру в синтаксисе PDL. На сегодня эту задачи разумнее всего поручить программисту.
Любой алгоритмический язык может содержать в себе:
……………………………………..
Основу описания алгоритма составляют именно эти процедуры.
В любом алгоритмическом языке имеются также процедуры описаний (переменных, массивов, списков, строк, указателей и т.д.) и большое число вспомогательных операций, которые к описанию проблемы не имеют прямого отношения.
Любой алгоритмический язык является частным случаем описания проблемы, он описывает алгоритм. Алгоритм – это список операторов, исполнение которых, реализует решение проблемы. Как правило, описание проблемы многозначно. Например, даже задание “вычислить sin(X)” может быть реализовано разными способами: через библиотечную функцию, с помощью разложения в ряд или посредством таблицы значений и интерполяции, возможен вариант, исключающий ошибки при больших значениях числа радианов. Какой способ будет выбран? Это можно фиксировать, задав уточняющие вопросы пользователю или реализовав вариант “по-умолчанию” (напр., библиотечная функция).
Не нужно думать, что удастся создать универсальный язык описания любых проблем. Могут быть созданы и существовать языки описания для конкретных предметных областей (по аналогии с алгоритмическими языками).
При описании алгоритма каждой строке кода соответствует определенная команда или последовательность команд процессора. При описании проблемы генерируемая программа может зависеть не только от текущего фрагмента текста, но также от предыдущего и, возможно, последующего текста. По этой причине синтаксис языка PDL должен минимизировать такие возможности и сократить многозначность интерпретации его фрагментов.
Когда общаются люди, вопросы формулирует человек и отвечает на них также человек. Компьютер сам не может сформулировать вопрос, он может лишь выполнять заложенные в него человеком программы. Компьютер, как правило, может воспринять лишь определенные заранее вопросы или ответы. Диалоговые решения привлекательны в силу их определенности и однозначности, но они перестают быть эффективными, когда число вариантов становится слишком большим.
Можно попытаться построить диалоговое дерево, структура которого может меняться в зависимости от полученных ответов. Такое решение может быть функционально достаточно богатым.
Если рассмотреть задание типа “Обеспечить безопасность WEB-сервера” (вариант описания задачи на естественном языке), то степень неопределенности возрастает многократно. Ведь нужно знать, о какой безопасности идет речь. Это может быть сохранность данных, противопожарные требования, внешние электромагнитные наводки, воровство оборудования, отключение электропитания, ошибки в программах, отказы оборудования, ошибки или преднамеренные действия эксплуатационного персонала, атаки хакеров и т.д. Нужно также определить уровень безопасности (процент угроз, которые будут парированы, предлагаемыми мерами).
Неопределенность может быть убрана частично или полностью с помощью диалога с программистом-пользователем.
Каким бы большим ни был депозитарий, он не может охватить все многообразие проблем (оно бесконечно), но по мере роста объема депозитария вероятность решения задачи в рамках PDL будет постепенно увеличиваться и экспоненциально приближаться к единице (хотя и никогда 1 не достигнет). По этой причине желательно в депозитарий помещать близкие по назначению программные модули.
Еще одной важной задачей должен быть метод поиска нужных описаний алгоритмов в банке-депозитарии. Полезно предусмотреть контроль процесса выбора результата поиска со стороны пользователя-программиста.
В депозитарии должны храниться исходные тексты программ, чтобы было легко находить и устранять выявленные ошибки. Для каждого языка высокого уровня должен существовать свой депозитарий.
Среди программных модулей могут быть модули-примитивы, решающие некоторые узкоспециализированные задачи (например, программы-функции).
Примитив – программа, решающая одну и только одну проблему (аналог элементарных функций). Примитивы должны храниться в собраниях типа традиционных библиотек.
Программа может представлять собой список имен примитивов или модулей, извлеченных из банка, между которыми могут вставляться короткие программы на Perl.
Желательно, чтобы примитивы и любые модули в банке алгоритмов были выполнены с соблюдением правил Хольцмана, что будет способствовать минимизации числа программных ошибок.
Мой опыт последнего времени говорит о том, что программные прикладные пакеты (диагностика атак межведомственного суперкомпьютерного центра и диагностика рабочих характеристик и защита сервера saturn.itep.ru) содержат порядка 20-30 тысяч строк кода. Правила Хольцмана упрощают выявление локальных ошибок, но усложняют обнаружение алгоритмических ошибок в сложных программах. Ведь в ядре любой операционной системы содержится более 40 миллионов строк кода, а при длине программного модуля 50 строк (одно из требований правил Хольцмана) это означает, что при таких условиях ядро ОС содержит 800000 программных модулей, взаимодействие которых трудно отследить. Пакет защиты сервера saturn.itep.ru структурно довольно прост, он состоит из нескольких изолированных задач.
Помимо программных модулей на компьютере присутствуют конфигурационные файлы, формируемые программой-конфигуратором.
При традиционном методе программирования программист сначала определяет алгоритм вычислений и только после этого приступает к составлению программы на алгоритмическом языке. В случае использования PDL алгоритм задается в описании последовательностью action-objects-attributes. Компьютер не может выработать алгоритм самостоятельно (во всяком случае пока).
Описание задания, даже выполненное строго по правилам, не гарантирует того, что существует решение описанной проблемы. Возможно, что одному описанию может соответствовать несколько программ реализации. Синтаксис языка должен минимизировать такую вероятность.
Было бы важно иметь утилиту, которая бы контролировала отсутствие внутренних противоречий в описании и проверяла реализуемость задания.
Описание задания начинается с комбинации символов “<#”. Далее следует имя проблемы . name=”XXXX”; , где строка символов ”XXXX” определяет имя описываемой проблемы. Допустимы любые символы из стандартного набора asci. Описание завершается комбинацией символов “#>”, за которой следует пробел.
Вводим системную переменную context, значение которой может изменять функцию любого оператора, например, action. Изменение context происходит простым присвоением, например, context=filter;.
Внутри описания проблемы может содержаться описание субпроблемы. Начало описания субпроблемы отмечается <#, а завершение - #>. Начальный и завершающий разделители отделяются от описания проблемы пробелом.
Для описания задания определяется название проблемы и действия, которое должно быть реализовано, acts (actioni), где функция каждого значения actioni должна быть подробно описана:
@acts=("making up a program", find(symbol, letter, word), calculate(value), determine, develop, create, form, write, read(record, line), load(data), detect(event, attack, interrupt, parity error, queue overflow, moment, frame in/out), measure(value, temperature, pressure, voltage, current, traffic, level, capacity), fix (time, position, value), analyze(data,value,string,line), stabilize(value), convert from, convert to, approximate, arrange, interpolate, extrapolate, minimize(level, value), maximize(level, value), encode(value, string), decode, copy(value, string, file, line, record) (to/from), transfer (to/from), open (files), restore, optimize(value), send(to/from), IN, OUT, present, filter,…);
Число необходимых операций может быть бесконечным, но число слов-описаний action не может быть бесконечным, хотя бы потому, что конечно число слов естественного языка. Объясняя смысл задания на естественном языке, люди пользуются дополнениями, определениями, атрибутами и другими способами уточнения смысла. Язык PDL тем более не может иметь слишком большое число слов action. По существу мы имеем многомерное пространство смыслов, каждое из измерений которого задается словом из множества actioni. Следует снабдить каждое слово actioni описанием, где будет указаны возможные значения атрибутов и допустимые операторы object.
actioni.atrib=value;
Помимо описаний action можно ввести описания how, by, (характеризующих то, как должна решаться проблема, например, для дифференциальных уравнений….)
Если для описания какого-то задания окажется недостаточно числа типов action, можно попытаться использовать какие-то внешние библиотеки, примитивы или описать дополнительное субзадание. Описание такого субзадания будет иметь формат обычного PDL-описания с заданным уникальным именем.
Для каждого вида действия action надо построить семантическое дерево (таблица 1) при этом определяется список объектов, атрибутов, свойств, параметров и характеристик. Эти семантические деревья нужно записать в банк данных.
Хорошее описание проблемы позволит минимизировать вероятность алгоритмических ошибок.
Надо задать процедуру определения и описания всех языковых объектов, которые ранее не были описаны или определены (вновь вводимые). Для этой цели можно применить формализм Бакуса-Наура (BNF).
При составлении описания можно начать с диалога, где сначала задается имя будущей программы, затем определяется вид, атрибуты и характеристики action.
Надо стандартизовать представление формул (отдельная секция языка). Начнем с представления формул в рамках языка Perl. Пример:
<# name=”XXXX” описание <# описание субпроб.1 #>…<# описание субпроб.2 #>… #>
Число субпроблем не лимитировано, оператор name позволяет присвоить описанию имя. Под этим именем будет в дальнейшем фигурировать сформированный программный модуль.
Внутри описания субпроблемы может содержаться описание другой подпроблемы или даже нескольких субпроблем.
Каждой субпроблеме должна соответствовать определенная сигнатура, используемая при поиске в банке описаний. Поиск может проводиться последовательно с использованием цепочки сигнатур. Однозначность обеспечивается введение жестких правил для формирования сигнатур.
Оператор может встречаться в описании в любом месте и только один раз. Формат:
IN{строка описания входных данных};
Строка описания IN может содержать имена файлов, терминальный ввод, переменных, строк, массивов, имена баз данных и таблиц, а также URL в том числе и удаленных. Здесь могут присутствовать также описания форматов и атрибуты (например, имя-пароль-сертификат). Источником входных данных могут быть отклики на запросы к поисковым системам, а также почтовые сообщения, а также голосовые и графические данные. Следует разделить данные, заданные при описании задания, и информацию, получаемую уже в процессе выполнения задания.
Оператор OUT может встречаться в описании в любом месте и только один раз. Формат:
OUT{строка описания выходных данных};
Строка описания OUT может содержать имена файлов, включая графические и медийные, переменных, строк, массивов, URL, mail-адреса, телефонные номера для SMS, и атрибуты типа имя-пароль. В перспективе могут появиться и голосовые данные. Здесь могут фигурировать также описания форматов и типов терминального оборудования, в том числе управляющих сигналов. Имеются в виду описания, предназначенные и анализируемые программно, а не человеком.
