


 |
|
Previous: 6.17 Алгоритм вычисления дайджеста сообщения MD5 (RFC-1321, R. Rivest, апрель 1992)
UP:
6 Сетевая безопасность |
|
|
|
Previous: 6.17 Алгоритм вычисления дайджеста сообщения MD5 (RFC-1321, R. Rivest, апрель 1992)
UP:
6 Сетевая безопасность |
Алгоритм SHA-1 (Secure Hash Algorithm) предназначен для вычисления дайджеста документа, файла или сообщения. Когда входное сообщение имеет произвольную длину < 264 бит, программа SHA-1 выдает 160-битовый код, называемый дайджестом сообщения. Дайджест сообщения может стать, например, исходной информацией для для алгоритма электронной подписи, которая формируется для верификации сообщения. Подпись сообщения улучшает эффективность процесса, так как дайджест обычно имеет размер много меньше размера сообщения. Тот же самый алгоритм используется при верификации цифровой подписи. Любая модификация сообщения при транспортировке с крайне высокой вероятностью приведет к тому, что дайджест изменится и подпись не будет верифицирована.
Позднее были разработаны более эффективные версии SHA-2 (2001, 256-512 бит) и SHA-3 (Йоан Даймен, 2013, 256-512 бит).
| Алгоритм | Размер сообщения в битах | Размер блока в битах | Размер слова в битах | Размер дайджеста сообщения в битах |
|---|---|---|---|---|
| SHA-1 | < 264 | 512 | 32 | 160 |
| SHA-224 | < 264 | 512 | 32 | 224 |
| SHA-256 | < 264 | 512 | 32 | 256 |
| SHA-384 | < 2128 | 1024 | 64 | 384 |
| SHA-512 | < 2128 | 1024 | 64 | 512 |
| SHA-512/224 | < 2128 | 1024 | 64 | 224 |
| SHA-512/256 | < 2128 | 1024 | 64 | 256 |
Алгоритм SHA-1 называется безопасным, так как на его основе невозможно вычислить сообщение, которому соответствует дайджест, или найти другое сообщение, которое может соответствовать полученному дайджесту. Любое изменение сообщения при передаче приведет с большой вероятностью к существенному изменению дайджеста, что исключит успешную сверку цифровой подписи.
В разделе 2 определены терминология и функции, использованные при построении формы SHA-1.
В описании используются обозначения для битовых последователей и целых чисел:
Если z является целым, 0 <= z < 264, тогда z = (232)x + y где 0 <= x < 232 и 0 <= y < 232. Так как x и y могут быть представлены как слова X и Y, соответственно, z может быть представлен парой слов (X,Y).
Со словами будут производиться следующие операции:
X AND Y = побитовая логическая "and" X и Y.
X OR Y = побитовая логическая "inclusive-or" X и Y.
X XOR Y = побитовая логическая "exclusive-or" X и Y.
NOT X = побитовая логическая "complement" X.
Пример:
01101100101110011101001001111011
XOR 01100101110000010110100110110111
--------------------------------
= 00001001011110001011101111001100
Вычислим z = (x + y) mod 232.
Затем 0 <= z < 232. Преобразуем z в слово, Z, и определяем Z = X + Y.
Sn(X) = (X << n) OR (X >> 32-n).
В выше приведенном примере X << n был получен следующим образом: удаляются левые n бит X и затем результат дополняется n нулями справа (результат будет иметь 32 бита). X >> n получается удалением правых n бит X и затем дополнением результата нулями слева. Таким образом Sn(X) циклическому сдвигу X на n позиций влево.
SHA-1 используется для вычисления дайджеста сообщения или информационного файла, который поступает на вход. Сообщение или информационный файл должны рассматриваться как битовая строка. Длина сообщения является числом бит в сообщении (пустое сообщение имеет длину 0). Если число бит в сообщении кратно 8, ради компактности будем представлять сообщение в hex-формате. Целью дополнения сообщения является желание сделать полную длину сообщения кратной 512. В процессе расчета дайджеста сообщения SHA-1 последовательно обрабатывает блоки последовательность 512 бит. Далее специфицируется, как осуществляется дополнение исходного сообщения. Добавляется 1, за которой следует m "0" и 64-битное целое, чтобы получить сообщение с длиной, кратной 512. 64-битное целое характеризует длину исходного сообщения. Дополненное сообщение затем обрабатывается SHA-1 как n 512-битных блоков.
