|
Previous: 4.7.11 Информационные центры
UP:
4.7 Прикладные сети Интернет |
|
Previous: 4.7.11 Информационные центры
UP:
4.7 Прикладные сети Интернет |
4.7.12 Мета язык программирования
Семенов Ю.А. (ГНЦ ИТЭФ)
Люди все в большей степени зависят от компьютеров и сетевых технологий. Но программы на компьютерах содержат большое число ошибок, люди не умеют их не делать. В этой связи возникает вопрос, как можно минимизировать число программных ошибок? Существуют различные отладчики, ищущие ошибки синтаксиса языка программирования, разрабатываются статические и динамические код-чекеры, призванные выявлять ошибки алгоритма программы. Но число ошибок только растет. Это связано с быстро увеличивающейся сложностью программ.
Ядро ОС Windows NT 3.1 имело 4,5 миллионов строк кода, версия 3.5 – в 1994 г. – 7,5 млн. строк кода. Windows XP (2001г) содержит в себе 45 миллионов строк кода, практически все версии ядра Linux содержат столько же или даже больше строк кода. Число ошибок в коммерческих программах компании Microsoft составляет 0,5 на 1000 строк кода, отсюда предполагаемое число ошибок в ядре ОС Windows XP превышает 20000. А кроме ядра есть еще оболочка ОС и приложения...
Все мы сталкивались с ситуациями повисания ОС или приложения. В крайнем случае мы нажимаем клавишу Reset и через минуту продолжаем работу. Но если программа управляет полетом ракеты, или системы реанимации, ситуация меняется качественно. Уже зарегистрированы случаи смерти людей из-за программной ошибки, например, в системе управления радиационной терапии. Актуальность минимизации числа программных ошибок очевидна.
| Одним из путей минимизации числа программных ошибок может быть сокращение участия программиста в процессе создания программы. |
Возможным шагом на пути минимизации числа программных ошибок может стать создание мета языка программирования (meta language - M_Lan), который будет служить не для описания алгоритма, а для описания стоящей проблемы. Почему такой путь может гарантировать уменьшение числа ошибок? Мы сегодня с высокой степенью достоверности уверены в отсутствии ошибок в программах вычисления значений стандартных функций (тригонометрических, логарифмов и пр.). Это связано с тем, что они проверены десятками тысяч пользователей для огромного многообразия аргументов. После создания банка алгоритмов и начала его использования достаточно быстро будут выявлены и устранены ошибки из этих алгоритмов, так как они будут опробованы тысячами пользователей при решении самых разных задач во всем возможном диапазоне параметров.
Алгоритмические модули, лежащие в базе данных, должны иметь максимально возможную универсальность, ограниченные размеры и максимально возможную прозрачность (понятность). Кроме самих текстов программ в базе данных должны содержаться их описания, диапазоны параметров, возможная диагностика и идентификатор алгоритмического языка, на котором программа написана, идентификатор автора, дата создания, дата и автор последней коррекции. При их создании разработчикам следует пользоваться правилам Хольцмана для программистов (см. http://book.itep.ru/10/holz_rules.htm), это снизит вероятности ошибок. Правила Хольцмана использовались при написании программ управления американскими Шатлами, где была достигнута вероятность ошибки менее 0,003 на 1000 строк кода (из доклада акад. Иванникова В.П на семинаре ВМК МГУ).
Для каждой области (физика, биология, химия, лингвистика, экономика, медицина инженерия и т.д.) должен быть создан банк известных алгоритмов, уже опробованных для решения различных задач в данной области. Описаниями этих алгоритмов будет пользоваться программист и программа-интерпретатор, генерирующая исполняемую программу.
Стандартное описание алгоритма сегодня - это текст программы на одном из известных языков программирования (недаром они называются алгоритмическими языками). Но использование этих описаний сопряжено с определенными трудностями. Эти описания содержат внешние вставки (include), макросы и ссылки на специфические библиотечные программы, вызовы других подпрограмм или функций. Кроме того, подавляющее их число не имеет сколько-нибудь подробного описания. При создании базы данных алгоритмов надо будет решить эти проблемы. Каждому алгоритму должно быть присвоено уникальное имя-идентификатор (ALID).