В случае несовпадения формата IN или OUT с требованиями из описания actiona выдается сообщение об ошибке.
При необходимости описать несколько глобальных переменных или массивов можно использовать оператор описания globals.
Для описания глобальных переменных и массивов в начале описания PDL используется оператор intro:
<intro><список переменных и имен массивов</intro>
Имена глобальных переменных начинаются с последовательности символов G., например, G.example.
<b>Global</b> ::=
Это требование диктуется необходимостью уникальности имен глобальных переменных и малой вероятности наличия таких имен в текстах программных модулей, извлеченных из банка алгоритмов, или в подпрограммах.
Отсутствие модификаций глобальных переменных в модулях, взятых из банка алгоритмов, желательно проверять автоматически программным способом.
Внутри программных модулей, в том числе извлеченных из банка, а также в подпрограммах глобальные переменные не могут быть модифицированы. Это уменьшит вероятность ошибок из-за скрытой модификации переменных. Описание глобальных переменных и массивов возможно только в одном месте (в начале).
<action> - что сделать
<action.attribute> - конкретизует и уточняет действие оператора<action>.
<object> - над чем производится данное действие оператора (класс <action>)
<object.attribute> - относится к объекту и уточняет его смысл и значение
<action description> - (Описание) точность, скорость, особенности алгоритма.
Каждому типу action может соответствовать библиотека примитивов, а также один или более программных модулей в банке описания алгоритмов (или библиотека таких модулей).
Каждому типу action может быть поставлено в соответствие семантическое дерево связей, набор таких деревьев можно поместить в банк данных.
Каждой цепочке action(i) – object(j) – attribute(k) – parameter-list может соответствовать примитив из библиотеки, сопряженной с данным оператором action, или модуль из банка описаний алгоритмов.
Такая цепочка может использоваться при поиске программного модуля в банке описаний алгоритмов. Могут существовать атрибуты как у операторов action, так и у объектов.
Возможны варианты, когда для получения нужных входных параметров требуется произвести определенные вычисления. В простых случаях такие расчеты можно запрограммировать явно, например:
<perl>текст программы </perl>
где "текст программы" - программа на языке perl.
Оператор approximate (распределение, набор данных, список значений для заданного набора параметров, например, времени
Оператор find служит для поиска программных модулей в банке описаний (наш внутренний депозитарий).
Оператор calculate предназначен для выполнения вычислений. Такие вычисления могут выполняться определенным программным модулем, его можно попытаться найти с помощью оператора find, или осуществить посредством программы, написанной программистом.
Оператор convert from/to (из одного представления в другое, например, из Windows-1251 в UTF8 или наоборот, преобразование графических форматов, упорядочить элементы списка по возрастанию/убыванию
Оператор copy (file, cathalog, array, DB-bank),
Оператор create (picture, distribution, list, file, DB or DB-table)
Оператор determine (максимум/минимум функции, корни уравнения, path, каталог, четность-sha2, объема свободной оперативной или виртуальной памяти)
Оператор detect (attack, interrupt, parity error, queue overflow, frame on input),
Оператор develop (input data,
Оператор decode (value, array, string
Оператор encode (value, array,
Оператор form(
Оператор interpolate/extrapolate (value,
Оператор описания librs{список имен библиотек} служит для подключения библиотек (позволяет транслятору сформировать список подключаемых библиотек с помощью последовательности строк use <имя библиотеки>;
Оператор load (file, picture, array,
Оператор measure служит для запуска процесса измерения, например, температуры, напряжения, силы тока, давления, емкости, мощности трафика, потока определенных типов пакетов, байт, ошибок четности
Оператор open(file1,file2,…,filen); служит для открывания файлов. Можно сделать handle, базирующимся на имени самого файла. В дальнейшем нужно предусмотреть возможность задания операторов открытия (read/write=RW, readonly=RO, trunс=TR, create=CR),
Оператор present (сформировать HTML-page, представить полученный результат in form of list, table or plot,
Оператор read (file, record, string,... from
Оператор write (file, record, string, table, value,.... to
Оператор send (file, record, string, table, value,... from/to
Из рис. 2 видно, что каждому оператору action соответствует разное число object. Что еще важнее, области object для разных операторов action перекрываются. Задав конкретный оператор actiona, мы выделяем некоторое подмножество слов object. В описании оператора actiona могут содержаться требования к операторам IN и OUT.
Если для выбранного типа action нет или не нужно вводить атрибут, то в описании проблемы он может отсутствовать или на его месте записывается action.atrib0. В сигнатуре запроса программного модуля это поле не должно содержаться, так как оно может иметь субъективный характер.
Внутри некоторых action могут находиться свои операторы действия (см. описание программного модуля filter.pl, где вводится оператор remove????).
Далее мы определяем конкретное значение objectb. Контекстные значения object, имеющие идентичные имена, могут иметь совершенно разные значения и функции. Нужно также учесть, что после оператора action может следовать атрибут операции, а не объект.
На данном этапе исследований выделение и исчерпывающее описание субпроблем должен выполнять сам программист в рамках описания основной задачи. Описание переменных, констант, массивов выполняется согласно синтаксису языка Perl.
Язык PDL имеет целью минимизировать тезаурус названий процедур, объектов, параметров, свойств и вообще характеристик языковых объектов и убрать по возможности многозначность смыслов.
Важными характеристиками проблемы являются списки и форматы входных и выходных параметров. В некоторых случаях эти списки однозначно определяют проблему. Но существуют проблемы, где на фазе описания эти параметры полностью определить нельзя, параметры задаются при запуске программы, вычисляются или считываются откуда-то в процессе ее исполнения. К таким проблемам относятся, например, задачи управления или оптимизации.
Одной из целей PDL является разбиение проблемы на части, с тем, чтобы упростить поиск программных модулей в депозитарии описаний.
Следует разделять задание входных параметров при описании проблемы и при обращении к программному модулю в процессе исполнения кода. Входные параметры на фазе описания проблемы могут задаваться явно, когда при обращении задается имя переменной, массива и т.д., и неявно – через функцию, подпрограмму, указатель или каким-то иным способом.
Список входных параметров на фазе описания проблемы может задаваться в диалоговом режиме (число параметров, конкретные значения, типы параметров, возможные диапазоны значений и т.д.). Число параметров и диапазоны значений важны для выявления ошибок, в процессе описания задачи, при трансляции, а также при исполнении кода.
Для минимизации многовариантности вводим системную, глобальную переменную context. Эта переменная может допускать вариацию функциональности операторов в разных контекстных обстоятельствах.
Попытаемся описать задание для создания скрипта типа filter.pl, который удаляет из файла access_log, рекорды, связанные с работой поисковых серверов, а также запросы рисунков, ссылки на которые имеются в HTML-тексте.
program_name="filter.pl";
IN="/var/log/http/access_log";
OUT="/home/httpd/htdocs/saturn/attacks/ids/access_log.filt";
@list_of_exceptions=(".gif",".GIF",".jpg",".ico",".css",".png","robots.txt",".crowl.","crowl.daidu",
"yandsearch?","semenov.itep","robot02.rambler","/bots","spider.html","bot.html","robot3.rambler",
"robot06.rambler","robot07.rambler","robot7.rambler","robot14.rambler","spider6.mail","spider01.yandex",
"spider25.picsearch","spider44.yandex","spider18.yandex","spider55.yandex",".googlebot.com",
"crawl.baidu.com","dotnetdotcom.org","search.msn.com","msnbot",".cuil.com","crawl.yahoo.net",
"bredband.telia.com",".us.archive.org",".naver.jp","av16570.comex.ru",".domolink.tula.net",".setooz.com",
"gigablast.com","78.41.98.38","78.41.98.166","94.103.89.246","robot07.rambler.ru","robot9.rambler.ru",
"spider27.picsearch","spider30.picsearch","spider23.picsearch","turbospider.yandex","robot7.rambler.ru",
"spider09.yandex");
context=filter; action=remov
В этом случае описание проблемы имеет вид:
OUT{} = all records from IN, not containing elements from @list_of_exceptions; или
<# Name=”filter.pl” OUT{} = all records from IN, not containing elements from @list_of_exceptions #>;
Строка, написанная красным цветом, может стать основой сигнатуры при поиске в банке описаний. Нужно подготовить стандарт для требований синтаксиса описания сигнатур (сепараторы, допустимый порядок). В приведенном примере присутствует дефект - название списка образцов (@list_of_exceptions). Для преодоления этой трудности можно сделать этот список вторым параметром в операторе IN. Здесь нужно учесть, что описание задания (проблемы) пишет один человек, а сигнатуру для поиска – другой человек (или даже программа), и они могут одни и те же вещи формулировать по-разному.
Нужно сформулировать правила интерпретации слов “records”, “not _containing”, “containing”, “elements”, “from”.
record – запись в базе данных, если контекст соответствует DB, или строка текстового файла, если контекст соответствует file. records считается эквивалентным record. Множественное число используется для большей естественности и понятности текста описания.
element - object from some list.
from – указывает на источник, откуда берутся данные (последующее слово). Зависит от типа оператора action.
to - указывает на место, куда будут переноситься данные (противоположно from). Зависит от типа оператора action
for - указывает на цель операции (или объект), характеризуемой последующим словом.
“containing”, “not _containing” – атрибуты объектов, характеризующие их содержимое. Зависит от типа оператора action.Список объектов
obj=(records, elements, words, symbols, strings, values); - список возможных объектов.
Список атрибутов
Одним из методов минимизации ошибок может быть написание модулей, которые покрывают как можно более широкий круг задач, например, программа вычисления полинома (Y=poly(X)) произвольной степени n (Y=anXn + an-1Xn-1 +…+ a0). Здесь список параметров будет включать значение X, значение степени полинома n и массив коэффициентов полинома ai (n+1 коэффициент). При реализации программы для Poly можно для ускорения вычислений воспользоваться алгоритмом Горнера.