Предположим, что сообщение имеет длину l < 264. Прежде чем оно будет подано на вход SHA-1, сообщение дополняется справа следующим образом:
Пример: Предположим, что оригинальное сообщение является строкой бит
01100001 01100010 01100011 01100100 01100101.
После шага (a) это дает
01100001 01100010 01100011 01100100 01100101 1.
Так как l = 40, число бит в строке вше равно 41 и добавляется 407 "0", доводя длину сообщения до 448. Это дает в шестнацатеричном представлении
61626364 65800000 00000000 00000000
00000000 00000000 00000000 00000000
00000000 00000000 00000000 00000000
00000000 00000000.
Пример: Предположим, что мы имеем исходное сообщение (b). Тогда l = 40 (заметим, что l вычисляется до выполнения дополнений). Представление двух слов 40 в hex-формате 00000000 00000028. Следовательно дополненное сообщение в окончательном hex-формате будет иметь вид
61626364 65800000 00000000 00000000
00000000 00000000 00000000 00000000
00000000 00000000 00000000 00000000
00000000 00000000 00000000 00000028.
Дополненное сообщение будет содержать 16 * n слов для некоторого n > 0. Дополненное сообщение рассматривается как последовательность из n блоков M(1), M(2), первые символы (или биты) сообщения.
В SHA-1 используется последовательность логических функций f(0), f(1),..., f(79). Каждая f(t), 0 <= t <= 79, выполняет операции над тремя 32-битовыми словами B, C, D и выдает на выходе 32-битовое слово. f(t;B,C,D) определяется следующим образом: для слов B, C, D,
f(t;B,C,D) = (B AND C) OR ((NOT B) AND D) ( 0 <= t <= 19)
f(t;B,C,D) = B XOR C XOR D (20 <= t <= 39)
f(t;B,C,D) = (B AND C) OR (B AND D) OR (C AND D) (40 <= t <= 59)
f(t;B,C,D) = B XOR C XOR D (60 <= t <= 79).
В SHA-1 используется последовательность слов K(0), K(1), ... , K(79). В hex-формате получается
