|
Previous: 4.7.7 Унифицированные коммуникации (UC)
UP:
4.7 Прикладные сети Интернет |
|
Previous: 4.7.7 Унифицированные коммуникации (UC)
UP:
4.7 Прикладные сети Интернет |
4.7.8 Параллельные вычисления (многоядерный вариант)
Семенов Ю.А. (ГНЦ ИТЭФ)
Параллельные вычисления используются достаточно давно, но только после 2004 года, когда стало ясно, что дальнейший быстрый род тактовой частоты ЦПУ проблематичен, началось быстрое развитие технологии многоядерных процессоров. Смотри The Parallel Computing Imperative. Техника параллельных вычислений стала крайне актуальной в связи с широким внедрением виртуализации и cloud computing.
Ресурс увеличения плотности активных элементов на чипе еще сохранялся и именно это сделало многоядерные процессоры привлекательными для повышения производительности вычислений. В настоящее время число ядер удваивается каждые 18 месяцев.
Многоядерность упрощает проблему работы машин с сетевыми интерфейсами 10-100 Гбит/с, так как имеется возможность разделить обработку потока на несколько субпотоков, поступающих на отдельные ядра. Если 100 гигабитный поток разделить на 10 субпотоков, а процессор имеет 64 разряда, то будет достаточно иметь тактовую частоту > 350 МГц. Следует заметить, что рассматриваемые ниже технологии сходны с методиками, используемыми в системах GRID.
Существует несколько подходов в применении многоядерных процессоров:
Сравнение Hadoop и DataRush показывает, что Hadoop имеет преимущество для массивов, состоящих из сотен или тысяч серверов, а второе решение эффективно для SMP-серверов (отдельных или в небольших кластерах), оно обеспечивает заметно большее быстродействие. Это решение следует считать достаточно перспективным.
Если вы работаете в ОС UNIX и запустили WEB-сервер, то увидите, что активизировалось до 20 процессов. При этом все эти процессы используют один и тот же ресурс (предполагается, что у вас одноядерный ЦПУ). Если у вас два ЦПУ с двумя ядрами каждый, процессы будут распределены между ними. Это процессный уровень параллелизма. UNIX использует именно такую схему, хотя и не слишком эффективно. Ядра процессора обычно загружены не равномерно.
Когда одна и та же программа запускается несколькими пользователями, формируется тред (thread) для каждого из пользователей. На рис. 1 показан пример параллелизма тредов. Все треды могут использовать одно ядро, а если оно окажется перегруженным, задания могут перейти на другие ядра.
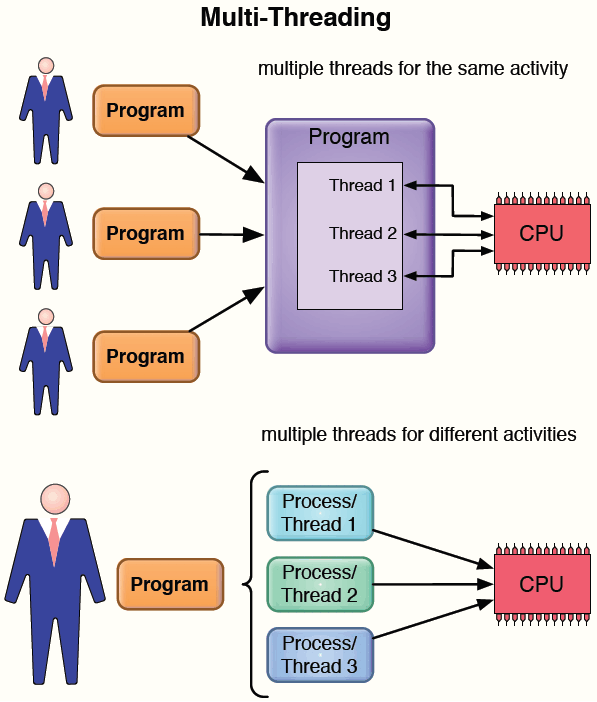
Рис. 1. Многопоточные вычислительные процессы (threads)
В идеале желательно иметь возможность управлять механизмом распараллеливания, как на уровне компилятора, так и на уровне дизайна чипа. Компилятор должен быть способен взаимодействовать с логикой чипа для оптимизации процесса распараллеливания. Отдельные части программы должны выполняться в определенном порядке. Компилятор должен понимать какие части программы можно выполнять одновременно. Такая работа программы показана на рис. 2, где предполагается, что ЦПУ имеет восемь ядер. Эффективность использования ЦПУ в данном случае не превышает 25%. Такая схема обеспечивает большую скорость выполнения кода, но недостаточно эффективна. Если в ЦПУ будет 16 ядер, быстродействие увеличится еще на 5%. Это показывет, что распараллеливание выполнения инструкция крайне не эффективно.