Описываются свойства объектов. Задается тип результата (OUT), который должен быть получен при выполнении программы. Описывается формат результата.
Хотя язык PDL пока не сформирован, можно предположить формулировку задания: Имеем набор значений функции x0,A0; x1,A1;....; xNAN (например, результаты измерения потока данных в байтах в моменты хi). Эти данные соответствуют определенным моментам времени или значениям переменной x. А носит статистический характер и имеет распределение Пуассона. Нужно аппроксимировать эти данные полиномом степени M, причем М< в следующем формате (вариант PDL): IN= x0,A0; x1,A1;....; xNAN; xi - current parameter values (например, времени); Аi - Poisson variables; approximate Ai with Chebyshev polynomial of optimal power. Интерпретатор PDL должен превратить это описание в текст программы на языке высокого уровня. Такая программа будет содержать примерно 300 строк кода. Транслятор должен найти алгоритм вычисления обратной матрицы (для значений коэффициентов перед полиномами) и формулу для оценки аппроксимации по критерию Фишера. Результатом вычисления будет набор коэффициентов перед полиномами Чебышева, а также значение степени старшего полинома. Элементы языка надо отрабатывать на конкретных задачах, например, мониторинг входного и выходного трафика компьютера, маршрутизатора или коммутатора (библиотека MRTG). Для описания глобальных переменных и массивов в начале программы описания PDL используется оператор intro: Это требование диктуется необходимостью уникальности имен глобальных переменных и малой вероятности наличия таких имен в текстах программных модулей, извлеченных из банка алгоритмов, или в подпрограммах.
Отсутствие модификаций глобальных переменных в модулях, взятых из банка алгоритмов, желательно проверять автоматически программным способом. Внутри программных модулей, в том числе извлеченных из банка, а также в подпрограммах глобальные переменные не могут быть модифицированы. Это уменьшит вероятность ошибок из-за скрытой модификации переменных. Описание глобальных переменных и массивов возможно только в одном месте (в начале). Оператор задания входных параметров программного модуля IN:
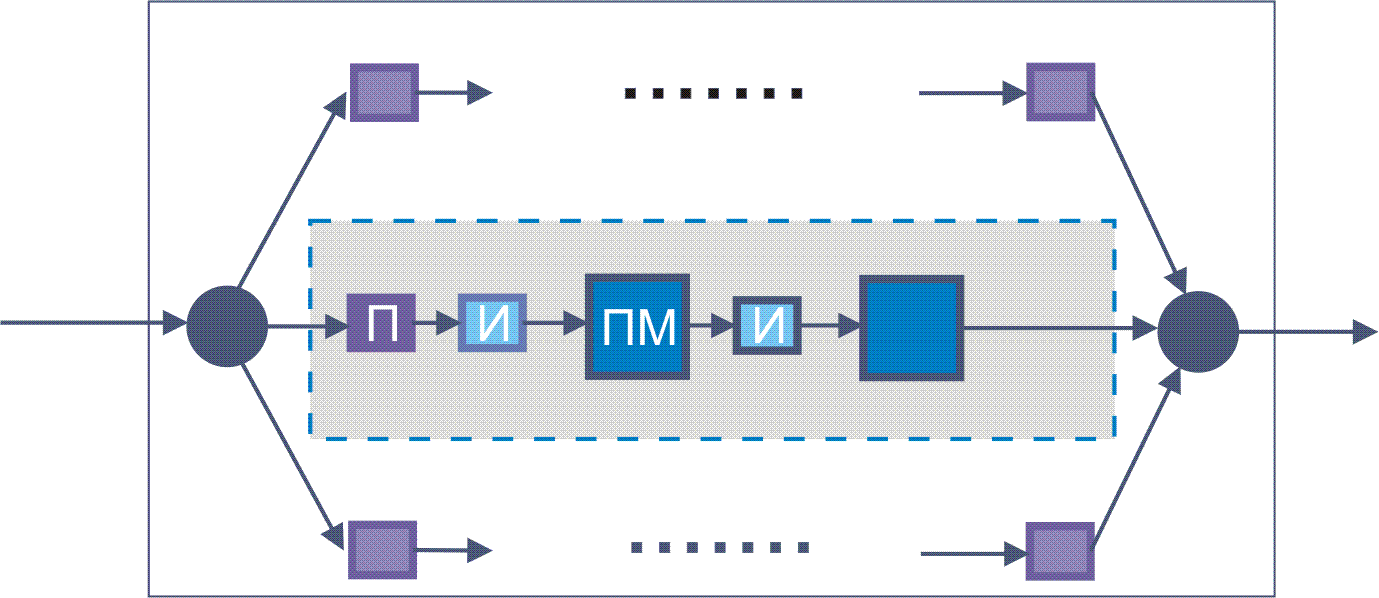
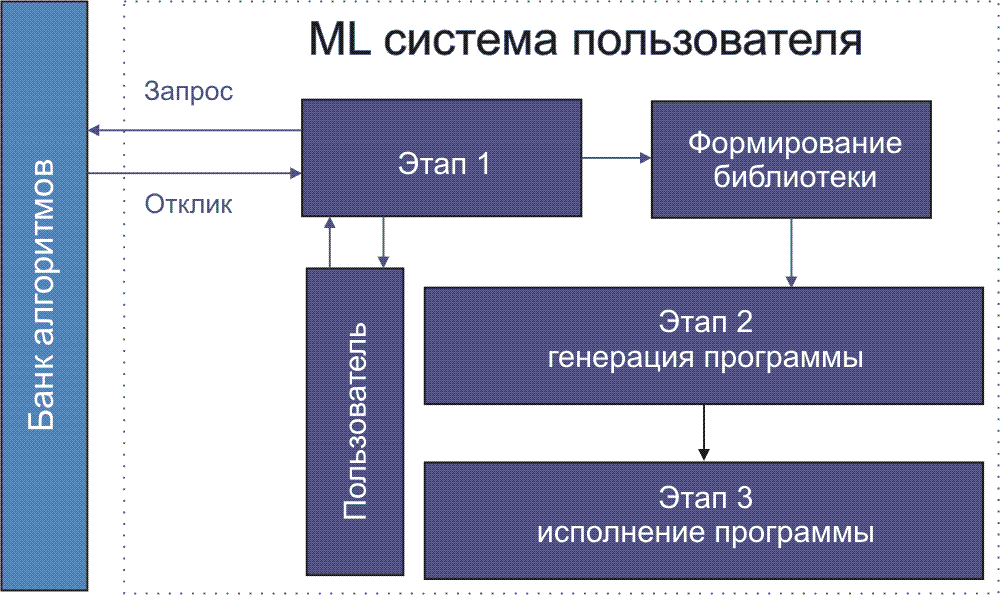
IN( n ::= integer. an, an-1,…,a0 ::= STRING. X ::= digit+. Допускается задание n, an, an-1,…,a0 и на фазе исполнения. Если на фазе исполнения какие-то параметры не заданы, берутся значения по-умолчанию, заданные на фазе описания. Если значений по умолчанию не было задано, отладчик в этом случае выдает уведомление об ошибке. Оператор задания свойств выходных параметров OUT: OUT( Оператор DETERMINE(name) предназначен для запуска процесса диалога с целью определения процедур (работает на первом этапе, см. рис. 4), параметров, конфигурации и пр. Параметр name определяет тип поиска (что ищется). В случае задачи управления обычно нужно задать имя-IP-пароль SNMP-сервера, а также имя базы, пароль базы данных, имена таблиц, если какая-то база данных должна использоваться. Эти данные задаются в процессе конфигурирования (этап 1, рис. 4). Если пользователем является root, он эти параметры знает, если нет, то он должен обратиться к администратору. В процессе описания проблемы эти параметры могут быть переданы компьютеру в результате диалога или путем заполнения специальной формы (напр., на этапе 2, рис. 4). В случае работы с SNMP-сервером может потребоваться информация об именах переменных (зависит от типа оборудования и протоколов) и пароль для сервера. Корректность IP-адресов, вводимых в диалоговом режиме, должна проверяться в реальном масштабе времени, это же относится к именам переменных для MIB. Если в банке данных соответствующей записи нет, а задача не разбивается на части, то текст программы составляет сам программист. Задачи управления, как правило, из-за необходимости обратных связей, характеризуются графами с циклическими структурами. Списки и типы входных и выходных параметров могут быть заданы с помощью процедуры диалога или путем заполнения форм. Введенные параметры записываются в специальный profile с оговоренным именем для его дальнейшего использования. Если для решения проблемы нужны HTML-страницы, то они могут быть извлечены из банка алгоритмов, если эти модули там имеются. Таким страницам перед укладкой в банк присваивается имя и пишется описание. В противном случае их создает сам программист с привлечением информации о выходных параметрах программных модулей (например, графические файлы или значения переменных). HTML-файлы могут генерироваться из PERL или модифицироваться посредством JavaScript. В сложных случаях нужно выявить алгоритм расчета и поискать этот алгоритм в банке данных. Сходные проблемы могут возникать и решаться аналогично для выходных параметров. Следует предусмотреть возможность выявления ошибок при описании проблемы (аналог debugger). Он будет контролировать корректность синтаксиса описания проблемы и выявлять конфликты параметров. Транслятор с метаязыка должен превращать описание проблемы в последовательность процедур, перечисленных выше (например, имен программных модулей, примитивов и пр.). Возможен вариант формирования текста на одном из известных алгоритмических языков высокого уровня (например, PERL). Предварительно выясняется, нет ли нужных подпрограмм, функций или описаний алгоритмов в банке данных. Если они в банке есть, их тексты вводятся в текст искомой программы. При обнаружении нужного алгоритма в банке, пользователю на экран может быть выдано полное описание программного модуля. Программный примитив - описание проблемы одним простым предложением. Далее могут следовать описание входных параметров и характеристики и форматы выходных данных. Примитив обязательно должен содержаться в банке алгоритмов. Результирующая программа будет формироваться из суперпозиции примитивов. Примитив эквиватентен библиотечному программному модулю. Среди примитивов могут быть модули подпрограмм, например, для вычисления полинома любого порядка, или факториала (Стирлинг), обращения матрицы, вычисление определителя матрицы произвольного порядка, упорядочивания списка по возрастанию или убыванию, вычисления среднего значения или дисперсии (для заданного списка результатов измерения) и т.