K(t) = 5A827999 ( 0 <= t <= 19)
K(t) = 6ED9EBA1 (20 <= t <= 39)
K(t) = 8F1BBCDC (40 <= t <= 59)
K(t) = CA62C1D6 (60 <= t <= 79).
На рис. 1 представлена схема реализации алгоритма SHA1. Символ "+" на рисунке указывает на операцию сложения по модулю 232, F - нелинейная функция, <<<n - обозначает сдвиг кода влево на n разрядов, Wt и Kt - константы, а A,B,C,D,E - 32-битовые слова.
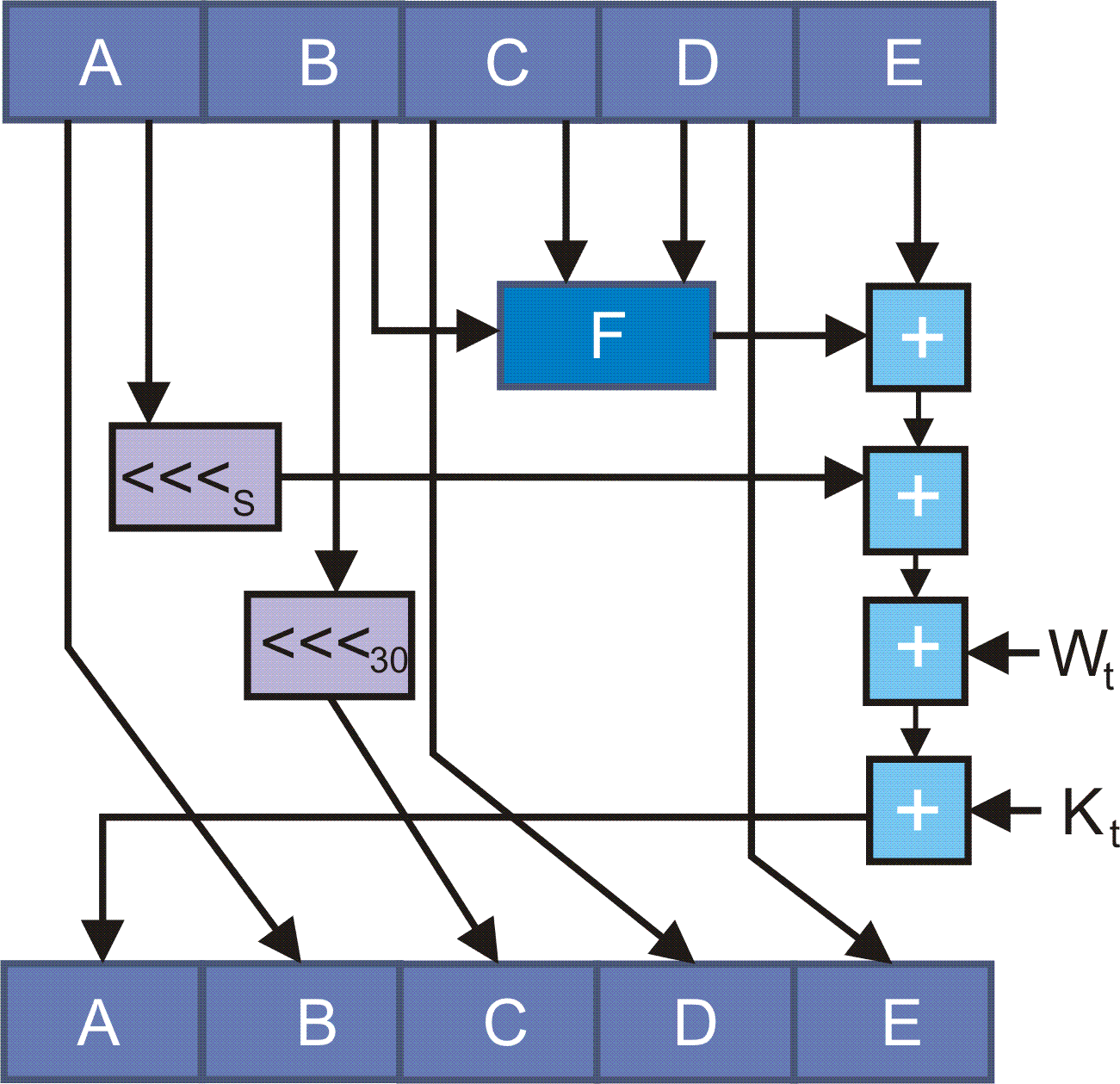
Рис. 1. Алгоритм вычисления дайджеста SCH1 [5]
Методы, представленные в разделах 6.1 и 6.2, выдают идентичные дайджесты сообщения. Хотя, использование метод 2 позволяет сэкономить 64 32-битовых слов в памяти, он вероятно удлинит время исполнения из-за усложнения вычисления адресов для { Wа[t] } на шаге (c). Существуют другие методы вычисления, которые дают идентичные результаты.
Дайджест сообщения вычисляется с использованием дополненного сообщения, как это описано в разделе 4. Вычисление описано для случая двух буферов, каждый из которых содержит пять 32-битных слов, и последовательность из восьмидесяти 32-битовых слов. Слова первого 5-словного буфера помечены как A,B,C,D,E. Слова второго 5-словного буфера помечены как H0, H1, H2, H3, H4. Слова массива из 80 слов помечены, как W(0), W(1),..., W(79). Используется также буфер для одного слова TEMP.
Чтобы сгенерировать дайджест сообщения, блоки из 16-слов M(1), M(2),..., M(n), определенные в разделе 4, обрабатываются последовательно. Обработка каждого M(i) включает в себя 80 шагов.
Прежде чем обрабатывать какой-либо блок, все H инициализируются следующим образом: в hex-представлении:
H0 = 67452301 H1 = EFCDAB89 H2 = 98BADCFE H3 = 10325476 H4 = C3D2E1F0.
Теперь обрабатываются M(1), M(2), ... , M(n). Чтобы обработать M(i), мы выполняем следующее:
W(t) = S^1(W(t-3) XOR W(t-8) XOR W(t-14) XOR W(t-16)).
