|
Previous: 4.1.13 Коммутируемая мультимегабитная информационная служба SMDS
UP:
4.1 Локальные сети (обзор) |
|
Previous: 4.1.13 Коммутируемая мультимегабитная информационная служба SMDS
UP:
4.1 Локальные сети (обзор) |
4.1.14 Адаптивные, кольцевые, высокоскоростные сети IEEE 802.17
Семенов Ю.А. (ГНЦ ИТЭФ)
| Обзор |
| Протокол RPR |
| Режимы AM и CM протокола SRP |
| Ссылки |
Региональные сети МАN обычно выполняют функции опорных сетей. В качеcтве MAN часто использовались FDDI, Token Ring или SDH. Кольцевая топология сети обеспечивает высокую надежность (при использовании двойного кольца) и удобна для работы с оптическими волокнами. Топология звезды уязвима в случае выхода из строя центрального узла. Топология сетки гарантирует высокую надежность, но существенно дороже кольца. Так как сети FDDI с их полосой 100 Мбит/c устарели, а Token Ring еще медленнее, приемлемого современного решения нет. Попутно замечу, что первая опорная сеть в РФ (ЮМОС, 1993г) была выполнены с применением именно технологии FDDI. В FDDI пакеты уничтожаются отправителем и по этой причине совершают полный круг. Маркерный доступ в принципе имеет определенные ограничения. Сегодня требуются адаптивные решения для региональных опорных сетей (МАN). Здесь желательны подходы, гарантирующие равноправное распределение ресурсов между разными потоками. Конечно, можно использовать решения, предлагаемые SONET (SDH). Но SDH гарантирует определенную полосу при связи точка-точка, но при этом неиспользуемая пропускная способность не может быть предложена для транспортировки других потоков. Можно построить кольцевую сеть на основе Гига-Ethernet (GE). Но этот протокол не может гарантировать равные возможности для разных потоков, да и эффективность использования доступной полосы нельзя признать хорошей. Низкая эффективность связана с тем, что протокол STP блокирует некоторые связи, препятствую образованию петлевых маршрутов, что в некоторых случаях удлиняет путь. GE, несмотря на ряд привлекательных черт, имеет четыре ограничения.
Во-первых, как уже отмечалось выше, Ethernet лишен механизмов выравнивания возможностей для разных потоков. Во-вторых, протокол STP запрещает кольцевые маршруты и один из участков кольцевой сети должен быть блокирован или замыкаться через маршрутизатор, что уводит сеть с уровня L2. В-третьих, когда канал или узел отказывает, дерево связей Ethernet должно быть заново вычислено, а это может потребовать нескольких сотен миллисекунд. Определенное замедление может вызвать восстановление связности, когда используется протокол маршрутизации уровня L3. Наконец, хотя GE может предоставить простую схему приоритетного обслуживания, такая сеть не имеет механизмов гарантирования полосы пропускания, задержки и разброса времени доставки, которые имеют SONET и RPR.
Кольца SONET обеспечивают связь между узлами кольца по схеме точка-точка. SONET может гарантировать базовые параметры качества обслуживания. Время восстановления такой сети в случае отказа измеряется десятками миллисекунд. Основным недостатком SONET является неэффективность использования доступной полосы. Если все узлы требуют соединения со всеми, кольцо с N узлами будет требовать N2 соединений. Даже при ограниченном числе узлов в кольце, например при N=100, это может вызвать определенные проблемы.
Начиная с 2000 года, разрабатывается новый протокол для опорных региональных сетей с двойной кольцевой топологией (http://www.ieee802.org/17, сервер к сожалению платный и мало кому доступен). Этот протокол IEEE 802.17 называется RPR (Resilient Packet Ring - адаптивное кольцо для пакетов). В отличие от FDDI (а также Token Ring или DQDB) в этом протоколе пакеты удаляются из кольца узлом-адресатом, что позволяет осуществлять несколько обменов одновременно. Но такая схема параллельных обменов осложняет равенство возможностей для разных узлов в кольце. Кроме того, схема уничтожения пакета отправителем имеет и определенные преимущества. Так транспортировка пакета от получателя к отправителю обеспечивает подтверждение получения, что все равно надо делать, например, в случае протокола ТСР. Для пояснения особенностей работы RPR рассмотрим схему на рис. 1, где четыре потока совместно используют канал 4, чтобы достичь узла 5. В этом примере каждый из этих потоков должен получить 1/4 долю полосы (алгоритм "parallel parking lot")?