д.. Описание проблемы по существу содержит в себе краткое описание алгоритма ее решения. Следует также обратить внимание на то, что так можно описать любую проблему и любой алгоритм. Рис. 1. Одна из возможных схем описания проблемы (prob_discr.gif) Рис. 1А. Вариант структуры описания с параллельными ветвями (П - примитив; И - программный интерфейс; ПМ - программный модуль) (ML-discr.gif) Определяем базовые понятия <action> - что сделать
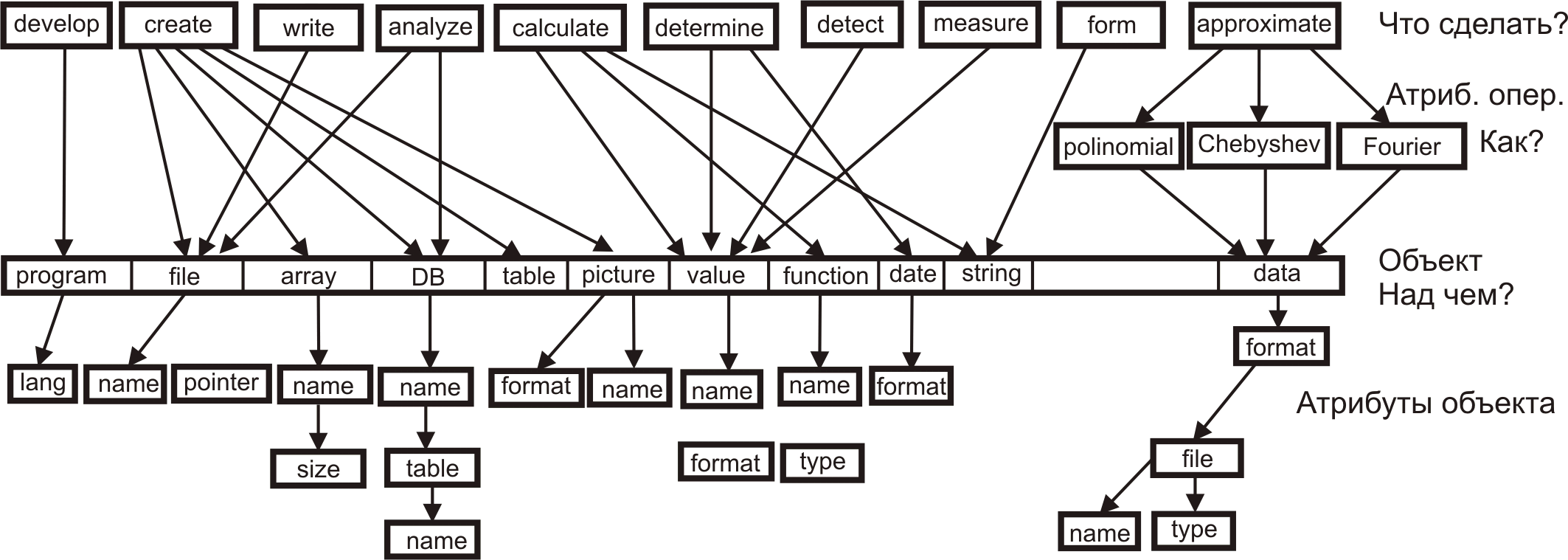
<action.attribute> - конкретизует и уточняет действие оператора Контекст описания может задать программист, составляющий описание проблемы в процессе диалога или явно. При этом выясняется область проблематики, перечень и типы входных данных, формат результата. Для задания контекста можно воспользоваться деревом таблиц идентификаторов контекста. Надо составить словарь стандартизованных имен операций и действий. Например (английские слова предпочтительнее): Далее для каждого слова, обозначающего операцию, может следовать атрибут, характеризующий операцию (напр., approximate with polynomial) и дополнение, указывающие объект, над которым будет выполняться операция (напр., разработать алгоритм). Атрибут может иметь определенные характеристики, например, степень полинома. Слово, обозначающее объект, может сопровождаться уточнением (напр. алгоритм вычисления, далее может идти уточнение вычисление чего и т.д.). Здесь может оговариваться и алгоритм вычисления. Эти слова образуют древовидную семантическую сеть. Слова этой сети будут являться базовыми словами языка описания проблемы и использоваться транслятором. Вероятно, разумно ограничиться словами на английском языке, тем более, что в английском меньше вариаций слов по падежам и пр.. Далее создается словарь дополнений (имен) объектов над которыми выполняются действия (операции). Например:
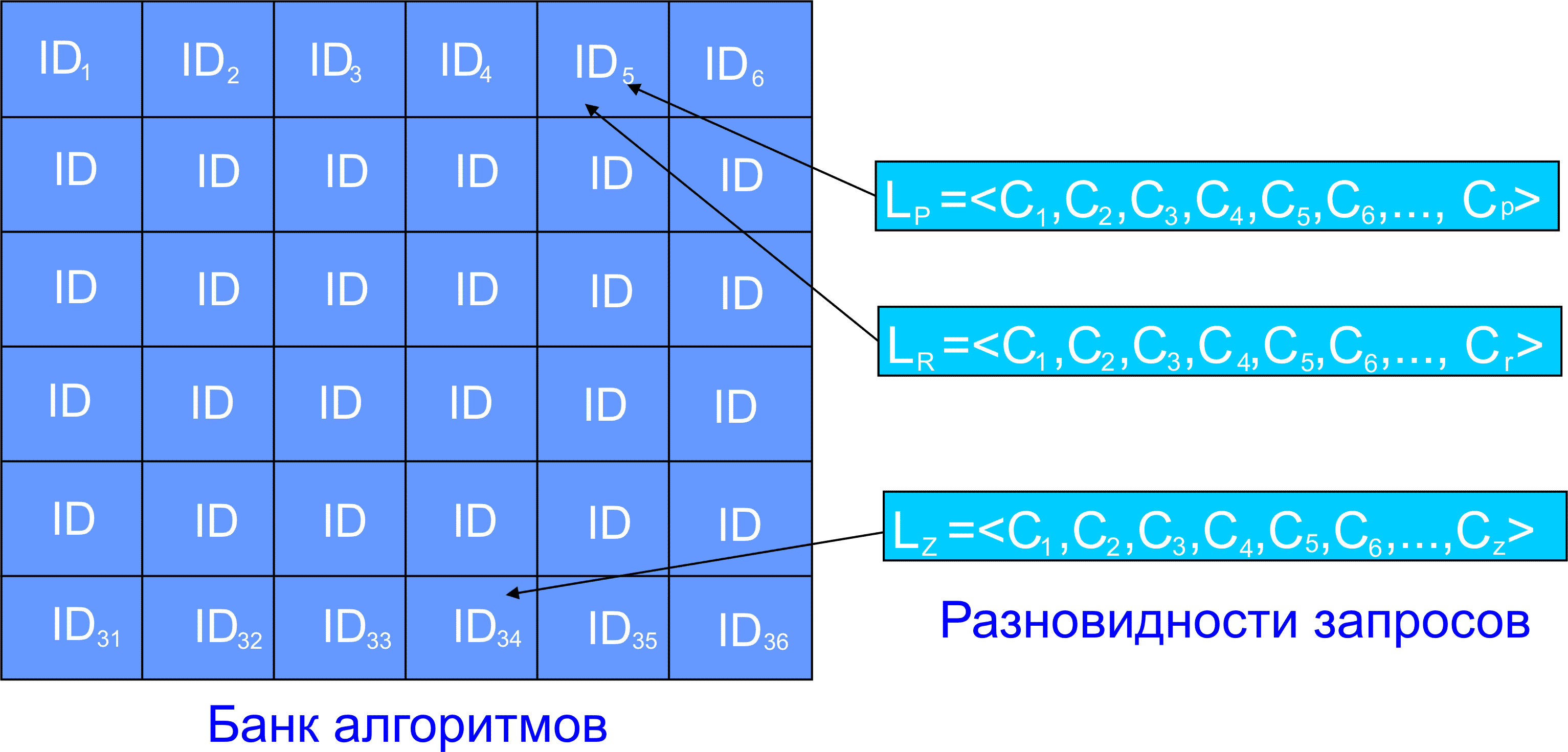
программа, файл, массив, список, значение, константа, дата, строка, символ, банк БД, таблица БД, указатель, предельное значение (параметра, индекса...), program, routine, file, array, list, web-cite, value, constant, date, string, symbol, DB, table, pointer, limit, approximate, convert(from/to), Рис. 2. Семантическое дерево операций Каждая операция из верхнего ряда рис. 2 может подразумевать бесконечное число вариантов. Число их не лимитировано. Мощность множества операций (actions) MA=∞. Если мы выбрали какое-то конкретное значение action, мы выделили некоторый достаточно большой (возможно бесконечный) объем в этом многомерном пространстве. Объекты (второй ряд рис. 2) позволяют уточнить задание операции и сократить этот объем. Объект определяет то, над чем будет произведена та или иная операция, заданная action. Атрибуты объектов производят дальнейшее уточнение и сокращения объема. Конечной целью является сведение мощности оконечного множества к 1 (MA=1). Таблица 1 показывает возможность присутствия в описании проблемы атрибутов action. Здесь далее речь идет о программах на языке Perl. Программы для обработки прерываний здесь не рассматриваются. Выявлять смысловые связи можно, анализируя семантическое дерево по схеме, сходной с алгоритмом определения контекстных значений. Значения из таблицы 1 могут обозначаться в формате: action.atrub.object.obj_par (сепаратором (разделителем полей) является символ точка). Таблица 1. Семантические связи Для названий operation, operation attribute, object, object parameters можно ввести префиксы, которые позволят различать их функциональность даже для случая совпадения имен. Например, oper.develop; oper.create; op_atr.polinomial; DB.name; meas.val.format и т.д. Все эти объекты могут иметь атрибуты-определения (для слова программа - двоичная, исполняемая, переносимая, объектная, библиотечная, обработки прерывания, сетевая, реального времени). Но для слова программа (и, разумеется, и других) могут существовать дополнения, например, программа реализации, программа движения/перемещения и пр. Вводится системная переменная context, которая может быть целочисленной или символьной (строковой). Можно рассмотреть вариант с несколькими переменными contexti, что может расширить пределы вариации функциональности. Значение переменной context может модифицировать значения переменных, изменять работу функций или подпрограмм. Для каждого значения context может быть несколько переменных, функций или подпрограмм с одинаковыми именами, но с разной функциональностью или значением (в зависимости от значения переменной context). Когда значение контекста характеризуется строкой, например, "программа", допускается уточнение значения контекста в виде программа[код|вычисление] или программа[обучения] или програама[обучения|университет] или программа[внедрения|сетевой график]. Очередной шаг программной реализации-испытания предлагаемого нами метода надо сделать на основе программ мониторинга атак WEB-сервера. Для этого нужно переработать все модули saturn и уложить их в банк данных. Это программы анализа содержимого журнальных файлов access_log, error_log и secure, а также мониторинга входного-выходного трафика для заданных транспортных протоколов (MRTG). Это разновидность управления входными параметрами, но здесь не производится передача управления выбранному программному модулю (исполняемый модуль всегда один). К этому классу решений можно отнести также универсальную программу аппроксимации совокупности экспериментальных результатов полиномом, расчет коэффициентов корреляции и т.