Банк алгоритмов может стать мишенью сетевых атак. Это могут быть атаки типа SQL-injection, а также DoS атак за счет большого числа запросов в базу данных. Препятствовать этим атакам будет регистрация всех пользователей и их сертификация. Любые запросы от несертифицированных пользователей будут отклоняться. Вообще пакеты, адресованные базе данных от IP незарегистрированных пользователей, должны блокироваться и не пропускаться к серверу банка алгоритмов.
Создание макро-языка M_Lan столь масштабно, что это не по плечу не только отдельному человеку, но и одной большой организации или компании. Разумеется, для достижения успеха потребуется международное сотрудничество.
Ситуация усложняется тем, что конкретные (существующие) алгоритмы могут быть привязаны к определенным алгоритмическим языкам (Cobol, ProLog, SmallTalk, Perl, Java, Python, C, С++ и т.д.). В некоторых случаях, например, для обработки прерываний используются программы, написанные на ассемблере конкретного процессора. По существу M_Lan будет формировать исполняемый образ программы на основе библиотеки описаний алгоритмов (нечто в роде taskbuilder в Си++).
Для создания мета языка программирования нужно решить несколько проблем:
В идеале нужна машина с искусственным интеллектом, только такой компьютер сможет создавать новые алгоритмы, которых нет в банке. Здесь уместно заметить, что нужна машина с высоким уровнем интеллекта. По американским прогнозам такая машина появится в 2023 году, а к 2045 году будет создана персональная машина, существенно превосходящая человека по интеллекту. Будет ли такая машина всегда безошибочна? Если вероятность ее ошибки будет равна вероятности ошибки человека, пользы от нее для минимизации программных ошибок не будет.
Но начинать можно и без этого. Ведь очень часто создаются программы, алгоритмы работы которых известны и нужно лишь адаптировать их к требованиям конкретной задачи. Решением проблемы может быть суперпозиция известных алгоритмов. Ниже в таблице приводится перечень возможных этапов решения задачи. Начинать, вероятно, следует с третьего этапа.
| Номер этапа | Используемый компьютер | Реализуемая функция |
| 1 | Компьютер с высоким искусственным интеллектом | Описание проблемы анализируется, определяется контекст задачи и вырабатывается компьютером текст программы |
| 2 | Обычный компьютер | Описание проблемы анализируется и на основе описаний алгоритмов, извлекаемых из банка, вырабатывается компьютером текст программы |
| 3 | Обычный компьютер | Описание проблемы анализируется и на основе описаний библиотеки программ, извлекаемых из банка программ, вырабатывается компьютером исполняемый образ программы |
В процессе реализации этапа 3 будут созданы библиотеки с открытым кодом, которые должны быть доступны для использования всем желающим. Это позволит устранить из них имеющиеся ошибки. Эти библиотеки станут основой библиотеки алгоритмов для этапа 2.
Некоторые алгоритмы носят универсальный характер (статистическая обработка, аппроксимация, вычисление стандартных функций или интегралов, компьютерная графика и пр.). Такие алгоритмы могут храниться в одном из банков удаленных ветвей семантического дерева. По этой причине нужно будет создать систему универсальных идентификаторов алгоритмов и общую базу данных, обращение к которой упростит поиск нужного алгоритма.
Описание проблемы должно проводиться на естественном языке, как это делается в машине Watson (IBM). Для этого программа должна научиться распознавать контекст проблемы. На начальном этапе контекст может выявляться в результате диалога между машиной и программистом.
Все многообразие проблем будет характеризоваться семантическим деревом. В каждом узле этого дерева будет размещаться банк алгоритмов, которые соответствует контексту этого узла. Таким образом, банк алгоритмов будет распределенным.
Учитывая многообразие отраслей и алгоритмов могут потребоваться программные интерфейсы для согласования описаний алгоритмов из разных сфер программирования.
Я планирую начать с переписывания своих программ мониторинга сетевых атак в формат нового стандарта описания алгоритмов. В начале это может быть нечто, напоминающее программную библиотеку.