Существует три механизма распараллеливания:
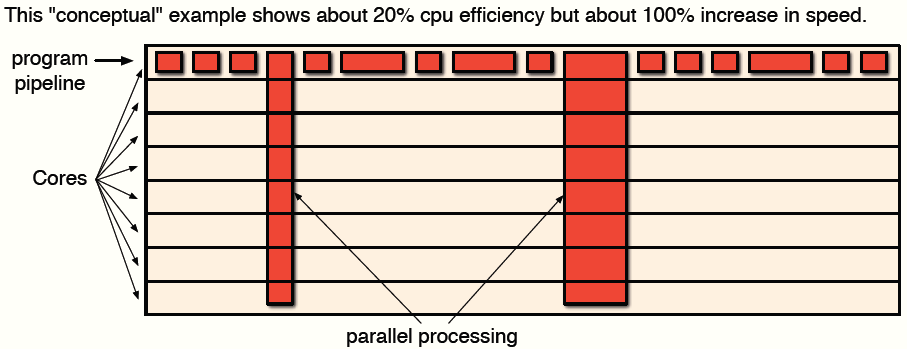
Рис. 2. Параллелизм инструкций
В течение многих лет ЦПУ имели большую вычислительную мощность, чем было нужно приложениям. И по этой причине рекомендовалось запускать на сервере более одного приложения. Надежность используемых ОС стимулировало запуск большого числа приложений на серверах и отработку технологии виртуальных машин. Виртуальная машина является полной эмуляцией реальной машины в рамках некоторого сервера. "Супер операционная система", называемая гипервайзером, управляет одной или более "гостевых" операционных систем, обеспечивая их всеми необходимыми для приложения ресурсами (смотри рис. 3).
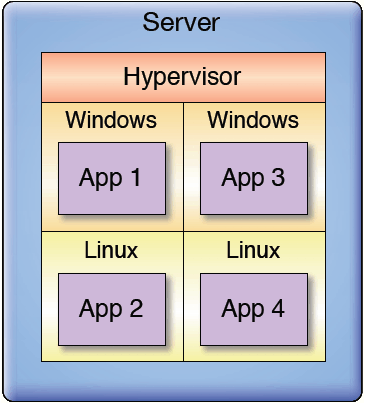
Рис. 3. Виртуальные партиции
ЦПУ на рисунке не обязательно является многоядерным. Система хорошо работает и на одноядерном процессоре. Но после 2002 года компьютеры стали достаточно мощными, так что большинство приложений занимали не более 10% ресурсов. С увеличением количества ядер машина может обслуживать большее число виртуальных машин. Заметим, например, что если у нас используется 4 гостевые операционные системы, на машине работает 5 разных ОС (см. рис. 3). Эффективность использования мощности компьютера при этом, как правило, не превышает 40%.