д.. Рис. 3. В блоке “Список параметров” может производиться подготовка (преобразование) данных. Техника адаптации программного модуля к конкретной задаче, позволит сократить суммарное число строк программы. А чем меньше строк в программе, тем меньше там ошибок. Возможен вариант задания входных параметров синтаксически на языке PDL (оператор IN). Список и формат выходных параметров определяется описанием из банка данных алгоритмов или самим программистом (OUT). Следует создавать программные модули, которые могут быть модифицированы с помощью списка входных параметров, или одного ключа-флага, определяющего модификацию алгоритма. Язык PDL определяет поведение системы на этапе описания проблемы (этап 1, рис. 4, здесь задаются некоторые глобальные переменные, например IP-адреса, протоколы обмена, периодичность опроса-измерения, результаты измерений или любые исходные данные), на этапе генерации исполняемой программы (этап 2) и на этапе выполнения этой программы (этап 3). На первом этапе задается алгоритмический язык, на котором будет написана программа (с помощью меню), выявляются программные модули из банка данных, которые могут быть использованы для формирования исполняемой программы. Определяется, какие модули могут быть сформированы компьютером и какие модули должен написать сам программист (эти программные модули должны быть созданы на этом этапе?). На втором этапе из этих модулей формируется текст исполняемой программы на выбранном алгоритмическом языке (в нашем случае - это PERL). Рис. 4. Структурная схема PDL (MLa.CDR) На первом этапе из найденных в банке программных модулей может формироваться библиотека программ, которая размещается на компьютере пользователя PDL и будет использована на этапе 2. Имя библиотеки также задается в диалоговом режиме. Система PDL устанавливается на компьютере пользователя, а банк алгоритмов размещается на удаленном сервере с доступом по протоколу SCP. Следует иметь в виду, что диалоговый метод пригоден только для формирования программ из ограниченного перечня. Если список вариантов программ велик или даже бесконечен (число терминальных узлов графа), объем диалоговой программы становится слишком большим (или бесконечным). Это утверждение нетрудно доказать. Диалоговые решения не должны использоваться, если число оконечных узлов превышает 20, так как в противном случае вероятность ошибки в такой программе окажется значительной. Желательно ограничиваться вариантами с числом оконечных узлов меньше или равным 10. Если число вариантов больше, программу надо разбить на смысловые этапы. Но в любом случае число оконечных узлов графа многоступенчатого поиска не должно превышать 50. Для поиска программного модуля в банке алгоритмов можно использовать принцип двумерного штрих-кода: имеем матрицу ключевых слов, пользователь выбирает нужные ему ключевые слова, кликая на них мышкой, после чего происходит поиск в банке алгоритмов. Для этого могут использоваться хэш-таблицы или техника deep-learning. Возможен интерактивный подход. При работе с ключевыми словами разумно использовать оператор RLIKE (REGEXP), позволяющий применять регулярные выражения, что делает возможным поиск как отдельных ключевых слов, так и их комбинаций. Каждой комбинации ключевых слов соответствует определенный двоичный код (ID записи в банке данных). Надо продумать, какой комбинации ключевых слов (двоичному коду) соответствует тот или иной алгоритм. Возможны разные схемы выбора ключевых слов. Наиболее реальным является вариант, когда любое из ключевых слов выбирается только один раз. Среди ключевых слов могут присутствовать имена-идентификаторы алгоритмов. В силу их уникальности они однозначно определяют тип алгоритма. Число ключевых слов в любом случае будет меньше числа описаний алгоритмов в банке. Нужно учитывать, что список ключевых слов, сформированный автором программного модуля, программисту/программе, посылающему запрос поиска, не известен. По этой причине нужно выработать правила, которым должны следовать авторы программ и программы, формирующие запросы поиска. Можно попытаться создать многомерный хэш-массив, где для каждого из измерений используются определенные ключевые слова. Имеем N ключевых слов. Слова образуют прямоугольную матрицу x*y=N. Для пользователя список ключевых слов (возможно с краткими пояснениями) представляются на нескольких последовательных страницах, давая ему возможность выбрать нужные слова кликаньем мышки. Каждый алгоритм имеет идентификатор (ID), число которых равно числу описаний в банке алгоритмов (М). Если ID нужного рекорда известен, можно послать запрос select для этого конкретного ID. Программа или пользователь выбирает q ключевых слов из списка (q<N). Выбранный набор ключевых слов L= Каждый список L должен иметь однозначное соответствие с IDk. Одному IDk может соответствовать несколько разных L. Пользователь может выбрать от одного до N ключевых слов (чем больше тем лучше). Некоторым списком выбранных ключевых слов может не соответствовать никакого рекорда в банке алгоритмов. Длины списков ключевых слов для разных программных модулей могут быть разными. Пользователю на экран выдается перечень возможных ключевых слов, из которых он может выбрать любую комбинацию. Ключевые слова могут выдаваться поэтапно. Сначала слова, определяющие область проблематики, затем – уточнение и т.д. Эти слова берутся из банка данных описаний алгоритмов. Рис. 5. Банк алгоритмов и разновидности запросов (key_words1.cdr)
Для случая poly(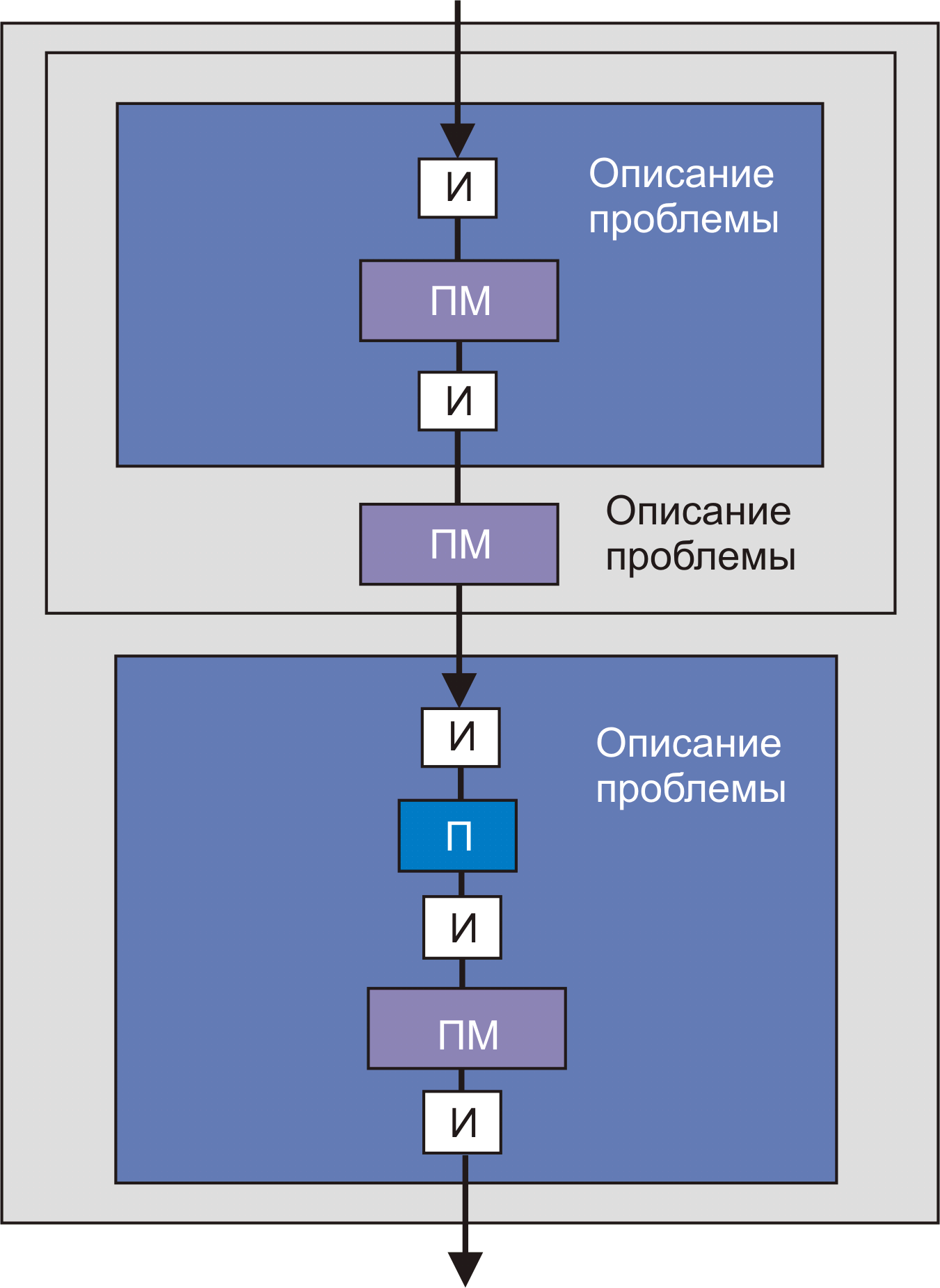
<object> - над чем производится данное действие оператора (класс
<object.attribute> - относится к объекту и уточняет его смысл и значение
<action description> - (Описание) точность, скорость, особенности алгоритма.