TEMP = S^5(A) + f(t;B,C,D) + E + W(t) + K(t);
E = D; D = C; C = S30(B); B = A; A = TEMP;
После обработки M(n), дайджест сообщения является 160-битовой строкой, в виде 5 слов:
H0 H1 H2 H3 H4.
Предыдущий метод предполагает, что последовательность W(0), ... , W(79) представляет собой массив из 80 32-битных слов. Это эффективно с точки зрения минимизации времени вычисления, так как адреса W(t-3), ... ,W(t-16) на этапе (b) легче вычислять. Когда имеется дефицит памяти, можно для { W(t) } организовать кольцевой буфер, который может использовать массив из 16 32-битных слов W[0], ... W[15]. В этом случае в hex-формате получим: MASK = 0000000F. Затем обрабатываем M(i) следующим образом:
s = t AND MASK;
если (t >= 16) W[s] = S^1(W[(s + 13) AND MASK] XOR W[(s + 8) AND
MASK] XOR W[(s + 2) AND MASK] XOR W[s]);
TEMP = S^5(A) + f(t;B,C,D) + E + W[s] + K(t);
E = D; D = C; C = S^30(B); B = A; A = TEMP;
Ниже представлена реализация SHA-1 на C. Раздел 7.1 содержит файл заголовков, 7.2 - код C, и 7.3 - тестовый драйвер.
/* * sha1.h * * Описание: * Это файл заголовков для программы, которая реализует SHA1, как он определен в FIPS PUB 180-, опубликованном 17 апреля 1995. * * Многие имена переменных в этой программе, особенно односимвольные имена, * взяты из более ранних публикаций. * * Please read the file sha1.c for more information. * */ #ifndef _SHA1_H_ #define _SHA1_H_ #include/* * Если у вас нет стандартного ISO файла заголовков stdint.h, тогда вы должны * typdef следующее: * имя значение * uint32_t unsigned 32 bit целое * uint8_t unsigned 8 bit целое (т.e., unsigned char) * int_least16_t целое of >= 16 bits * */ #ifndef _SHA_enum_ #define _SHA_enum_ enum { shaSuccess = 0, shaNull, /* Null pointer parameter */ shaInputTooLong, /* входные данные слишком длины */ shaStateError /* called Input after Result */ }; #endif #define SHA1HashSize 20 * Эта структура будет содержать контекстную информацию для хэш-операций SHA-1 */ typedef struct SHA1Context { uint32_t Intermediate_Hash[SHA1HashSize/4]; /* Дайджест сообщения */ uint32_t Length_Low; /* Длина сообщения в битах */ uint32_t Length_High; /* Длина сообщения в битах */ /* Индекс массива блока сообщения */ int_least16_t Message_Block_Index; uint8_t Message_Block[64]; /* 512-битовые блоки сообщения */ int Computed; /* дайджест вычислен? */ int Corrupted; /* Дайджест сообщения поврежден? */ } SHA1Context; /* * Прототипы функций */ int SHA1Reset( SHA1Context *); int SHA1Input( SHA1Context *, const uint8_t *, unsigned int); int SHA1Result( SHA1Context *, uint8_t Message_Digest[SHA1HashSize]); #endif
/*
* sha1.c
*
* Описание:
* этот файл реализует алгоритм SHA1, как это определено в
* FIPS PUB 180-1 April 17, 1995.
*
* Алгоритм SHA-1, формирует 160-битовый дайджест сообщения для заданного информационного потока.
* Чтобы найти сообщение с тем же дайджестом, должно потребоваться около 2n шагов
* и
* 2(n/2), чтобы найти два сообщения с одним и тем же дайджестом,
* где n размер дайджеста в бит. Следовательно, этот алгоритм может использоваться в качестве идентификатора сообщения.
*
* Соображения о переносимости:
* SHA-1 определен в терминах 32-битных "слов". этот код использует
* (включенный через "sha1.h" чтобы определить 32 и 8 битовые операции с целыми без знака
* Если ваш C-компилятор не поддерживает операции с 32-битовыми целыми без знака, этот код не применим.