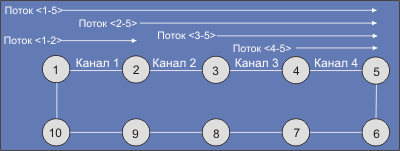
Рис. 1.
Чтобы полностью использовать имеющиеся ресурсы на участке <1-2>, можно пропустить через канал еще 3/4 от того, что протекает между узлами 1 и 5. Чтобы максимально возможно использовать имеющиеся ресурсы, узлы должны взаимодействовать друг с другом. Таким образом, для обеспечения равенства доступа к ресурсам алгоритм должен дросселировать трафик на входе узлов.
В RPR также как и в Ethernet пакет удаляется в точке назначения, что позволяет использовать незадействованную часть кольца RPR реализует алгоритм распределенного выравнивания возможностей для разных потоков. Протокол не использует алгоритм STP и по этой причине может работать с замкнутыми маршрутами без ограничений. Кольцо RPR транспортируют пакеты по пути вдоль кольца с минимальным числом шагов. Если какой-то узел или двунаправленный участок кольца откажет, RPR формирует альтернативный маршрут за время не более 50 мсек. Например, если канал между узами 4 и 5 будет оборван, узлы 4 и 5 будут соединены по маршруту 4-3-2-1-10-9-8-7-6-5.
Наконец, в RPR можно определить несколько классов трафика, что крайне важно для мультимедийных приложений. Класс А реализует канальное соединение между узлами кольца с гарантированной полосой, задержкой доставки и дисперсией времени доставки (аналогично SONET, но без ограничений дискретных значений полосы - OC-3, OC-12 и т.д.). Класс В имеет гарантированную полосу, но допускает кратковременные возрастания трафика сверх согласованных значений за счет потоков, которые не имеют гарантии полосы. Класс С предлагает услуги типа "лучшее-что-возможно", при этом не гарантируются никакие параметры трафика.
Целью RPR является одновременное достижение равных возможностей для разных потоков и высокая эффективность использования имеющихся ресурсов. Достижение равных возможностей можно проследить на примере реализации алгоритма "parallel parking lot" на рис. 1. Региональный сервис-провайдер стремится предоставить равные возможности всем клиентам, вне зависимости оттого, к какому узлу они подключены. На рис. 1 это означает предоставление каждому из потоков 1/4 полосы пропускания узла 5. Требования высокой эффективности использования ресурсов предполагают возможность привлечения всех ресурсов, незадействованных для обеспечения равных возможностей для всех конкурирующих потоков. Примером использования имеющихся ресурсов является поток между узлами 1 и 2 на рис. 1, который использует до 75% пропускной способности этого канала. Если реализовать указанные цели, то любые два узла в кольце смогут обмениваться данными со скоростью, ограниченной уровнем насыщения (перегрузки) канала.
| Таким образом, целью алгоритма справедливого распределения ресурсов является дросселирование потоков во входных точках, чтобы обеспечить равенство доступа к ресурсам. |
Это означает, что в случае, показанном на рис. 1, поток между узлами 1 и 5 должен быть дросселирован в точке 1 до уровня 0.25 от пропускной способности участка 4-5, оставляя доступной полосу на участке 1-2 на уровне 75%. Такое идеальное поведение может быть описано с помощью модели RIAS (Ring Ingress Aggregated with Spatial Reuse). Модель RIAS содержит в себе два ключевых компонента. Первый - определяет степень гранулярности трафика для определения справедливости распределения ресурсов. Модель RIAS гарантирует, что все узлы отправители получат равные доли полосы пропускания для каждого канала относительно долей других узлов отправителей. Второй компонент RIAS гарантирует максимальное использование ресурса сети при равном выделении полосы пропускания. Ресурс полосы может анонсироваться, если он не затребован или если не может быть использован из-за наличия узкого места где-то в другом узле или канале. Похожий (но несколько отличный от RPR) алгоритм распределения ресурсов реализован протоколом ТСР в сетях Интернет (уровень L4), здесь же это предлагается делать на уровне L2.