Google использует сотни тысяч серверов, больше чем любая другая компания. Это не удивительно для поисковой системы, работающей с 50 миллиардами WEB-страниц. Именно по этой причине компания Google была вынуждена разработать технологии распараллеливания для автоматизации разных процессов обработки данных. Эта система распараллеливания получила название MapReduce. Версия (и проект)с открытыми кодами имеет название Hadoop. Система Hadoop работает совместно с MapReduce, которая облегчает работу с модулями программы, написанными на Java. Частью Hadoop является распределенная файловая система HDFS, которая позволяет работать с большими объемами данных. Hadoop совместно с MapReduce предоставляет программистам платформу для написания распараллеленных программ. Рисунок 4 иллюстрирует то, как эти системы работают.

Рис. 4. Hadoop и MapReduce
HDFS - Hadoop Distributed File System (распределенная файловая система);
Scheduler - диспетчер;
Backup/Recov -
резервное копирование/восстановление.
В рамках рассматриваемой идеологии данные имеют формат ключ-значение (например, журнальный файл: <коды сообщения> (ключ) и данные). Логика установления ассоциаций (маппинг) для рекордов данных предполагает удаление некоторых деталей или даже рекордов (отсюда и название MapReduce). При этом могут формироваться некоторые промежуточные информационные рекорды. Процесс в общем случае является итеративным.
Предположим, что у нас имеется большой журнальный файл, содержащий сообщения и их коды, и мы просто хотим посчитать число рекордов каждого типа. Это можно сделать следующим образом:
Log-файл заносится в файловую систему и каждый узел считывает некоторые рекорды и формирует пары ключ-"1" (единица - число случае с указанным ключом). Редъюсер (reducer)осуществляет отбор по ключам, суммируя значения счетчиков. Если, например, речь идет о содержимом некоторого склада, то маппинг будет выполняться с помощью посылки запросов SQL-select. Операция же reduce предполагает сортировку и суммирование данных, полученных в результате SQL-запросов. Платформа Hadoop/MapReduce имеет встроенные механизмы резервного копирования и восстановления системы после сбоев.
Очевидным ограничением технологии является то, что она предполагает большое число серверов и очень большие объемы идентичных по форме информационных рекордов. Если серверов недостаточно, можно расширить их число с помощью cloud-технологии. В любом случае данная технология обеспечивает высокое быстродействие. Так сортировка терабайта данных (100 байт в рекорде) занимает 62 секунды при использовании 1460 узлов. Аналогично петабайт данных потребует 975 минут при числе узлов 3658. В настоящее время Hadoop рассчитано на 5000 узлов, но и это не предел.
Система HDFS по умолчанию хранит три копии любых данных, что гарантирует восстановление при любых сбоях в любом из узлов, что весьма важно для системы, содержащей тысячи узлов. Hadoop пока недостаточно адаптирована для использования в многоядерных системах, она в основном нацелена на работы с большими объемами данных.
Pervasive (всеобъемлющий) DataRush является продуктом компании Pervasive Software и предоставляет более универсальное решение, чем Hadoop и MapReduce. Это решение не требует специальной файловой системы и может работать практически с любыми источниками данных и доставлять результат куда угодно. DataRush не является конкурентом Hadoop, он нацелен на оптимизацию работы одного сервера. Такой сервер может иметь 4 8-ядерных ЦПУ.
Схема разделения данных и процессов для DataRush показана на рис. 5. Данные здесь поступают в параллель на 4 ядра. На нижней части рисунка показан конвейер обработки, когда результат работы одного процесса генерирует данные для процесса в следующем ядре. Таким образом, очередной процесс может стартовать, когда предыдущий начнет выдавать данные на его вход. Спустя какое-то время все четыре процесса-ядра будут задействованы. В то время как DataRush использует разделение по данных и по процессам, Hadoop применяет лишь информационные партишены. Для оптимизации вычислительного процесса программист должен понимать характер задачи и специфику исходных данных на разных этапах вычислений. Программист может задать схему запараллеливания для данных для любого процесса или всей вычислительной задачи в целом. После того как программист задаст базовые параметры, DataRush сам реализует вычисления. DataRush работает в рамках JVM (Java Virtual Machine).
При использовании Hadoop программист должен хорошо представлять, как работает MapReduce и HDFS, но ему не нужно заботиться о распараллеливании.