<find (db-bank-name, table-name, object-ID,...) смотри рис. 3 - запуск процесса поиска нужного алгоритма в банке описаний алгоритмов. Число банков может быть больше 1.
develop, create, form, write, read, calculate, determine, detect, measure, to fix time, analyze, approximate, present WEB-cite (сформировать WEB-страницу), sendСтроим семантическое дерево операций
действие/Operation(action) operation attribute (atrib), атрибут операции может отсутствовать Object
(operation over) Object parameters(obj_par) Task Назначение оператора develop Program name Что программа должна делать:Calculate;System control;....
Разработать программу create file
DB
table
array
picturename
name
name
name
formatСоздать файл, базу данных, таблицу DB, массив, рисунок write file
arrayПроизвести запись в файл, базу данных read file
recordПрочитать строку файла или запись BD analyze file
array
valueАнализ текста, массива данных или результатов измерения с целью, например, оптимизации calculate Fast; double-precision function
string
array
value
error
event
attack
overflowaccuracy Вычислить значение функции, строки, массива detect error
event
attack
overflowДетектировать ошибку, сетевую атаку, некоторое событие, например, переполнение буфера, массива measure value name
position
time
temperature
voltage
pressure
time/durationИзмерить положение какого-то объекта, например, с помощью GPS, время, напряжение, силу тока, давление form format picture Сформировать изображение, например, посредством gnuplot из массива входных данных approximate By polinomial,
Chebyshev,
Fourier,
Any other functiondata
dataname Аппроксимировать массив данных (результатов измерения) какой-то функцией, например, полиномом send to/from file
messageformat
matПереслать файл или сообщение по указанному адресу (в Интернет)
determine position
time
temperature
voltage
pressure
IP-addressОпределить время, температуру, напряжение, силу тока, давление, положение какого-то объекта convert from/to value,
string,
array,
picturename Преобразовать числовую величину, символьную строку или массив значений из одного формата в другой present text, pictures WEB-page Сформировать HTML текст WEB-страницы на основе имеющихся рисунков и текста 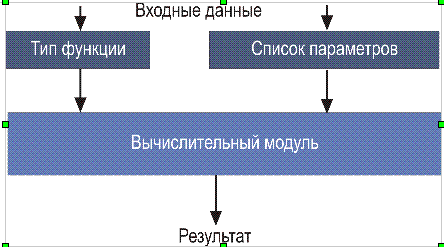
Диалоговый поиск программы в банке алгоритмов
Выбор того или иного рекорда должен происходить технологически сходно с оператором LIKE в MySQL (выборка по совокупности, где решение принимается по максимальному подобию комбинации ключевых слов) или RLIKE (см. стр. 18).
Начать исследования PDL можно с написания основных программ на PDL для ?диагностики WEB-сервера и для обеспечения его безопасности.
Здесь и далее имеются в виду атаки WEB-сервера, которые не может выявить стандартная антивирусная программа или IDS.
Виды атак. (linux-сервера)
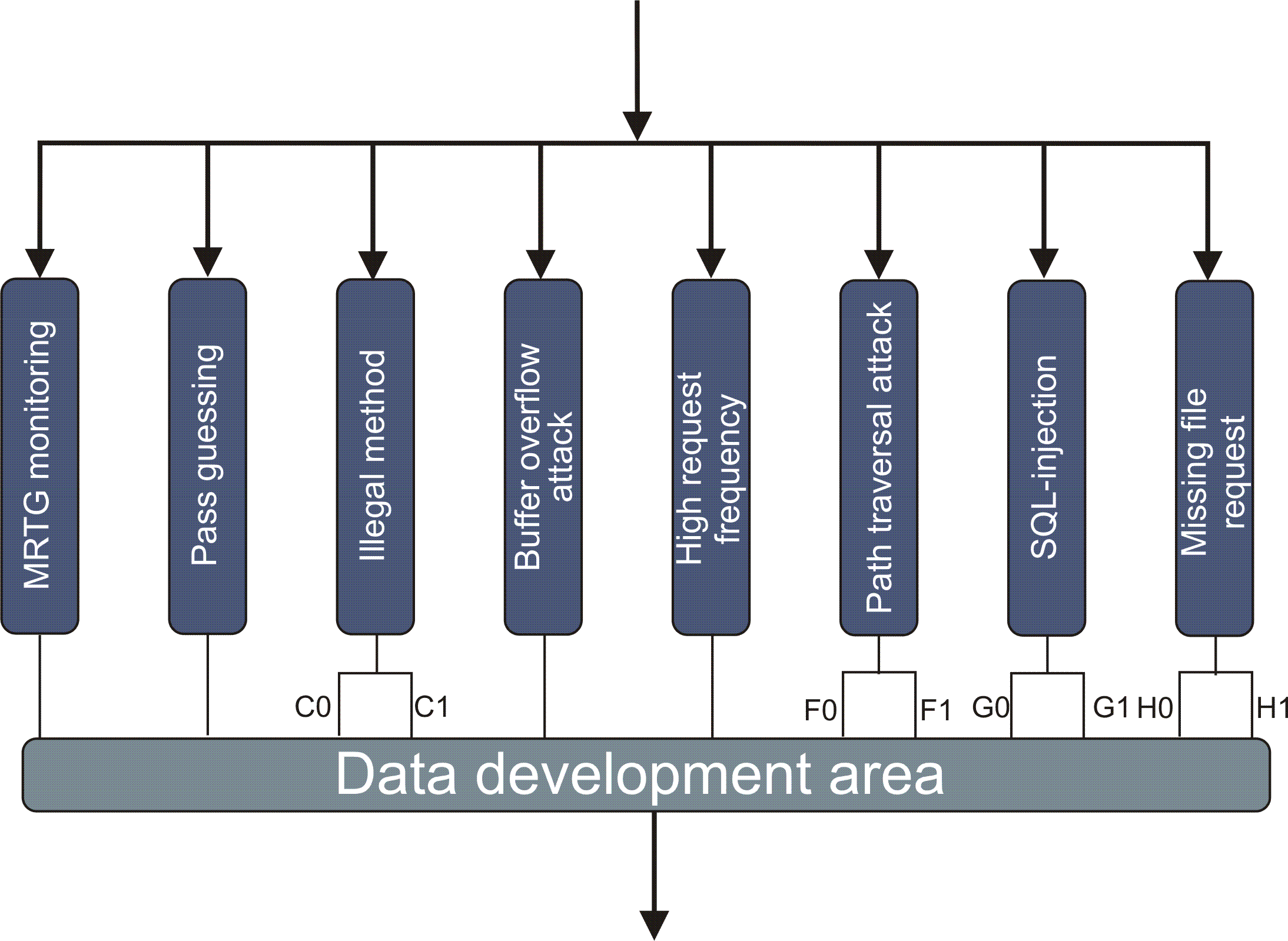
Рис. 6. Структура конфигурации программы безопасности WEB-сервера (attack_dvla.cdr)
Обозначения на рис. 6: C0 – case of usage put or delete methods. C1 – using methods post and so on. F1 – path traversal attack (in the file access_log there are lines "../" , "/../../../../", %2e%2e%2f, ..%c0%af or %2e%2e/). G0 - SQL-attack; G1 – the same but with no SQL-DB on computer. H1 – there is a request of the potentially dangerous file, which is absent on this WEB-site (request of file with known vulnerability).
Анализ mail-активности
Детектирование сканирования портов и SNORT-монитор (IDS)
Банк алгоритмов может обслуживать большое число PDL-пользователей. Банки должны быть тематическими, обслуживающими специфические классы задач и рассчитанные на определенный алгоритмический язык.
Список глобальных переменных модуля в банке данных должен быть приведен в описании модуля.
Диалоговый метод выбора алгоритма может использоваться только для ограниченного участка дерева выбора. Хотя диалоговый вариант пригоден для любого числа описаний в банке алгоритмов, использовать исключительно его вряд ли целесообразно из-за большого объема такой программы.