В случае класса А узлам запрещается анонсировать неиспользуемые ресурсы. Рассмотрим работу алгоритма для классов B (фиксированная полоcа) и С ("лучшее-что-возможно"), в которых каждый узел анонсирует неиспользуемую полосу взвешенным образом. Архитектура RPR-узла показана на рис. 2. Весь трафик, входящий в кольцо, дросселируется контроллерами потоков. В случае алгоритма "parallel parking lot" поток <1-5> должен быть снижен до уровня 1/4. Контроллеры потоков работают с учетом гранулярности, определяемой адресатом. Трафик делится на две категории в зависимости от того, проходит ли он через перегруженный учаcток. Протокол RPR поддерживает обслуживание выходных очередей, как это делается в обычных переключателях.

Рис. 2.
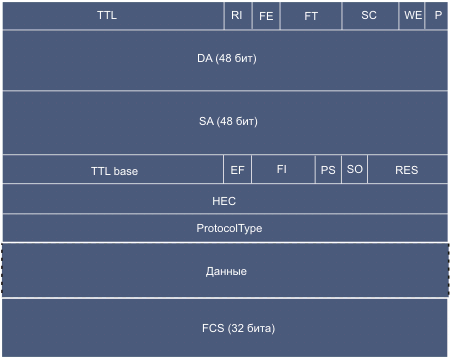
Рис. 3. Формат пакетов протокола RPR
TTL - поле времени жизни (Time to live)
RI - идентификатор кольца (Ring identifier) определяет кольцо, где был введен пакет
FE - бит "fairness eligible" указывает на то, что пакет должен следовать правилам алгоритма справедливости.
FT - два бита типа кадра: данные, справедливость, управление, пассивность (Data, Fairness, Control, Idle)
SC - два бита "класса услуг":A0, A1, B, C
WE - бит "wrap eligible" определяет, может ли пакет быть wrapped в wrap узле
P - бит четности ("parity") зарезервирован на будущее для кадров данных
DA - шесть байтов адреса места назначения (destination address)
SA - шесть байтов адреса отправителя (source address)
TTL base - значение этого поля устанавливается равным ttl, с которым пакет попал в кольцо. Оно используется для быстрого вычисления числа шагов, которые прошел пакет
EF - бит расширенного кадра (extended frame), указывающий на расширенный формат кадра
FI - два бита "flooding indication" устанавливаются, когда кадр вызывает переполнение в одном или обоих кольцах
PS - бит "passed source" устанавливается, при прохождении своего отправителя в противоположном кольце после операции wrap. Бит используется для детектирования ошибочного условия, когда пакет должен быть удален раньше
SO - бит "strict order", если установлен, указывает, что кадр должен быть доставлен в строго определенном порядке.
RES - 3-битовое резервное поле
HEC - два байта поле коррекции ошибок в заголовке, покрывает исходные 16 байт заголовка
Узлы RPR имеют модули измерения (счетчики байт), которые контролируют информационный поток станции и транзитные потоки. Результаты этих измерений используются алгоритмом справедливого распределения ресурсов полосы пропускания (fairness algorithm) для вычисления параметров управляющего сигнала, направляемого вышестоящим узлам для дросселирования их потоков. Узлы, которые получают такие сообщения, используют полученные данные совместно с локальной информацией для управления контроллерами входных потоков (см. рис. 2).
Узел, кроме того, содержит планировщик, который осуществляет арбитраж для внутренних и транзитных потоков. В режиме одной очереди для транзитного потока имеется один буфер типа FIFO, эта очередь называется PTQ (primary transit queue). В этом случае планировщик предоставляет абсолютный приоритет транзитному трафику по отношению к локальному. В режиме двойной очереди (dual-queue mode) имеется две транзитные очереди, одна для класса А (PTQ) и одна для класса В и С - STQ (secondary transit queue). В этом режиме планировщик всегда обслуживает в первую очередь трафик класса А. Трафик класса А самой станции будет обслужен сразу после PTQ, если STQ не заполнена. В противном случае планировщик обслуживает сначала трафик STQ, гарантируя отсутствие потерь. При прочих равных условиях планировщик использует карусельный принцип обслуживания очереди STQ для транзитного трафика и трафика станции классов В и С до тех пор, пока не будет достигнут порог для STQ. Когда достигается порог буфера STQ, транзитный трафик STQ получает преимущество по отношению к трафику станции.