*
* Предостережения:
* SHA-1 спроектирован для работы с длиной сообщений меньше чем 264 бит. Хотя SHA-1 позволяет генерировать дайджесты сообщений
* для сообщений с любым числом бит меньше чем 264, эта реализация
* работает с сообщениями, длина которых кратна 8-битным символам.
*
*/
* /
#include "sha1.h"
#include "sha1.h"
/* Определяем макро циклического сдвига SHA1 */
#define SHA1CircularShift(bits,word) \
(((word) << (bits)) | ((word) >> (32-(bits))))
/* Local Function Prototyptes */
void SHA1PadMessage(SHA1Context *);
void SHA1ProcessMessageBlock(SHA1Context *);
/*
* SHA1Reset
*
* Описание:
* Эта функция будет инициализировать SHA1Context при подготовке к
* вычислению нового дайджеста сообщения SHA1.
*
* Параметры:
* context: [in/out]
* Сброс контекста.
*
* Возвращает:
* sha Error Code.
*
*/
int SHA1Reset(SHA1Context *context)
{
if (!context)
{
return shaNull;
}
context->Length_Low = 0;
context->Length_High = 0;
context->Message_Block_Index = 0;
context->Intermediate_Hash[0] = 0x67452301;
context->Intermediate_Hash[1] = 0xEFCDAB89;
context->Intermediate_Hash[2] = 0x98BADCFE;
context->Intermediate_Hash[3] = 0x10325476;
context->Intermediate_Hash[4] = 0xC3D2E1F0;
context->Computed = 0;
context->Corrupted = 0;
return shaSuccess;
}
/*
* SHA1Result
*
* Описание:
* Эта функция занесет 160-битовый дайджест сообщения в массив
* Message_Digest, заданный при запросе.
* Заметим: Первый октет хэша записывается в 0-ой элемент,
* последний октет хэша заносится в 19-ый элемент.
*
* Параметры:
* context: [in/out]
* Контекст, который используется при вычислении хэша SHA-1.
* Message_Digest: [out]
* Куда заносится вычисленный дайджест.
*
* Возвращает:
* sha Error Code.
*
*/
int SHA1Result( SHA1Context *context,
uint8_t Message_Digest[SHA1HashSize])
{
int i;
если (!context || !Message_Digest)
{
return shaNull;
}
if (context->Corrupted)
{
return context->Corrupted;
}
if (!context->Computed)
{
SHA1PadMessage(context);
for(i=0; i<64; ++i)
{
/* message may be sensitive, clear it out */
context->Message_Block[i] = 0;
}
context->Length_Low = 0; /* и clear length */
context->Length_High = 0;
context->Computed = 1;
}
for(i = 0; i < SHA1HashSize; ++i)
{
Message_Digest[i] = context->Intermediate_Hash[i>>2]
>> 8 * ( 3 - ( i & 0x03 ) );
}
return shaSuccess;
}
/* * SHA1Input * * Описание: * Эта функция воспринимает массив октетов в качестве следующей части сообщения. * * Параметры: * context: [in/out] * Контекст SHA чтобы обновить массив сообщения * message_array: [in] * Массив символов представляющих следующую часть сообщения. * length: [in] * Длина сообщения в message_array * * Возвращает: * sha Error Code. * */
int SHA1Input( SHA1Context *context,
const uint8_t *message_array,
unsigned length)
{
if (!length)
{
return shaSuccess;
}
if (!context || !message_array)
{
return shaNull;
}
if (context->Computed)
{
context->Corrupted = shaStateError;
return shaStateError;
}
if (context->Corrupted)
{
return context->Corrupted;
}
while(length-- && !context->Corrupted)
{
context->Message_Block[context->Message_Block_Index++] =
(*message_array & 0xFF);
context->Length_Low += 8;
if (context->Length_Low == 0)
{
context->Length_High++;
if (context->Length_High == 0)
{
/* Message is too long */
context->Corrupted = 1;
}
}
if (context->Message_Block_Index == 64)
{
SHA1ProcessMessageBlock(context);
}
message_array++;
}
return shaSuccess;
}
/*
* SHA1ProcessMessageBlock
*
* Описание:
* Эта функция будет обрабатывать следующие 512 бит сообщения, записанные в массиве Message_Block.