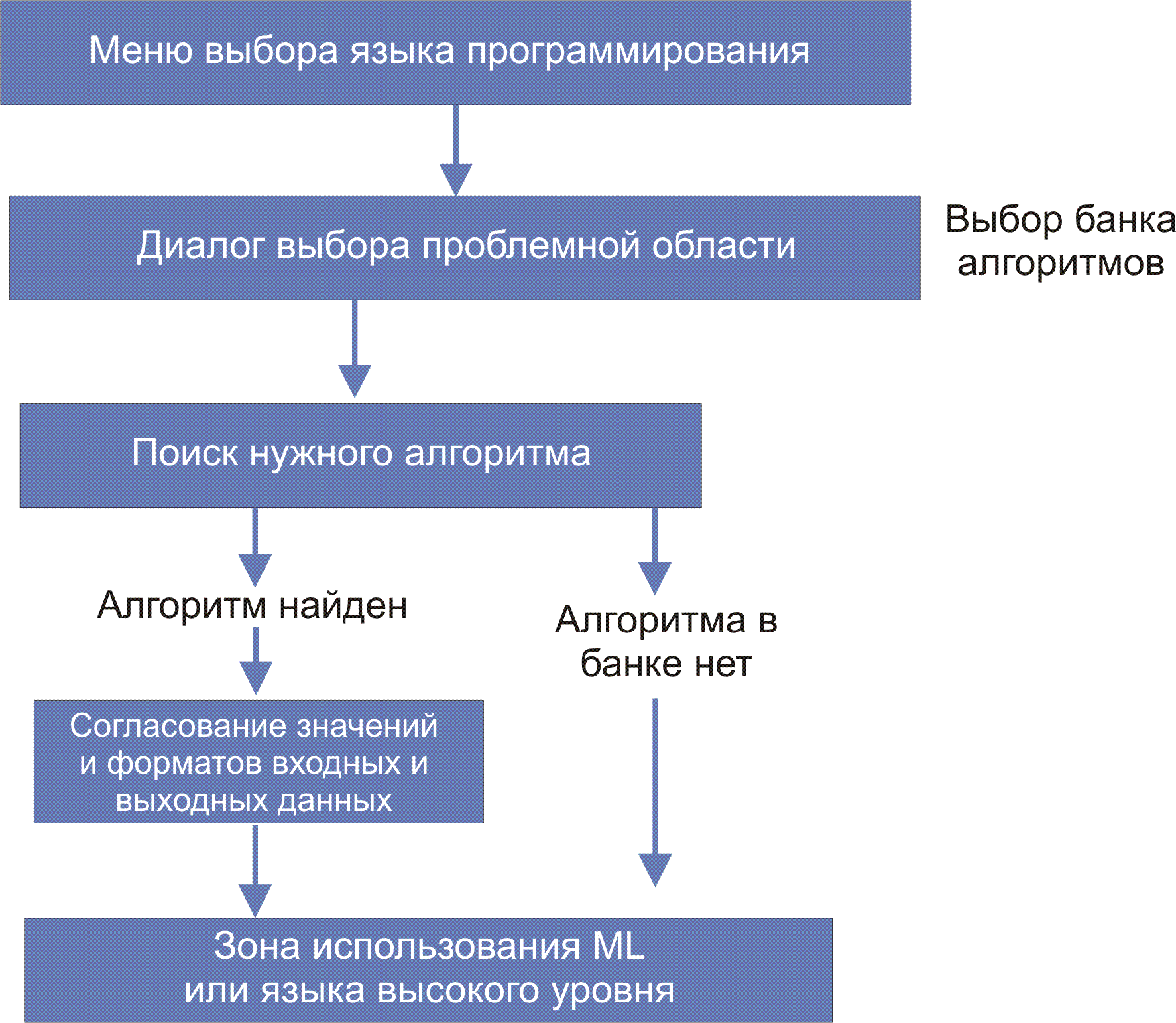
Рис. 7. Диалог выбора (select.cdr)
Описания этих проблем надо попытаться перевести на язык PDL, сформировав минимальное число универсальных операторов и правил.
Составление описание и интуитивная трансляция текста программы в код позволит доработать синтаксис PDL.
Этот программный модуль должен быть помещен в банк описаний алгоритмов. Нужен скрипт для автоматической конфигурации MRTG.
Следует определить имена и форматы нескольких конфигурационных файлов. Вероятно, нужно сформировать дерево семантических связей для нужной тематики, которое будет использоваться при написании программы диалога.
Для поиска в банке описания алгоритмов надо использовать совокупность имени операции, ее атрибутов и атрибутов-определений. Это исключит проблемы поиска по ключевым словам. Этот метод будет использоваться транслятором PDL. Описание программного модуля, хранящегося в банке на языке PDL, может стать универсальной сигнатурой при поиске. Эта сигнатура должна быть записана в одном из полей описания модуля в банке BD.
Надо для каждого из слов представить все модификации слов по падежам и числу, то же касается глаголов, описывающих операцию.
Для глаголов, определяющих тип операции, составляются списки атрибутов действий (наречий: быстро, корректно, приближенно, явно/неявно, последовательно/параллельно, надежно...). Каждый из таких атрибутов должен быть описан, что придаст ему конкретность (например, диапазон вариации рабочих характеристик).
Для глаголов нужно также учитывать их вариацию при спряжении.
Важно определить процедуру описания новых имен таких объектов.
Все слова тезауруса делятся на группы, для которых эти слова изменяются одинаково по падежам, числам или при спряжении. В тезаурусе хранится корень слова и номер набора правил, согласно которым слово видоизменяется. Например, слова стол, стул, нож, предмет относятся к одной группе. Образцы слов, которые нужно искать в тексте при анализе, формируются из словаря тезауруса автоматически на основе кодов этих правил.
Надо разработать структуру базы данных для тезауруса. Начнем с создания тезауруса для направления ИТ.
В тезаурусе формируются секции существительных, глаголов, прилагательных и наречий. Существительные характеризуются именительным падежом единственного числа, а глаголы - инфинитивом. Предпочтение нужно отдать английскому языку, где слова менее подвержены изменениям.
Для существительных и глаголов проставляется код группы вариаций, который определяет то, как образуются падежные (или варианты спряжения) модификации слова. Для всех слов записывается корень слова.
Для каждого из слов в тезаурусе приводятся слова (существительные, глаголы, прилагательные, наречия и т.д.), с которыми данное слово может быть связано. Для каждого слова из перечня приводятся значения метрик, которые характеризуют степень связи. Слово из перечня может присутствовать и в основном списке тезауруса. Метрики связей для таких случаев могут не совпадать М(A->B) может не равняться М(B->А).
В банке данных тезауруса должно быть текстовое поле, характеризующее смысл данного слова (например, ....). В случае, когда слово может иметь несколько различных контекстных значений, должно быть описание для каждого из контекстных значений. Для каждого из контекстов должен быть сформирован комплект значений метрик.
Семантический анализ предполагает формирование смысловых связей в простейшем варианте по схеме субъект - действие - объект
.Банк описаний алгоритмов должен регулярно, не реже раза в месяц копироваться на компьютер, размещенный в другом помещении, желательно в другом здании. Можно предусмотреть секционирование банка по темам или датам создания, это ускорит работу системы, когда размер индекса превысит гигабайт.
Помимо рекордов, указанных в том разделе там, возможно следует поместить Q-метка поиска (для каждого рекорда своя).
Текстовое поле описания программного модуля. Там же хранится описание требований к входным данным, а также структура и форматы выходных данных. Там же прописываются требования к оперативной и виртуальной памяти, а также скорость исполнения задания, URL-депозитария, где хранятся примеры использования программного модуля с детальными комментариями. Там же может храниться описание инсталляции модуля, а если требуется и инсталляции необходимых библиотек.
Структура банка алгоритмов представлена на рис. 10.
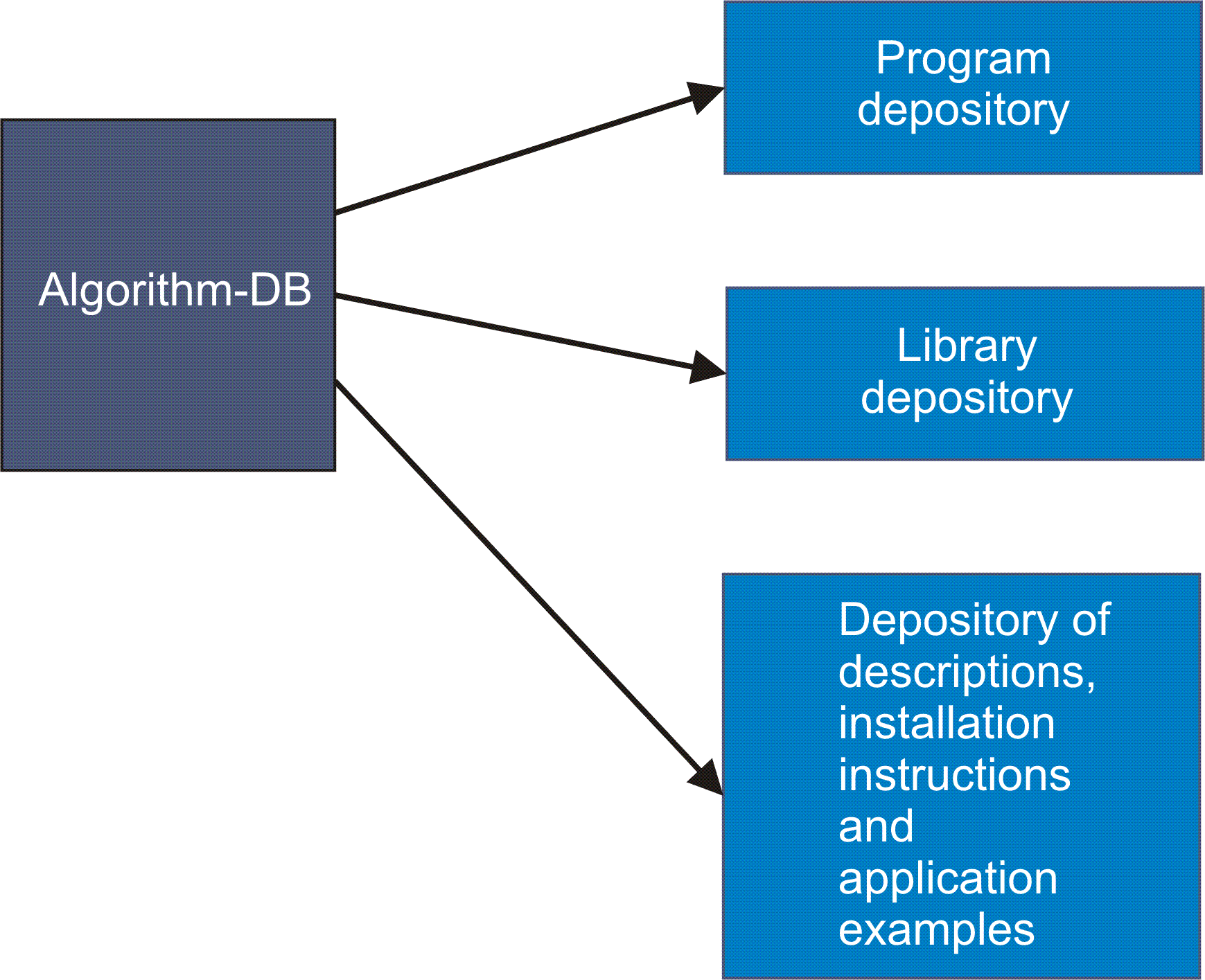
Рис. 10. Структура банка алгоритмов (bank.cdr)
Современные системы поиска работают с ключевыми словами, которые могут объединяться только бинарными операторами. Системы компьютерного обучения также оперируют только фактами или конкретными данными и не могут осуществлять обобщения. Детей в начальной школе учат также, но к концу средней школы и в университетах людей учат выявлять закономерности из совокупности фактов. Именно выявлением закономерностей в многообразии фактов и занимается наука.