В обоих случаях определяющим является стремление к простоте оборудования (исключение дорогостоящих решений с индивидуальными очередями для каждого потока или каждого входа) и подавлению потерь. Пакет, вошедший в кольцо, не должен быть потерян в последующих узлах.
Существуют два режима работы алгоритма справедливого распределения полосы RPR. Первый из них - агрессивный (АМ - aggressive mode) происходит от протокола SRP (Spatial Reuse Protocol), широко используемого во многих региональных сетях. Второй консервативный режим СМ (conservative mode) связан с алгоритмом Аладдина. Оба режима работают схожим образом. Перегруженный узел, размещенный ниже по течению, передает свое состояние перегрузки узлам вверх, так что они дросселируют свой трафик, обеспечивая достаточную полосу транспортировки для станции внизу. Чтобы достичь этого, перегруженный узел передает информацию вверх по течению и все узлы, расположенные там, должны соответствующим образом дросселировать свои потоки. Спустя некоторое время перегрузка ослабеет, и все узлы получат справедливые доли пропускной способности. Аналогично, когда перегрузка исчезает, станции станут периодически увеличивать свой темп отправки данных, таким образом, получая максимально возможную долю полосы пропускания.
Существует два ключевых параметра для управления полосой пропускания в RPR, это forward_rate и add_rate. Первый представляет загрузку от транзитного трафика, а второй - полную загрузку от трафика станции. Оба параметра измеряются в байтах за фиксированный период времени (aging_interval). Измерение обеих величин производится на выходе планировщика и подвергается экспоненциальному усреднению.
Один раз за aging_interval каждый узел проверяет свое состояние перегрузки c учетом режима работы (АМ/CM). Когда узел N перегружен, он вычисляет свою скорость обмена local_fair_rate[N], которая является справедливым (fair) значением потока, который может быть передан узлу N. Узел N затем передает управляющее сообщение, содержащее значение local_fair_rate[N], своему выше стоящему соседу.
Если выше расположенный узел (N-1) при получении сообщения перегрузки от узла N, сам является перегруженным, он направит это сообщение выше расположенному узлу, используя значение, которое является минимальным из local_fair_rate[N] и local_fair_rate[N-1]. Определяющим здесь является информирование вышестоящих узлов о минимальной скорости передачи, которую они могут допустить, направляя трафик к месту назначения. Если узел N-1 не перегружен, но его forward_rate больше полученного значения local_fair_rate[N], он переадресует управляющее сообщение, содержащее local_fair_rate[N], вверх по течению, так как перегрузка сопряжена с транзитным трафиком, идущем сверху. В противном случае посылается управляющее сообщение с нулевым значением уровня перегрузки. Когда вышестоящий узел i получает управляющее сообщение с параметром local_fair_rate[N], он понижает свое ограничение на скорость передачи для потоков, следующих через перегруженный канал (allowed_rate_congested). Это значение равно сумме допустимых скоростей передачи потоков (i,j) для всех j, для которых n лежит на пути от i к j. Система настраивается так, чтобы вышерасположенные узлы отрегулировали свои контроллеры потоков на уровень, соответствующий допустимому. Следовательно, трафик станции не будет превосходить анонсированного значения local_fair_rate для любого из перегруженных узлов ниже по течению. В противном случае, если получено управляющее сообщение с нулевым значением fairness, узел увеличивает allowed_rate_congested на фиксированную величину, так что он может анонсировать наличие дополнительной полосы пропускания в случае, если один из потоков ниже по течению снизит свою интенсивность. Более того, такое сокращение потока существенно для сходимости процесса установки справедливых долей потоков даже в случае статического запроса.
Главным отличием между режимами АМ и СМ является детектирование перегрузки и вычисление локального значения справедливой величины потока. По умолчанию АМ использует режим двойной очереди, а СM - режим одной очереди.