*
*
*
*/
void SHA1ProcessMessageBlock(SHA1Context *context)
{
const uint32_t K[] = { /* Константы заданные в SHA-1 */
0x5A827999,
0x6ED9EBA1,
0x8F1BBCDC,
0xCA62C1D6
};
int t; /* Счетчик циклов */
uint32_t temp; /* Temporary word value */
uint32_t W[80]; /* Последовательность слов */
uint32_t A, B, C, D, E; /* Буферы слов */
/*
* Инициализируем первые 16 слов в массиве W
*/
for(t = 0; t < 16; t++)
{
W[t] = context->Message_Block[t * 4] << 24;
W[t] |= context->Message_Block[t * 4 + 1] << 16;
W[t] |= context->Message_Block[t * 4 + 2] << 8;
W[t] |= context->Message_Block[t * 4 + 3];
}
for(t = 16; t < 80; t++)
{
W[t] = SHA1CircularShift(1,W[t-3] ^ W[t-8] ^ W[t-14] ^ W[t-16]);
}
A = context->Intermediate_Hash[0];
B = context->Intermediate_Hash[1];
C = context->Intermediate_Hash[2];
D = context->Intermediate_Hash[3];
E = context->Intermediate_Hash[4];
for(t = 0; t < 20; t++)
{
temp = SHA1CircularShift(5,A) +
((B & C) | ((~B) & D)) + E + W[t] + K[0];
E = D;
D = C;
C = SHA1CircularShift(30,B);
B = A;
A = temp;
}
for(t = 20; t < 40; t++)
{
temp = SHA1CircularShift(5,A) + (B ^ C ^ D) + E + W[t] + K[1];
E = D;
D = C;
C = SHA1CircularShift(30,B);
B = A;
A = temp;
}
for(t = 40; t < 60; t++)
{
temp = SHA1CircularShift(5,A) +
((B & C) | (B & D) | (C & D)) + E + W[t] + K[2];
E = D;
D = C;
C = SHA1CircularShift(30,B);
B = A;
A = temp;
}
for(t = 60; t < 80; t++)
{
temp = SHA1CircularShift(5,A) + (B ^ C ^ D) + E + W[t] + K[3];
E = D;
D = C;
C = SHA1CircularShift(30,B);
B = A;
A = temp;
}
context->Intermediate_Hash[0] += A;
context->Intermediate_Hash[1] += B;
context->Intermediate_Hash[2] += C;
context->Intermediate_Hash[3] += D;
context->Intermediate_Hash[4] += E;
context->Message_Block_Index = 0;
}
/*
* SHA1PadMessage
*
* Описание:
* В соответствии со стандартом, сообщение должно быть дополнено до позиции, кратной
* 512 бит. Первый бит заполнителя должен быть равен '1'. Последние 64 бита
* характеризуют длину исходного сообщения. Все промежуточные биты должны быть нулевыми. эта функция дополнит сообщение
* согласно правилам заполнения массива Message_Block.
* Она вызовет также функцию ProcessMessageBlock.
* Когда возвращается код, предполагается, что дайджест был вычислен.
*
* Параметры:
* context: [in/out]
* The context to pad
* ProcessMessageBlock: [in]
* The appropriate SHA*ProcessMessageBlock function
*
*/
void SHA1PadMessage(SHA1Context *context)
{
/* Проверяем, не является ли данный блок сообщения слишком мал, чтобы хранить
* биты заполнителя и длины. Если это так, мы дополним блок, обработаем его
* и затем продолжим дополнение во второй блок. */
if (context->Message_Block_Index > 55)
{
context->Message_Block[context->Message_Block_Index++] = 0x80;
while(context->Message_Block_Index < 64)
{
context->Message_Block[context->Message_Block_Index++] = 0;
}
SHA1ProcessMessageBlock(context);
while(context->Message_Block_Index < 56)
{
context->Message_Block[context->Message_Block_Index++] = 0;
}
}
else
{
context->Message_Block[context->Message_Block_Index++] = 0x80;
while(context->Message_Block_Index < 56)
{
context->Message_Block[context->Message_Block_Index++] = 0;
}
}
/* Запоминаем длину сообщения в виде последних 8 октетов */
context->Message_Block[56] = context->Length_High >> 24;
context->Message_Block[57] = context->Length_High >> 16;
context->Message_Block[58] = context->Length_High >> 8;
context->Message_Block[59] = context->Length_High;
context->Message_Block[60] = context->Length_Low >> 24;
context->Message_Block[61] = context->Length_Low >> 16;
context->Message_Block[62] = context->Length_Low >> 8;
context->Message_Block[63] = context->Length_Low;
SHA1ProcessMessageBlock(context);
}
Ниже приведен код основной программы тестового драйвера для проверки кода sha1.c.