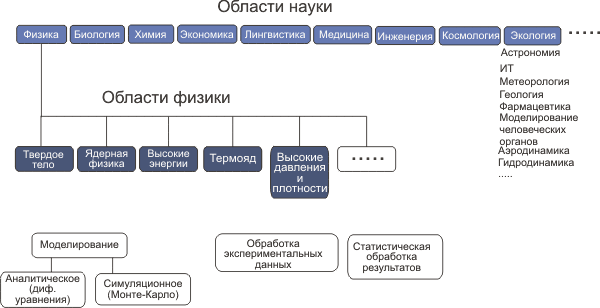
После того как контекст проблемы определен, начинается описание конкретной задачи. Эта часть может выполняться также в диалоговом режиме. После того как задача описана, машине передаются входные параметры задачи. Машина может запрашивать дополнительные данные, необходимые для решения или уведомлять об отсутствии нужного алгоритма или данных.
Формат описания алгоритма может иметь несколько форматов:
Если алгоритма в банке алгоритмов нет, программа может быть создана самим программистом в соответствии с определенными правилами и помещена в банк алгоритмов с указанием имени, адреса автора, даты занесения, а также подробного описания. Этому алгоритму присваивается уникальный идентификатор (ALID). При этом должны быть внесены соответствующие обновления в базу данных описаний алгоритмов.
Все тексты описаний алгоритмов должны быть open source. Создатель описания алгоритма и все программисты, внесшие свои вклады должны быть зарегистрированы и им присваиваются уникальные идентификаторы (PRID). В базе данных фиксируется время создания описания, авторы и моменты внесения всех правок, а также идентификаторы программистов, их внесших. В базу данных записываются все случаи использования алгоритма и параметры использования. Сохраняются до 10 версий описаний с идентификаторами контрибютеров. Вся эта процедура нужна для минимизации возможности преднамеренного внесения вредоносных вставок в программы. Создается форум, на котором обсуждаются алгоритмы и случаи их использования, предложения по их совершенствованию. При поступлении предложения нового алгоритма или модификации уже существующего, соответствующая программа попадает в банк кандидатов, откуда ее может извлечь любой желающий для использования. После определенного периода апробации или после оговоренного числа применений описание алгоритма (или библиотечная функция) переносится в основной банк алгоритмов.
На первом этапе программы-функции могут быть написаны, например, на языке Си (или C++).
Далее нужно будет рассмотреть алгоритмы для языков COBOL, PROLOG, Smalltalk и др.
Формирование текста программы начинается с определения контекста проблемы. Это делается автоматически путем семантического анализа или в диалоговом режиме программистом.
Идентификатор контекста СP в дальнейшем является индексом при выборе базы данных описаний алгоритмов или библиотеки функций.
Формируемый текст программы является заведомо вариативным, изменяющимся на основе полученных результатов или при изменении входных параметров. Параметрами программы могут быть имена других программ. Система имеет встроенный механизм контроля входных параметров. Число вложений программ не лимитируется.
Список функций-подпрограмм-алгоритмов параметров обращения имеет вид счетного массива: число, за которым следует список из n имен функций-подпрограмм-алгоритмов (f_names), разделенных запятыми. Число характеризует количество элементов в списке. Допускается и одно имя в формате "1, f_name". У f_name в свою очередь могут быть параметры, значения которых записываются в скобках. Например, poly(x1, x2,...,xn), если число параметров больше или меньше оговоренного, выдается уведомление об ошибке. В приведенном примере f_name=poly.
Рассмотрим пример. Имеется функция-подпрограмма Fun=aX12+ bX2 + c. Возможно обращение:
A=Fun(a=10; X1=(x=1); b=5; X2=(y=0.5); c=1);
Тогда будет вычислено значение простого полинома второго порядка. Но возможно обращение и:
A=Fun(a=10; X1=sin(x=1); b=5; X2=cos(x=0.5); c=1). Это показывает вариативность работы функций-подпрограмм.
На каком языке следует писать базовые программы и все ли они должны быть написаны на одном языке, можно решить позднее на основе полученного опыта.
Статья с описанием предложения разработки мета-языка опубликована в журнале "Труды НИИСИ РАН том 6, №2", Москва, 2016, с. 96-100 ("Разработка банка алгоритмов и основ языка описания проблем с целью минимизации числа программных ошибок", Ю.А.Семенов, А.П.Овсянников, Т.В.Овсянникова.).
В сентябре 2017 года выйдет статья "Язык описания проблемы, а не алгоритма, как средство минимизации программных ошибок", Доренская Е.А., Семенов Ю.А., Современные информационные технологии в ИТ-образовании, №2, 2017г, ВМК МГУ.
Previous: 4.7.11 Информационные центры
UP:
4.7 Прикладные сети Интернет |