Агрессивный режим (АМ) является режимом работы алгоритма обеспечения справедливого распределения ресурсов в RPR по умолчанию. В режиме АМ узел N считается перегруженным, если:
STQ_depth[N] > low_threshold
или
forward_rate[N] + add_rate[N] > unreserved_rate
где, как это было описано выше, STQ является транзитной очередью для трафика классов В и С. Значение порога low_threshold является долей размера транзитной очереди, по умолчанию равной 1/8 от размера очереди STQ. unreserved_rate равна полосе канала минус доля полосы, зарезервированная для трафика с гарантированным качеством обслуживания. Так как здесь рассматривается только режим "лучшее-что-возможно", далее будем считать, что unreserved_rate равна полосе канала.
Когда узел перегружен, он вычисляет свое значение local_fair_rate как нормированную скорость обслуживания собственного трафика, add_rate, и затем посылает управляющее сообщение, содержащее add_rate, вышестоящим узлам.
Рассмотрим пример алгоритма "parking lot" (рис. 1). Если ниже расположенный узел анонсирует значение add_rate ниже уровня справедливого значения потока (что типично для ситуации без перегрузки), все вышестоящие узлы дросселируют потоки до этого уровня. Этот процесс осциллирует вокруг справедливого значения потока.
Каждый СМ (Conservative mode) узел имеет таймер доступа, измеряющий время между двумя последовательными передачами пакетов станции. Так как СМ использует непосредственно приоритет транзитного трафика в отношении трафика станции в рамках режима одной очереди, этот таймер служит для того, чтобы гарантировать отсутствия блокировки трафика станции. Таким образом, в режиме СМ узел N считается перегруженным, если истекло время таймера доступа, или:
forward_rate[N] + add_rate[N] > low_threshold
В отличие от АМ low_threshold для СМ представляет собой параметр, имеющий размерность скорости передачи, и значение меньше полосы пропускания канала. Значение 0,8 от полосы канала является величиной по умолчанию. В дополнение к forward_rate и add_rate СМ режим выявляет ID узла путем анализа заголовка каждого пакета, и измеряет число активных станций, которые прислали хотя бы один пакет за время aging_interval.
Если узел СМ перегружен за время текущего aging_interval, но не был перегружен в предыдущий интервал, значение local_fair_rate вычисляется как общая не зарезервированная скорость обмена, деленная на число активных станций. Если узел постоянно перегружен, значение local_fair_rate зависит от суммы forward_rate и add_rate. Если эта сумма меньше low_threshold, что индицирует недогруженность канала, значение local_fair_rate линейно увеличивается. Если эта сумма больше high_threshold (0,95 от емкости канала), то local_fair_rate линейно понижается.
Рассмотрим снова пример алгоритма "parking lot" (рис. 1), когда канал между узлами 4 и 5 оказался впервые перегружен, узел 4 передает данные со скоростью 1/4 (истинно справедливая доля полосы). Канал при этом будет рассматриваться перегруженным, так как его полный поток больше low_threshold. Более того, поскольку полный поток больше high_threshold, local_fair_rate будет периодически понижаться, пока сумма add_rate и forward_rate в узле 4 не станет меньше high_threshold, но больше low_threshold. Таким образом, для СМ максимальное использование канала будет соответствовать high_threshold.
Переходные процессы установления справедливых долей потока в системе может иметь осциллятивный характер (смотри [1,2]).
| 1 | Ping Yuan, Violeta Gambiroza, Edward Knightly, "The IEEE 802.17 Media Access Protocol for High-Spead Metropolitan-Area Resilient Packet Rings", IEEE Network, May/June 2004 |
| 2 | Violeta Gambiroza, Ping Yuan, Laura Balzano, Edward Knightly, Yonghe Liu, Steve Sheafor, "Design, Analysis, and Implementation of DVSR: A High-Performance Protocol for Packet Rings", IEEE/ACM Transactions on Networking, V. 12, N 1, February 2004. |
| 3 | Г.Г. ЯНОВСКИЙ, А.А. РУИН, "Транспортные сети следующего поколения", Вестник связи №2 2004 (http://www.vestnik-sviazy.ru/archive/02_2004/tra.html) |
| 4 | http://www.ece.rice.edu/networks/RPR/ |
Previous: 4.1.13 Коммутируемая мультимегабитная информационная служба SMDS
UP:
4.1 Локальные сети (обзор) |