Рис. 5. Разделение данных и процессов
Подход к распараллеливанию в DataRush начинается на уровне программных тредов. Программа может иметь несколько тредов и в пределах одного ядра. Нужно помнить, что ядро может в любой момент времени обслуживать только один тред, при этом тред может "повисать", когда программа ждет получения того или иного ресурса. Переключение исполнения с одного треда на другой сопряжено с изменением контекста, а это требует времени. На рис. 6 этот процесс проиллюстрирован в упрощенном виде. Здесь имеется 4 ядра с разным числом исполняемых тредов в каждом (3,2,4,2). Эффективное управление такой системой со стороны программиста практически не реально. Эту задачу решает DataRush, при этом в процессе управления он может учитывать то, где находятся данные, подлежащие обработке. Нужно учитывать, что разные приложения и треды используют часто одно и то же пространство памяти. С учетом тенденции роста числа процессоров и ядер в одном сервере (в 2010 году их число достигает 48), а также объема оперативной и виртуальной памяти эксплуатационные характеристики DataRush только улучшаются.
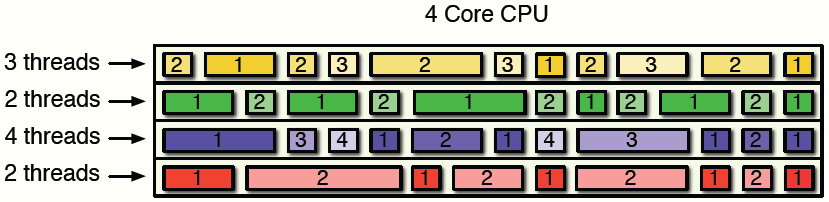
Рис. 6. Переплетение тредов
На рис. 7 представлены типичные применения DataRush и Hadoop/MapReduce. По горизонтальной оси отложен объем данных в логарифмическом масштабе (от мегабайт до экзабайт). В настоящее время корпоративные базы данных имею объем менее терабайта. Тенденция же роста объема данных самоочевидна. По вертикальной оси отложена сложность задач. В верхней части рисунка размещены задачи типа моделирования климата, анализ сейсмических данных, гидродинамика и физика элементарных частиц.
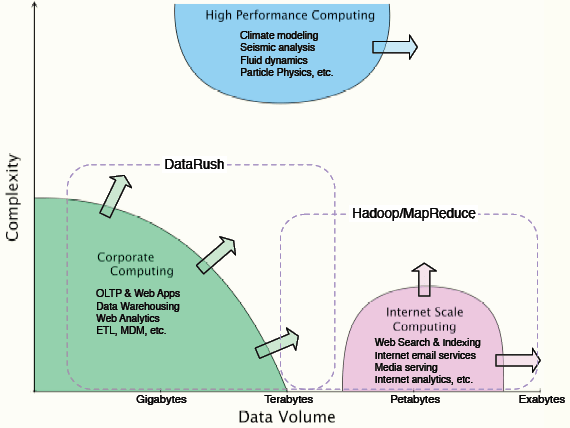
Рис. 7. Карта приложений с учетом сложности и объема данных
Задачи оптимизации для каждого класса задач решается независимо.
Возникает вопрос, станут ли параллельные вычисления нормой? Здесь нужно учитывать то, что существует огромное число программ, которые могут исполняться только на одном процессоре. В то же время разработаны и продолжают разрабатываться ОС, которые позволяют исполнять традиционные "старые" программы на многоядерных серверах, при этом достигается существенное ускорение их исполнения. C учетом сложившихся технологических ограничений следует признать, что параллельным вычислениям в перспективе нет альтернативы.
Анализ использования параллельных вычислений в бизнесе, где требований к быстродействию на первый взгляд ограничены, также показывает преимущества использования параллельных технологий.
Previous: 4.7.7 Унифицированные коммуникации (UC)
UP:
4.7 Прикладные сети Интернет |