Нужно выработать язык описания структуры рекордов для журнальных файлов и создать депозитарий таких описаний. Эти описания предназначены для программ, а не для людей:
Apache: access_log, error.log
IDS: SNORT: alert_1, alert_2, alert_3,…,alert_24
IPS: NIPS, WIPS, HIPS
secure: Jun 16 03:29:43 saturn sshd[13930]: refused connect from 89.189.185.29 (89.189.185.29)
mail и пр.
и таблиц баз данных. Создать модули, которые будут анализировать эти рекорды в соответствии с выработанными требованиями (извлекать нужные данные, строить распределения и преобразовывать их в графическую форму.). Так как современные графические файлы следуют стандартам MPEG-4 и -7, здесь важную роль будут играть альфа-маски, определяющие принадлежность пикселей к тому или иному объекту на кадре.
Описания можно создать для рисунков, используя их объектную структуру (MPEG-4, MPEG-7, alfa-masks), что позволит программно манипулировать этими объектами.
Разрабатывается стандарт для описания таблиц банков данных, а также для описания форматов любых рекордов. Разработка языка описания различных объектов, позволит сделать важный шаг на пути создания искусственного интеллекта не нейронного типа.
Планируется также создание банка стандартных описаний, которые будут использоваться при создании описаний более сложных проблем.
Аналогично описания создаются для оборудования (SNMP/MIB/NMS/ ASN.1) и различных электронных устройств. Это позволит создавать эффективные описания заданий для управления оборудованием. Нужно сформулировать стандарт для таких описаний и создать секционированный депозитарий или банк этих описаний с разбивкой по проблематике. Среди таких описаний могут быть и описания уязвимостей и сетевых атак.
Создается библиотека примитивов для работы с полями журнальных файлов на основе стандартизованных описаний. Такие примитивы могут использоваться также при разработке систем, ориентированных на естественный язык описания проблем.
Создаются библиотеки описаний элементарных процедур, например, задач построения распределений по определенным параметрам, где задается проход к входному файлу (если нужно), имя массива, диапазон вариации параметров и гранулярность. Такие описания представляют собой библиотечные описания.
Описание структуры рекордов журнальных файлов, таблиц баз данных и пр. позволит адаптировать программу обработки с учетом этих данных.
| sub ip_to_num | # IP to number conversion |
| sub num_to_ip | # number to IP conversion |
| sub tm_to_td | # time-mark to time-date conversion |
| sub dt_to_tm | # time-date to time-mark conversion |
| sub lined | # line conversion for file # Input = line from the file access_log # Output contains 5 elements: IP TM method length pass_traversal_flag (0= no; # 1= pass_trav) |
| sub ip_ill | # Illegal HTTP-methods detection; # input: $line -> current record; %ipb; # call: ip_ill($line); # @forbid=('PUT','TRACE','DELETE','OPTIONS','PROPFIND'); |
| sub L_record | # IP-distribution for requests longer than 250 symbols # call: L_record($line); # buffer overflow attack |
| sub rec_len | # Request length distribution calculation; # call: rec_len($length); хэш -> %len |
| sub avr_rms | # rec_leng.txt -> lengths.txt,req_num.txt |
| sub rec_dens | # 3 requests per sec. High request density, distribution for ip # call: rec_dens($line); хэш-> %ipd |
| sub slash | # PASS TRAVERSAL attack IP-distribution (Slash attack) # call: slash($line); |
| sub ill_tex | # illegal HTTP-methods detection # input: $line -> current record; @ill; output: file illegal.txt # writing request lines with ill-methods into file # call: ill_tex($line,$lin,*FH); где FH – file-handle, $line – строка # журнального файла, $lin та же строка, но в формате: # ip tm method length fl (fl=1, if pass-traversal attack) |
| sub graph | # Making up a picture from the file # input=/ids/lengths.txt; rec_len.txt; long_req.txt |
| sub delta | # Opens files /ids/delta.txt и .ids/delta1.txt and writes $tm - $t_bins # and $i - $t_bins ($i – номер бина) |
| sub shutdown | # выключение компьютера |
| sub read_file | # read file access_log.filt, use primitives ill_tex,slash, L_record and # ip_ill |
| sub write_out | # write data into files atk_ip.txt, cgi.txt, atk_dens.txt, rec_leng.txt, # long_req.txt |
| sub array_develop | # |
| sub error_log_compress | # |
| sub dt_to_tm_er | #date-time to time-mark conversion for error_log |
| sub read_error_log | # read & analise file error_log |
Эта библиотека примитивов ориентирована на обеспечение безопасности WEB-серверов, хотя некоторые их них носят достаточно общий характер. Для решения других задач могут быть сформированы другие библиотеки примитивов.
Имена примитивов надо отличать от программных модулей, записанных в банках. Их имена должны начинаться с P_, P_ip_to_num. Должны существовать библиотеки примитивов, снабженные исчерпывающими описаниями. Мощность множества примитивов будет на порядки меньше мощности множества программных модулей, хранящихся в банке. В случае использования примитива из PERL префикс P_ не нужен. В библиотеке примитивов они имеют имена без этого префикса. Префикс нужен только для того, чтобы транслятор распознавал имена примитивов.
Некоторые примитивы, из приведенного выше списка, могут быть удалены (слишком ограниченная область применения). Примитивы, выделенные красным цветом, после некоторой переделки останутся. Надо убрать из примитивов привязку к текущей задаче и сделать их адаптирующимися к широкому классу заданий. Например, write_out может иметь вид write list of hashes into list of files.
Библиотека примитивов размещается в каталоге /usr/lib64/perl5/primitives.pm (scientific linux). Могут использоваться разные библиотеки примитивов для разных областей применения. Имена таких библиотек будут иметь префикс prim_.
Примитивы могут использоваться и в обычных программах Perl, для этого в начале программы должен быть помещен оператор use primitives;.
Макрос – последовательность команд Perl, снабженная именем. В языке PDL уже описаны подобные структуры -
command list . Это позволяет включить в будущую программы последовательность команд Perl. Если где-то еще потребуется аналогичная последовательность команд, надо будет ввести туда такой список снова. Макросы позволяют сэкономить усилия, в последующих случаях будет достаточно вписать туда только имя макроса. Макрос имеет формат:
name=”&m_macro-name” список команд
Макросы могут образовывать библиотеки, снабженные именами.
Важную роль при формировании ИИ нового (не нейронного) типа сыграют библиотеки примитивов. При этом нужно будет сформировать семантические сети для связей слов описания и действий (примитивов) с ними сопряженных. Например, семантическая цепочка: Операция (что нужно сделать) -> объект (над чем нужно выполнить операцию) -> атрибут (как нужно что-то сделать, напр. с какой частотой, точностью), далее могут следовать параметры или характеристики. Одной операции может соответствовать несколько объектов, а каждому объекту несколько атрибутов. В этом случае семантическая цепочка превращается в семантическую сеть. Имена объектов, атрибутов, параметров и характеристик могут встречаться в семантических цепях разных операций, при этом они могут иметь, вообще говоря, разный смысл. Ребра семантических сетей могут быть снабжены метриками, что позволит в перспективе оптимизировать созданные программы. Семантическая цепочка может использоваться для поиска нужного программного модуля в банке описаний вместо ключевых слов.
Нужно при этом помнить, что полностью отказаться от нейронных подходов, во всяком случае, на первом этапе, не удастся, так как система должна быть самообучаемой. Можно будет создать сеть узлов принятия решений (там будут элементы PDL), сопряженную с системой исполнения решений.
Такая система будет обладать большим быстродействием.
Оперирование фразами-описаниями позволит построить более эффективные системы поиска и сделать небольшой шаг на пути создания искусственного интеллекта нового типа.
Объемы информации растут экспоненциально, для обработки этих данных нужны эффективные программы. На очередь встает задача автоматической генерации программ и разработки средств повышения производительности программирования. Объектом описания может быть документ, оборудование, сотрудник и т.д. В перспективе, банки таких описаний позволят автоматически формировать специализированные ОС. Такие описания могут использоваться также для автоматического распознавания объектов.
Описания должны использоваться программами для автоматизации управления процессами и системами, диагностики, обработки данных, в том числе в случае big data. Это позволит поднять эффективность обработки и сократит число программных ошибок. Эти описания создаются не столько для людей, сколько для программ управления. Должен быть создан специализированный банк описаний различных объектов и встроенная система поиска.
Среди примитивов для работы с описаниями будут программы записи и чтения для банков данных, для SNMP, включая конфигурацию, задание и смену значения community и реагирования на TRAP, перевода текстовых файлов из одной кодировки в другую, модулей для машинного обучения и т.д. Эта коллекция примитивов не позволит решать любые проблемы, но может, например, упростить сетевой мониторинг по совокупности протоколов, решить проблему безопасности WEB-серверов и т.д.
Для рекордов журнальных файлов (пункт 2) задается число полей записи, тип каждого поля (число-символ), длина/ширина поля и т.д.. При этом создается словарь-тезаурус слов описаний. Целесообразно сформировать специальный язык описания (расширение PDL). Нужно будет разработать набор примитивов для работы с такими описаниями
Previous: 4.7.20 Гиперконвергентная инфраструктура (HCI)
UP:
4.7 Прикладные сети Интернет |