/* * sha1test.c * * Описание: * Этот файл служит для проверки кода SHA-1, выполняющего три теста, описанных в FIPS PUB 180-1 плюс один, который называется * SHA1Input и имеет длину является кратную 512 бит, плюс проверки нескольких ошибок. * */ #include#include #include #include "sha1.h" /* Определяем образцы для тестирования */ #define TEST1 "abc" #define TEST2a "abcdbcdecdefdefgefghfghighijhi" #define TEST2b "jkijkljklmklmnlmnomnopnopq" #define TEST2 TEST2a TEST2b #define TEST3 "a" #define TEST4a "01234567012345670123456701234567" #define TEST4b "01234567012345670123456701234567" /* an exact multiple of 512 bits */ #define TEST4 TEST4a TEST4b char *testarray[4] = { TEST1, TEST2, TEST3, TEST4 }; long int repeatcount[4] = { 1, 1, 1000000, 10 }; char *resultarray[4] = { "A9 99 3E 36 47 06 81 6A BA 3E 25 71 78 50 C2 6C 9C D0 D8 9D", "84 98 3E 44 1C 3B D2 6E BA AE 4A A1 F9 51 29 E5 E5 46 70 F1", "34 AA 97 3C D4 C4 DA A4 F6 1E EB 2B DB AD 27 31 65 34 01 6F", "DE A3 56 A2 CD DD 90 C7 A7 EC ED C5 EB B5 63 93 4F 46 04 52" }; int main() { SHA1Context sha; int i, j, err; uint8_t Message_Digest[20]; /* * Perform SHA-1 tests */ for(j = 0; j < 4; ++j) { printf( "\nTest %d: %d, '%s'\n", j+1, repeatcount[j], testarray[j]); err = SHA1Reset(&sha); if (err) { fprintf(stderr, "SHA1Reset Error %d.\n", err ); break; /* out of for j loop */ } for(i = 0; i < repeatcount[j]; ++i) { err = SHA1Input(&sha, (const unsigned char *) testarray[j], strlen(testarray[j])); if (err) { fprintf(stderr, "SHA1Input Error %d.\n", err ); break; /* out of for i loop */ } } err = SHA1Result(&sha, Message_Digest); if (err) { fprintf(stderr, "SHA1Result Error %d, could not compute message digest.\n", err ); } else { printf("\t"); for(i = 0; i < 20 ; ++i) { printf("%02X ", Message_Digest[i]); } printf("\n"); } printf("Should match:\n"); printf("\t%s\n", resultarray[j]); } /* Тест возвращает некоторые ошибки */ err = SHA1Input(&sha,(const unsigned char *) testarray[1], 1); printf ("\nError %d. Should be %d.\n", err, shaStateError ); err = SHA1Reset(0); printf ("\nError %d. Should be %d.\n", err, shaNull ); return 0; } }
[1] "Secure Hash Standard", United States of American, National Institute of Science и Technology, Federal Information Processing Standard (FIPS) 180-1, April 1993.
[2] "The MD4 Message Digest Algorithm," Advances in Cryptology - CRYPTO '90 Proceedings, Springer-Verlag,1991, pp. 303-311.
[3] Rivest, R., "The MD4 Message-Digest Algorithm", RFC1320, April 1992.
[4] [RFC 1321] Rivest, R., "The MD5 Message-Digest Algorithm", RFC1321, April 1992.
[5] Eastlake, D., Crocker, S. и J. Schiller, "Randomness Requirements for Security", RFC 1750, December 1994.
[6] https://en.wikipedia.org/wiki/SHA-1
|
Previous: 6.17 Алгоритм вычисления дайджеста сообщения MD5 (RFC-1321, R. Rivest, апрель 1992)
UP:
6 Сетевая безопасность |